互联网人必须要懂的 “幸存者偏差”
本文授权转自公众号“卫夕聊广告”(ID:weixiads)。
不管你是否听过这个词,这篇文章都会让你对 “幸存者偏差” 理解的更加深刻,先让我们来看几个段子:
- 学校组织郊游,老师问:没来的同学举个手,好,人齐了,我们出发吧!
- 央视记者在一辆高铁上问:您买到票了吗?买到了!您呢,您买到了票了吗?买到了!
- 妈妈为什么不挑食?因为她买菜的时候已经挑过了!
- 降落伞的电商店铺为什么都是好评?因降落伞有问题而失事的人想给差评也给不了!
这些都是关于幸存者偏差的段子,大家看完都哈哈大笑,是因为我们都太容易识别它了,然而我列出下面的案例,我们可能未必能得出正确的结论了:
- 1936 年,美国总统大选,《文学文摘》杂志通过 140 万人的电话调研显示兰登会赢得大选,这个调研有多大的可信度?
- 在古埃及的文物中发现了莎草纸,而在同期其他地中海文明如腓尼基、古希腊、古罗马则没有发现莎草纸,能否说明该时期莎草纸在埃及应用广泛而在其他地中海文明则没有应用?
- 某新游戏上线一个月,游戏策划随机找了游戏中高度活跃用户进行调研,确定了游戏下一步迭代的核心方案,会不会存在致命缺陷?
- 某记者在网上搜出 “民国小学生作文”,文采极好,于是记者总结道:现在的小学语文教育和民国时没法比啊!
事实上,以上的案例都极有可能得出错误的结论:
- 1936 年美国大选的调查,由于是电话调查,而电话在 30 年代的美国还是富人的专利,而这些富人并非美国选民的随机样本,最终罗斯福而不是杂志预测的兰登当选。
- 古埃及的发现了莎草纸而其他地方没有,真实原因是其他三个地方——腓尼基、古希腊、古罗马气候比古埃湿润,而埃及则比较干燥,而这些莎草纸在潮湿环境中并没有保存下来。
- 新游戏上线一个月,有留存用户,也有流失用户,关注留存用户需求固然重要,但对于一个新游戏而言更重要的是关注那些流失用户的流失原因。
- 民国小学生作文之所以能流传到今天,必然是当时就是佼佼者,它是幸存者,代表不了当时民国小学生的整体水平。
在我们日常工作的决策中,幸存者偏差是如此普遍,常常在不经意中影响我们的决策与判断,那么这个概念的本质是神马?它容易在哪些情况下发生?它的作用机制是怎样的?我们如何避免它?今天的文章我们就一起来探讨一下这个问题:
“幸存者偏差” 的历史
“幸存者偏差” 来源于二战中一个著名的故事:
1941 年,第二次世界大战中,空军是最重要的兵种之一,盟军的战机在多次空战中损失严重,无数次被纳粹炮火击落,盟军总部秘密邀请了一些物理学家、数学家以及统计学家组成了一个小组,专门研究 “如何减少空军被击落概率” 的问题。
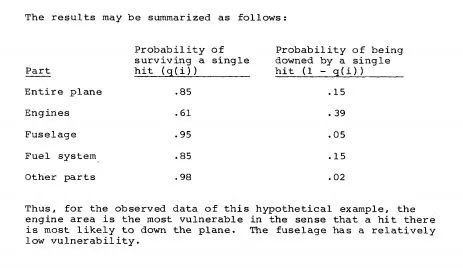
当时军方的高层统计了所有返回的飞机的中弹情况——发现飞机的机翼部分中弹较为密集,而机身和机尾部分则中弹较为稀疏,于是当时的盟军高层的建议是:加强机翼部分的防护。

但这一建议被小组中的一位来自哥伦比亚大学的统计学教授——沃德(Abraham Wald)驳回了,沃德教授提出了完全相反的观点——加强机身和机尾部分的防护。
那么这位统计学家是如何得出这一看似不够符合常识的结论的呢?沃德教授的基本出发点基于三个事实是:
- 统计的样本只是平安返回的战机。
- 被多次击中机翼的飞机,似乎还是能够安全返航。
- 而在机身机尾的位置,很少发现弹孔的原因并非真的不会中弹,而是一旦中弹,其安全返航的机率极小,即返回的飞机是幸存者,仅仅依靠幸存者做出判断是不科学的,那些被忽视了的非幸存者才是关键,他们根本没有回来!
军方采用了教授的建议,加强了机尾和机身的防护,并且后来证实该决策是无比正确的,盟军战机的击落率大大降低,这就是 “幸存者偏差” 故事的来源。
“幸存者偏差” 的本质
广义的幸存者偏差用统计学的专业术语来解释是——“选择偏倚”,即我们在进行统计的时候忽略了样本的随机性和全面性,用局部样本代替了总体随机样本,从而对总体的描述出现偏倚。
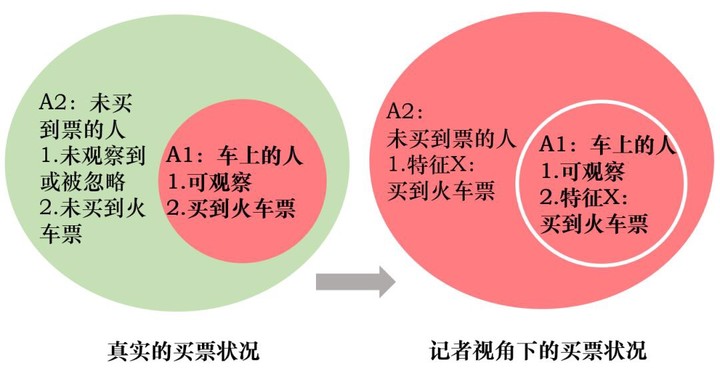
统计学的简单描述是这样的:统计全集为 A,观察到 A 的子集 A1 有特征 X,A1 为幸存者,而 A 另外的子集 A2 并没有观察到或者被人为忽略,于是判断全集 A 都有特征 X,事实上 A2 的特征为 Y。

用上述记者调查买火车票的案例来代入解释为:A 为全体想买火车票的人,A1 为已经在火车上的人,A2 为想买但没买到的人,特征 X 为买到票,特征 Y 为未买到票,即幸存者偏差将一小部分显性样本代替了随机样本,从而导致了统计的偏差。
有了这个框架,我们就能从理论的角度理解这些 “幸存者偏差” 的具体案例了:
- 亚裔学生案例
美国学生会发现亚裔同学在数学方面要超出其同龄孩子很多——“幸存者偏差”:能到美国上学的孩子在中国的教育水平和成长环境通常都会相对优越,要是中国的母语是英文,想必语文成绩也会优于美国同龄学生。
- 住院研究案例
假如北京长庚医院对心脏病人住院病人的饮食习惯进行研究,从而发表一篇《心脏病与饮食习惯之间的关系》的论文,该论文是否有可信度?答案是没有!因为长庚医院为北京高端私立医院,该院病人和普通病人的饮食习惯会存在差异,同时住院的病人也并非能代表所有病例(不住院就已经去世的、住不起院的等等),事实上,排除这些干扰因素是现代医学研究的基本准则。
- 健身房案例
我每周一三五中午都会去公司的健身房,这个习惯坚持了很长一段时间,然而有一段时间我一度沮丧——因为我发现公司健身房的同事基本上身材都比我好,这其实就是典型的 “幸存者偏差”——那些健身房的人身材好当然是大概率事件,身材不好也不锻炼的人通常很少去健身房。
- 章鱼保罗案例
2010 年世界杯最大的明星不是来自某个球员,而是来自德国奥博豪森海洋馆的章鱼” 保罗 “,它神奇地连续 7 次百发百中地预测了世界杯德国队的比赛结果,章鱼保罗成为那个夏天世界媒体热情追逐的对象,然而事实上它就是一次典型的” 幸存者偏差 “,那年夏天其实有很多动物都参与了世界杯的预测:菲律宾的猴子、墨西哥的羊驼、非洲的大象、保加利亚的奶牛甚至还有中国的熊猫,只是因为这些动物预测失败了于是并没有媒体报道,而章鱼保罗成为那个幸运儿。

在以上四个案例中,全集 A 分别为:中国的所有孩子、所有心脏病患者、我公司的所有同事、预测世界杯的所有动物;
幸存者 A1 分别为:有条件去美国念书的孩子、在长庚医院的心脏患者、去健身房的同事、章鱼保罗;
特征 X 分别为:数学好、饮食独特、身材好、预测准;
特征 Y 分别为:数学平庸、饮食正常、身材一般、预测不准。
这就是 “幸存者偏差” 的分析框架。
警惕 “幸存者偏差” 的滥用
很多人对 “幸存者偏差” 这个名词一知半解的时候,往往会造成它的滥用,在作者看来,警惕 “幸存者偏差” 和警惕 “幸存者偏差” 的滥用同样重要。
很多人看到一些媒体报道的创业 “成功故事” 立马嗤之以鼻——“这是幸存者偏差,不知道有多少个失败的案例呢?”,然后对成功者的方法和经验一概摒弃;
很多行贿的工作人员看到 “某人行贿被抓” 的新闻见怪不怪,认为这是幸存者偏差——“媒体只会报道那些行贿被抓的人,其实还有更多没抓住呢!” 于是他们继续行贿。
那么 “幸存者偏差” 这个概念是如何被滥用的呢?还是举记者调查高铁买票的例子,明白 “幸存者偏差” 理论,只能让我们明白——”记者在高铁上进行调查来判断所有人都买到票” 这种方法是不科学的。
注意——它并不能直接推断出 “所有人都买到票” 这个结论一定是错的,因为剩下的人有没有买到票这一信息——我们不知道:春运的时候我们能根据常识判断他们可能买不到票,但平时的高铁,基本上是想买到票的人都能买到票,因此,直接判断 “肯定有人没买到票” 就属于 “幸存者偏差” 的滥用,错误的反面不一定就是正确。
从统计学的角度我们来看我们是如何滥用幸存者偏差的——我们观察到了 A1 有特征 X,同时我们意识到可能存在幸存者偏差,我们预先把 A1 定义为幸存者,于是直接判断非幸存者 A2 一定不会有特征 X,而真相是:A2 是否有特征 X 这个信息我们并不知道,可能有,也可能没有。
警惕 “幸存者偏差” 滥用非常重要,事实上前面提到的二战统计学教授沃德的故事也只是后人及其简化之后的版本,稍微思考一下就会知道,一个受过科学训练的统计学教授是不可能只凭直观判断就直接给出结论的。
事实上沃德教授关于飞机击落问题先后提交了八份不同方面的报告,其中主论文为《A Method of Estimating Plane Vulnerability Based on Damage of Survivors》,即《一种根据幸存飞机损伤情况推测飞机要害部位的方法》。
这篇论文就有 80 多页,仅后人对他贡献的综述就有 10 多页,(公众号回复关键词——“沃德教授” 获取论文),这位写过巨著《序列分析》的权威教授显然是对框架中 A2 的特征做过详细而严谨的分析才得出结论滴!
如果拍拍脑袋就能成为统计学家,那大家都是统计学家!
互联网人如何避免 “幸存者偏差”?
“幸存者偏差” 是数据分析的常见逻辑错误,而数据又是驱动互联网的动力之一,那么互联网人应该在分析数据、决策判断时如何避免 “幸存者偏差” 的存在呢?卫夕总结了三个步骤:
- 判断样本的随机性,即必须知道样本是否是随机的。
- 判断样本和剩余样本中会不会存在显著差异。
- 分析剩余样本数据,验证结论。
我们来看几个案例直接进行训练:
- 微信公众号打赏案例
“卫夕聊广告” 既开通了公众号也开通了微博账号 “卫夕君”,这时候我发现同一篇文章在相同的阅读的情况下微信的打赏特别少,而微博则多一些,因此我起初大致判断微信粉丝的打赏意愿低于微博,直到我想起来微信的 iOS 用户由于苹果的政策限制目前并不能打赏之后才明白我之前的猜想是错滴,这存在幸存者偏差,于是我尝试在最近的两篇文章末尾专门加上 IOS 赞赏码,文章的赞赏金额果然提升了接近 4 倍。
在这个案例中避免幸存者偏差的标准三步为:
判断样本的随机性,即看微信公众号的打赏用户是否能代表整体?答案是否定的,因为只覆盖了安卓用户;
判断样本和剩余样本会不会存在显著差异?即安卓用户和 iOS 在打赏这件事上会不会存在差异?答案是:可能存在差异;
分析剩余样本数据,验证结论,即加上 iOS 的打赏码再次验证结果。
- 视频网站案例
某视频网站在 VIP 中新上线了一部美剧,该美剧每一集的观看人数之前一直稳定,但当它播到第七集的时候,观看人数有一个相对明显的流失,运营人员开始分析认为是该部美剧从第七集开始剧情急转直下主角忽然挂掉引起的,然而当他们仔细分析流失用户的时候,发现流失的都是因为三个月前某次大规模赠送的免费会员到期引起的,只是时间正好和第七集重合而已,普通会员根本没有流失。
在这个案例中三步分别为:1. 判断样本随机性,即分析流失用户是不是所有会员的随机样本。答案是否定的——流失的都是免费会员。2. 判断样本和剩余样本会不会存在显著差异?即正常会员和免费会员有没有差异?当然有。3. 分析剩余样本数据,验证结论,即看正常会员是否流失。
- Facebook 视频广告案例
2016 年 9 月年 Facebook 关于视频广告数据偏差的问题变成了该公司广告历史上不大不小的负面新闻,Facebook 在其官方博客中承认:其提交给广告主的数据报告中,视频广告平均播放时长的数字只统计了那些播放时长超过 3 秒的播放行为,也就是说,如果视频播放没超过 3 秒,Facebook 居然就把它舍去了,很显然,广告主的平均播放时长被拉长了,因为播放时间短的压根不统计,而这一偏差居然存在了长达两年之久。
这个案例中,分析依然分为三步:1. 判断样本随机性——废话!3 秒以下的都舍去了!当然没有随机性!2. 判断样本和剩余样本是否存在显著差异?废话,3 秒以下和 3 秒以上肯定有差异!3. 分析剩余样本数据、验证结论。这….. 就不用验证了吧!
以上的分析前提是我们需要对我们的业务进行深刻的理解,只有你深刻理解了你业务中具体重要的影响因素你才能做出正确的猜想和判断。
好了:以上就从理论到实践的角度介绍了幸存者偏差,这时候有人会问卫夕,你觉得中文互联网上哪一个平台的内容出现幸存者偏差的概率会比较大?哈哈哈,毫无疑问是知乎!我们来感受一下: