

看懂 “世纪围棋大战”,先温习这篇关于围棋和人工智能的知识帖
明天将会有一场必定载入史册的比赛——AlphaGo V.S. 李世石,可能有些男朋友们已经开始琢磨:
我不懂围棋,人工智能这种高概念领域也只是略有听闻。明天女朋友问起来 “围棋怎么下?”、“ AlphaGo 下围棋的原理?”、“李世石是谁?” 这些问题时,哑口无言多丢人啊!
别慌!
我们爱范儿明天中午 12 点的直播力求通俗易懂,早早就找来了围棋和人工智能专家进行现场解说。只要你愿意看,我们就能让你看得懂。

当然了,我们的专家解说团队不可能在直播时对每一个围棋和人工智能概念进行细致的解释。因此,我们特意准备了一篇女朋友也能看得懂的知识贴。
好了,我们先看看对战双方究竟是什么来头吧。
虽然李世石很厉害,但 AlphaGo 有高科技啊
李世石
不关注围棋的人可能不知道李世石。李世石是围棋专业九段棋手,这个段位已是专业围棋棋手中的最高级别。
当然,李世石厉害不在于他的段位,而是他能长年保持一流的水准。自 2002 年加冕富士通杯以来,他 10 年时间里共获 14 个世界冠军,是最近 10 年中获得世界第一头衔最多的棋手,公认的围棋传奇。
反正,知道李世石下围棋的水平在人类中数一数二就是了,并且他总能在最后一刻反败为胜。
AlphaGo
AlphaGo 是 Google 研发一个计算机程序,说得高大上点,就是围棋 AI(人工智能)。
AlphaGo 于 2015 年 10 月份战胜了职业二段樊麾。这句描述看起来不起眼,可这是围棋 AI 第一次在没有让子的情况下战胜职业围棋选手。至于它是怎么做到的,我们后面再告诉你。
总而言之,李世石对战 AlphaGo 是人类智力代表和高科技拼个高低,很多媒体都渲染成了 “捍卫人类尊严之战” 。

看完对战双方,我们来看看围棋究竟是怎么下的。
围棋的一点小知识
围棋采用黑白两色棋子在方形棋盘上进行,这个应该没有人不知道吧。
职业围棋赛通常采用 19×19 路棋盘,棋局在空棋盘上开始,对战双方力求在棋局结束时比对手控制更多的地域。
贴目
“目” 指在棋盘上的棋子所占有的交叉点。
比赛开始,执黑子一方先行。这样黑子一方就会有优势,为了消除黑方的先行优势、尽可能使黑白双方胜率一致,在终局计算胜负时黑方需要贴目。为避免和棋, 贴目的目数通常包括半目。
这次 AlphaGo 和李世石的比赛采用贴 7.5 目的中国规则,也就是说,在计算胜负时黑子贴 7.5 目给白子。至于为什么是中国规则,业内专家猜测是编程非常方便。
吃子
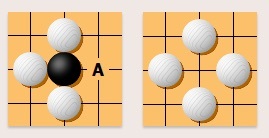
被完全包围的棋子将被吃掉并从棋盘上移走。比如,白棋可以下在 A 位吃掉黑子。
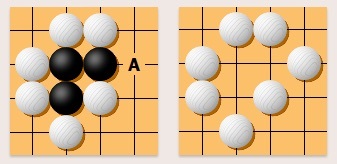
垂直或水平相连的棋子可作为整体被吃掉。比如白棋下在 A 位可吃掉三个黑子。
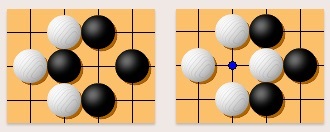
劫
不能同型重复:劫的规则禁止对局双方反复提劫而形成同型重复。对手提劫后, 你不能马上提回来。但是你可以在棋盘其他地方下子后再提回。也就是说你可以找劫材,对手应劫后你可以再把劫提回来。
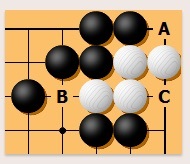
气
气是与一块棋相邻的交叉点。比如下面白棋在 A、B 和 C 处有三口气。一块棋没有气会被提掉。一块棋只有一口气称为 “叫吃”。
计算结果
棋局结束时有两种计算胜负的方法:
- 数子法计算围取的地域,即双方占领的交叉点的数目。
- 数目法计算双方围取的目数, 包括死子。
如果双方手数相同, 两种计算方法结果相同。
AlphaGo 是怎么下围棋的?
AlphaGO 以大量的棋谱数据为基础进行深度学习,不断完善,又通过自我模拟比赛提高实力。背后涉及到三个主要概念:穷举、蒙特卡罗树搜索和深度学习。
穷举
面对任何棋类,AI 一种直观又偷懒的思路是穷举所有能赢的方案。
穷举,是一种数学计算方法,根据部分条件确定答案的大致范围,并在此范围内对所有可能的情况逐一验证,直到全部情况验证完毕。
比如,穷举应用在密码学上被称为暴力破解法。密码如果只有 1 位数字,穷举最多 10 次:1, 2, 3, 4, 5, 6, 7, 8, 9, 0。2 位数字的密码,穷举最多 100 次就能破解。
蒙特卡罗树搜索
穷举的方案会形成一个树形地图,为计算机围棋博弈而发明的树形地图叫作蒙特卡罗树搜索(Monte Carlo Tree Search,简称 MCTS)。大致的原理是:通过统计大量的蒙特卡罗抽样结果,来选择较好的走法。
蒙特卡罗算法是对一类随机算法的特性的概括,它诞生于上个世纪 40 年代美国的 “ 曼哈顿计划”,名字来源于赌城蒙特卡罗,象征着 “概率”。
知乎用户苏椰举了个例子帮助我们理解蒙特卡罗算法:
假如筐里有 100 个苹果,让我每次闭眼拿 1 个,挑出最大的。于是我随机拿 1 个,再随机拿 1 个跟它比,留下大的,再随机拿 1 个…… 我每拿一次,留下的苹果都至少不比上次的小。拿的次数越多,挑出的苹果就越大,但我除非拿 100 次,否则无法肯定挑出了最大的。这个挑苹果的算法,就属于蒙特卡罗算法——尽量找好的,但不保证是最好的。
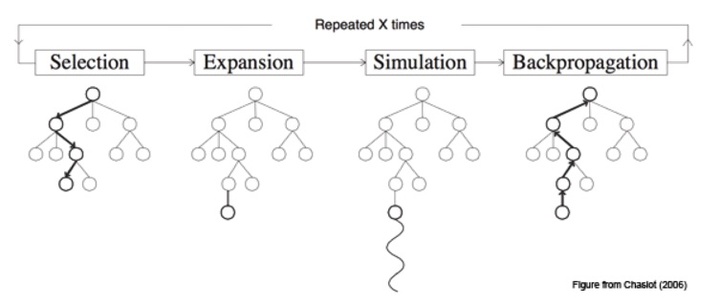
(蒙特卡罗树搜索算法的构建过程)
然而,围棋实在太复杂了。国际象棋中,平均每回合有 35 种可能,一盘棋可以有 80 回合;而围棋每回合有 250 种可能,一盘棋可以长达 150 回合。
国际象棋 AI 可以通过穷举法战胜人类,而围棋 AI 只依靠蒙特卡罗树搜索进行穷举法的话,效率非常慢。
深度学习
AlphaGo 加入了 “深度学习” 技术,设法减少需要穷举的数量。
深度学习是机器学习的一个分支。机器学习这个概念认为,对于待解问题,无需编写任何专门的程序代码,只需要输入数据,算法会在数据之上建立起它自己的逻辑。
深度学习强调的是使用的模型,譬如推出不足半年就获得超过 1 亿用户的 Google Photos,用到的就是卷积神经网络模型。
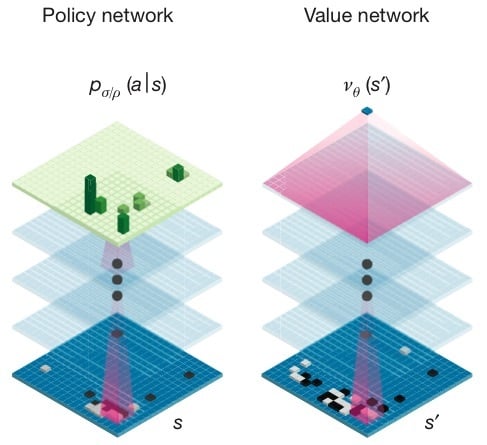
AlphaGo 利用到了两个深度学习网络模型,想必大家在不少媒体上都看到过,分别是策略网络(Policy Network)和价值网络(Value Network)。
简而言之,策略网络可以理解为走棋网络,着眼于当下,预测 / 采样下一步的走棋。价值网络思考得更加长远,预测棋局的走向。
看完上面的知识贴后,如果你还想知道 AlphaGo 和人类棋手的区别,来看看田渊栋下面这段话。田渊栋是 Facebook 人工智能组的研究员,他在知乎上的回答被不少媒体引用过:
职业棋手可以在看过了寥寥几局之后明白对手的风格并采取相应策略,一位资深游戏玩家也可以在玩一个新游戏几次后很快上手,但到目前为止,人工智能系统要达到人类水平,还是需要大量样本的训练的。
可以说,没有千年来众多棋手在围棋上的积累,就没有围棋 AI 的今天。
文中棋盘插图来自:SmartGo
本文参考文章:
5 天后大战人工智能!世界顶尖棋手能否 “捍卫” 人类智商?
附:AlphaGo 对围棋冠军李世石预告视频
直播预告:
明天中午 12 点,决战就将开幕,爱范儿届时也将为你全程直播。同时我们还找来了围棋和人工智能专家进行现场解说。只要关注爱范儿,你就能够获得第一手的决赛信息。
人类历史上的最后一次 “深蓝” 大战?!3 月 9 日 – 15 日,Google 出品的人工智能 AlphaGo 将迎战目前世界最顶尖围棋选手之一的李世石(韩国)。究竟人类能否在 5 场比赛中守住最后的尊严?爱范儿为你邀请了多位围棋界顶尖棋手、人工智能领域专家进行全程跟踪和报道,敬请持续关注。







