






Google 给搜索引擎加入了一个有「常识」的算法
在阅读英语文章时,最让你挠头的是什么?
遇到一词多意时不知道该选哪个解释?还是长句里难以梳理的信息结构?
Google 搜索引擎其实也跟你一样挠头。
为了「照顾」Google 搜索引擎,很多人在搜索时会用「关键词搜索法(keyword-ese)」—— 只输入关键词,不使用完整的句子。
譬如,有人会在搜索栏里输入「痣」「臀部」「癌症」,其实他想问的是「我屁股上的痣是不是癌症的征兆?」

▲ 图自 Neringa Šidlauskaitė via Unsplash
最近,Google 为搜索引擎引入了一个名为「BERT(Bidirectional Encoder Representations from Transformers)」的机器学习算法,帮助前者更好地理解用户在搜索栏提出的问题。
引擎更新后有什么改变?
简单来说,加入 BERT 后的 Google 搜索引擎,能够更好地理解接近自然对话的长句子,因为它能更好地分析了解句子中单词间的关系。

▲ 图片来自 Unsplash
和传统算法不同的是,BERT 在分析词语时,并不是依次从左到右或从右到左地逐词分析,而是借助 Google 研发的 Transformer 模型并行分析词语在整个句子中的关系。
譬如,如果搜索「math practice books for adults(给成年人的数学练习册)」,更新前的搜索返回结果会将「adults(成年人)」变为「young adults(年轻人)」,更新后则不会这样。
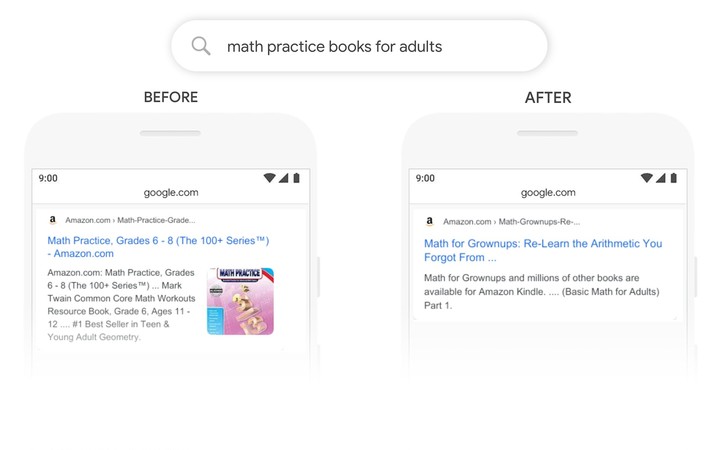
此外,在介词对整个句子意思影响较大的情况下,加入 BERT 后的理解能力也明显优于从前。
搜索「2019 Brazil traveler to usa need a visa(2019 巴西旅客到美国需要签证)」,在更新前,搜索引擎没有将「to」考虑在内,更多返回了美国旅客到巴西旅行的信息。加入 BERT 后,「to」则没有被忽略。
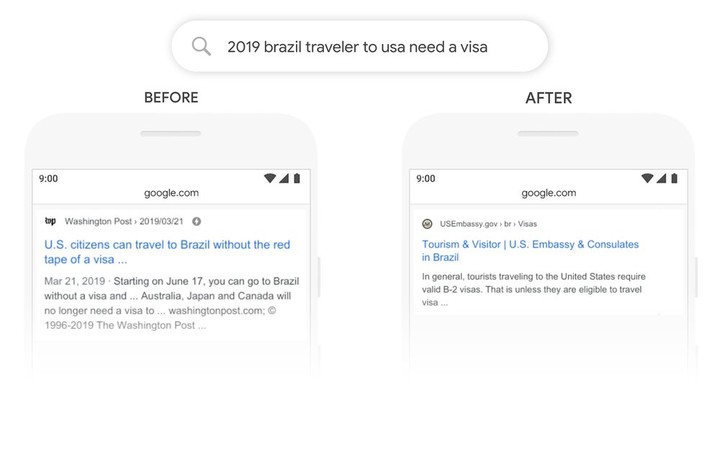
对于这次更新,Google 副总裁 Pandu Nayak 在官方博文中称之为「代表了五年里最大的跨越,也是搜索历史上其中一个最大的改进」。
目前,BERT 已经应用到 Google 搜索的英文版中,未来还将扩展到更多不同语言版本。
BERT 或能让算法更会「聊天」
据《Fastcompany》报道,为了训练 BERT,Google 向其输入了 11038 本未经标注的书籍文本和合计 25 亿字来自维基百科英文版的内容。
而且,研究人员还随机「掩盖」了文本里的单词,让算法模型自行想法子「填空」。
学习完所有文本后,算法开始找到一些在同一文本中经常出现的句子和词语规律,建立了对词语的基本理解,而且还似乎开始「明白」词语背后所代表的事物之间存在的关系,这就像一种「常识」。
举个例子,从前如果在 Google 里搜「do estheticians stand a lot at work(美容师在工作中需要站很久吗)」,搜索引擎会将「stand(站)」这个词语套入「stand-alone(独立)」的意思,因此无法返回搜索者想要的信息。
加入 BERT 后,搜索引擎则能理解,用户所指的是「站立」的动作,再进一步,也可扩大理解为「美容师这个职业的体力劳动量」。

在处理过程中,系统需要表述它所理解的词语意思,还有句子的结构以及整体内容。结果就是,从某个程度来说,它对语言有一定了解。
这挺奇怪的,因为它对现实世界一无所知。它看不到,听不到,什么都没有。
人工智能科学家 Yann LeCun 说道。作为 Facebook 的副总裁,LeCun 带领着团队,通过对 BERT 进行优化,并输入更大批量的学习资料,研发出了他们的自有模型「RoBERTa」。Google 原有的 BERT 准确率为 80.5%,而 RoBERTa 则可做到 88.5%。
但为什么 Facebook 也要研究这个?
如果说当搜索引擎能够更好地理解用户输入的自然语言,反馈更有帮助的内容,那这个改进移植到智能语音助手上也是可预见的。
和很多科技巨头公司一样,Facebook 也在研发智能语音助手,提升算法对自然语言的处理能力也是必须。

▲ Facebook 今年宣布将为 Portal 研发语音助手,图自 Digital Trends
但在语音助手之前,他们先从相对简单的文本对话入手,做了聊天机器人,而且准备在 RoBERTa 的基础上扩展更多功能,让算法和人聊起天来更自然。
据 LeCun 介绍,很多聊天机器人都会「把天聊死」。
譬如,很多机器人讲话会自相矛盾。
前一分钟可能和你说「XXX 的新单太棒了,赶紧一起去打榜」,下一分钟就说「追星的人都是傻的」。这主要是因为它们背后是一个固定的数据库,收到特定的关键词就会调出对应回答。而那些真的是自己生成答案的机器人,又会为了规避自相矛盾而用模糊的答案来回应人,显得冷冰冰。

此外,现有聊天机器人大多知识领域很局限。一旦聊天的人改了话题,聊到它不认识的,机器人就接不下话了。
为此,Facebook 现在正向自己的算法输入来自各种领域的大批量信息,并尝试将这些信息以更自然的方式加入对话中。
未来,他们还计划教导机器人「引导话题」—— 当聊天者将话题扯到比较泛的领域时,将内容拉回到特定任务上。
我们相信,我们已经很接近创造出一个能和人们聊得下去的机器人。
Facebook 研究人员 Jason Weston 告诉《Fastcompany》。在那天到来之前,希望我能练就出不被聊天机器带跑的技能。
题图来自 Engadget





