






多亏李世石的不懈努力,AlphaGo 的命门终被发现?
本文原文作者陈经,香港科技大学计算机科学硕士,中国科学技术大学科技与战略风云学会研究员,新浪围棋 6D。本文首发于“观察者”,原标题为“陈经:在 AlphaGo 完胜后继续分析其算法巨大优势与可能的缺陷”,已获得作者同意转载。
2016 年 3 月 13 日,人机大战第四局李世石执白 180 手中盘胜 AlphaGo。说这一胜是人类历史上最重要的一胜也不为过,就不多说了。从围棋技术与算法上来说,最重要的意义是,我们终于看到了一张 AlphaGo 的败局谱,明确知道 AlphaGo 有重大 bug,前三局过后看似威力无比的机器,发起疯狗症竟然会走出那么可笑的招法。
现在终于知道,为什么谷歌只公布了与樊麾的五盘正式对局的棋谱,却不公布非正式对局里二盘败局的棋谱。哪怕一盘败局的全谱泄露出来,人类稍作调查就会知道如何对付它。李世石接到谷歌的邀请,只考虑 3 分钟没提什么条件就应战了。从人类与机器斗争的角度看,这真不折不扣是《三体》中描述的有碍于人类生存的 “傲慢”。不夸张地说,只要李世石要求谷歌公布一张 AlphaGo 的败局谱,这次人机大战的胜利者就非常可能改写。但也不能怪李世石,估计所有职业棋手都想不到,这是人类的共性。我们要感谢李世石,终于用生命一般的抗争在第四局逼出了真相。
1996 年国际象棋第一次人机大战,卡斯帕罗夫就谨慎得多。他提出先由助手和 IBM 的机器下测试棋,正式比赛时卡斯帕罗夫以 4:2 获胜。这是因为国际象棋程序当时已经发展多年,显示了不低的实力。而围棋程序也是发展了多年,虽然取得了几次重大进步,人的感觉仍然是职业棋手让五六子的水平。樊麾的失利是一个重要信 号,但从人类情绪来看,越是不懂围棋技术的人越敢预测机器的胜利。棋迷与职业棋手更了解自己这边的 “强大实力”,更了解围棋作为一个算法问题的复杂度,傲慢没有减少。
第四局李世石获胜的关键,赛前我就在上一篇文章中作出了非常接近实战进程的预测:开放式接触战,利用机器 “不喜欢打劫” 的特性,让机器犯昏。
李世石这第 78 手在人类看来,其实还是有漏洞的,仔细拆解会发现这并不是最佳着手,黑棋应对了白不行。但是这招非常神奇地引发了机器的 bug。为什么会有 bug,难有定论,我认为最可能是 AlphaGo 的价值网络出问题了。(观察者注:关于 AlphaGo 的价值网络,田渊栋的这篇《AlphaGo 的分析》做了很好的科普,作者为前谷歌工程师,Facebook 智能围棋 darkforest 的负责人和第一作者)
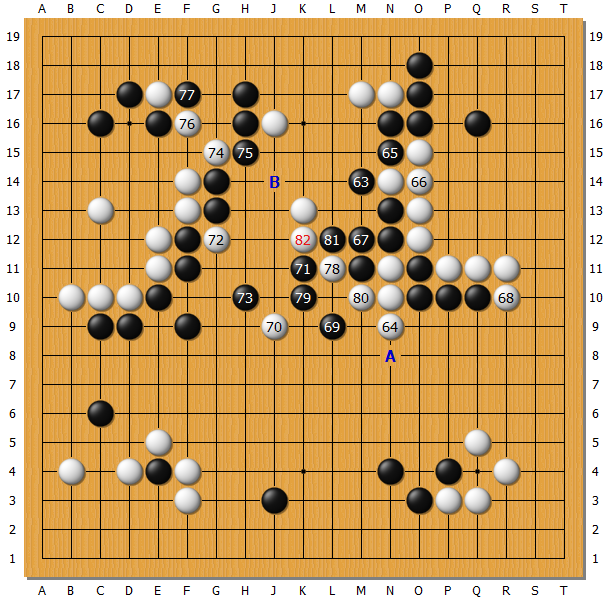
如图至第 82 手。80 和 82 都是必然的,所以叫 78 为神之一手。其实 AlphaGo 这时走 B 位,据职业棋手分析,空里没有什么棋。如果白 M13 扑,黑可以 提掉 78 一子,白 L13 再打吃,黑粘在 78 位。下面白吃不掉 63 这个子。对人来说变化并不复杂。观战棋手猜测李世石预想的变化图是这样的:
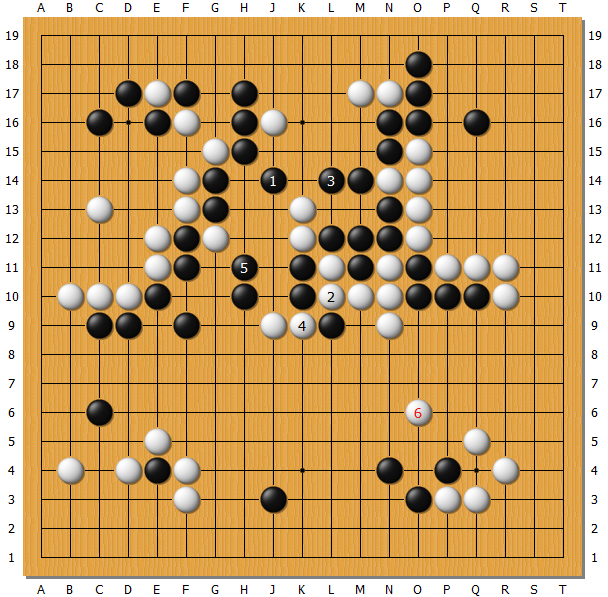
如果 AlphaGo 走 1 位,那白只好 2 位先手接回一子,再 4 位先手切断,在外面做出一片形势,局势还能维持。
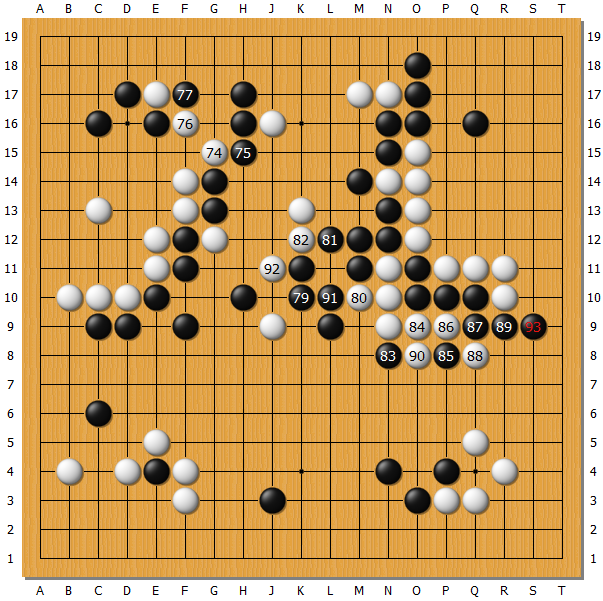
而 AlphaGo 却走了实战的 83 手,后面一连串招法都特别糊涂的样。所以犯错是从 83 手开始的。Deepmind 负责人哈萨比斯说从 79 到 85 手,机器都以为自己胜率高达 70%,到第 87 手才发现不对劲,一步棋评分就急剧下降了。降到多少没有说,但肯定是个很低的分,所以才后面一连串搞笑的棋。这些搞笑的棋本身到是不难解释,为了偷得可怜的一点胜率,它觉得别的招都不如你打吃看不见。Zen 之类的 MCTS 程序落后了乱下很常见。我们要解释,为什么 AlphaGo 下了错误的 83。
这个局面特别复杂,把整个棋盘中间都卷进去了,可以说根本不是地块划分的问题。决定性因素就是怎么出棋,出多大的棋,出劫的话怎么造对自己有利的劫。从 AlphaGo 的算法来看,它会从当前这个局面进行搜索展开,对叶子节点给出判断。一半是靠价值网络,一半是靠 “快速走子策略” 走到终局。
价值网络的意思是,它静态地看整个盘面,用一个多层的神经网络直接算,就报告这个局面谁会胜。虽然它能 “深度学习” 到很多隐藏的概念,我们很难想象,在一个火药桶一样的盘面上,一个静态的不搜索的神经网络居然可以判断清楚最终的胜负。这种复杂局面,我断定价值网络的判断误差是极大的。也许价值网络在各种叶子节点粗粗地一看,黑棋在中间以多打少似乎应该是形势一片大好。这应该不难理解,无论谷歌怎么拿几亿个局面训练价值网络,我也不相信它能判断清楚。
那么 AlphaGo 在叶子节点还有一半的机会,就是 “快速走子” 你一招我一招不停直到终局。这个快速走子策略的实力还不错,速度比策略网络快 1000 倍的情况下,单只靠这个策略就有 KGS 的 3D 实力,做得其实很好了。但我们再想想,这么复杂的盘面,两个 KGS 的 3D 在那下到终局,你信得过它们的模拟质量?黑死还是白死估计就是随机的了。如果让两个真实的人类 3D 在这个局面下,黑好白好确实可能等于扔硬币。
如果 “快速走子终局” 给的结果是随机,基本就是价值网络在那主导判断了。它要是有系统性的错误偏向,误以为黑形势一片大好,那可能一大堆叶子节点都有类似错误,因为盘面很相似。所以综合起来,AlphaGo 的 MCTS 模块,让价值网络在那高兴,下了 83 和 85 还是继续高兴,胜率还是 70%。终于在白下了 86,黑 87 后,价值网络发生了“跳变”,这里出现了棋块特征的本质变化,一大片类似叶子节点的价值网络判断都倒转过来,于是只一手,胜率就从 70% 跳到 30% 之类的悲惨数字了。
这是我的猜测,只能尽量地往合理上靠,最终如何希望 Deepmind 能给出分析。但是显然,复杂的对杀盘面会对价值网络造成严重困扰,这应该是 AlphaGo 体系架构中一个不太好消除的命门。同时复杂的对杀盘面,又让 “快速走子策略” 模仿精度下降。要是两个 3D 在那下和平棋终局,你占 10 目我占 9 目,错进错出最后一平均是可能把局面好坏概率性模拟清楚。但要是 50-50% 机会的大对杀,就和其它地方无关了,模拟到最后也提供不了什么有效信息。
AlphaGo 搜索中的两个武器都失灵了,就只有依靠 “策略网络” 提供的各个候选点的概率了。同样的原因,这个策略网络只是一个静态评估,复杂盘面各处头绪很多,各种要点多得是,看上去的好点到处都是。我不相信策略网络就那么凑巧对真正的好点给出高的概率。
可以非常合理的认为,对于复杂的、头绪很多的对杀盘面,AlphaGo 所有的搜索武器都会失灵,容易做出错误选择!三大搜索武器 “策略网络”、“价值网络”、“快速走子终局数子”,全都失灵!(观察者注:关于 AlphaGo 三大利器,田渊栋的这篇《AlphaGo 的分析》做了很好的科普,作者为前谷歌工程师,Facebook 智能围棋 darkforest 的负责人和第一作者)
都失灵了,不管你怎么调参数拼凑一个 MCTS 架构,最后也还是失灵。这就是 AlphaGo 的命门!
让我们人类开心的是,这并不是很难实现的!我和 Zen 下过,水平不够怎么也下不过它。要么局部被它杀死,要么圈地大局观搞不过。但是下多了,慢慢也琢磨出来了办法。就不要怕它,这里开一片头绪,那里开一片,留着不动。然后各种头绪慢慢凑一起,这里的选择会影响那里。这种情况下 Zen 就昏了,它的搜索武器其实比 AlphaGo 更差,更是全都失灵了。我虽然也昏,但就死盯着某一个 “阴谋”,设计一条路线图就够了,不去搜索那么多乱七八糟的。最后哈哈,Zen 上当了,我阴谋得逞,吃了一大片终于赢了。其实我的水平真的远不如 Zen,各个局面手段和大局明显不如。
那么对李世石这样的职业高手来说,复杂盘面更不是个事了。职业高手能理清楚复杂盘面的推理逻辑,用清楚的变化图给出杀招。这正是体现大高手水平的地方。
因此我大胆推测,AlphaGo 其实没有那么可怕。所有 MCTS 为基础的程序都有的大漏洞,它一样有,而且从算法角度没有什么好办法解决!这是算法原理决定的,不是写程序代码错了几行的小 bug。
如果职业高手们了解了 AlphaGo 的漏洞,就不要客气搞什么棋理圈地,直接就上去跟它杀!但不要在局部乱杀,不是说 “在此决一胜负”,如李世石第一局开始的杀法,不对。要这里留点味道,那里留些头绪,最后这些乱子凑到一起去,一定把 AlphaGo 弄昏头。
因此,除了 “不喜欢打劫” 以外,AlphaGo 还不喜欢复杂的盘面。所以前三局中它表现得特别喜欢定型,有手段就使出来,减少头绪。这是它的搜索特性决定的。
分析清楚以后就可以肯定,AlphaGo 的漏洞不小。开始人类不了解它,看它下得象模象样,还时不时有好招,被它吓到了,没有找到它的命门。它是有几招绝活玩得不错,封闭局面算得不错,圈地运动搞得不错,几百万次算到终局去人不可能玩得过。选点也很靠谱,算得快算得准。在它擅长的领域和它打,当然就不是对手,哪怕是人类最高水平的也不行。但复杂盘面是人类的天生优势,这不是 MCTS 那几招搞得定的,需要人类高手制造头绪归纳头绪的逻辑能力。
AlphaGo 的缺陷被测试出来以后,人类高手将可能对机器取得压倒性的胜利。当然人类高手需要改变下法,不要和自己人下那样讲棋理数着目下。碰到机器就要搅,越复杂越好。不是一处变化多手数多那种复杂,而是搅出的头绪越多越好。
这还没有提到打劫的能力,这更是人类高手胜过机器的地方。机器可以用控制流避开劫争,但这终究不是办法。如果人想通了,自己不要虚,大胆引入劫争分支,机器总是避劫原理上就不合于棋道。当然这个分析起来更复杂。
综上所述,如果高水平围棋程序还是基于 MCTS 架构的,都会有难以解决的大缺陷。我对人类高手一段时间内压制机器充满信心!
人类历史上的最后一次“深蓝”大战?!3 月 9 日- 15 日,Google 出品的人工智能 AlphaGo 将迎战目前世界最顶尖围棋选手之一的李世石(韩国)。究竟人类能否在 5 场比赛中守住最后的尊严?爱范儿为你邀请了多位围棋界顶尖棋手、人工智能领域专家进行全程跟踪和报道,敬请持续关注!
首图来自 《武林外传》





