






揭秘首批中文电脑字体诞生过程,将汉字「搬」进数码设备有多难?
新的电子设备开机时,屏幕映出的首个交互页面,往往是系统语言选择。
你可以上下滑动,选择中文、英文、日文等多达上百种的文字。但如果将时间拨回 40 多年前,这一选项可能只有寥寥几种,而且没有中文。
我国文字的历史源远流长,但其数字化的历程却并不久远。我们现在之所以能在电子设备上阅读中文,离不开最初花费巨大力气,将中文「搬」至电脑上的那一群人。
最近,斯坦福大学获得了 2500 余件现代中国信息技术收藏品,包括几十台珍稀的中文打字机、文字处理器和电脑等物品,堪称世界上最大的中国现代 IT 历史合集。

▲首批中文数字字体模型. 图片来自:斯坦福大学
该校一位研究中国历史的教授托马斯·穆拉尼(Thomas Mullaney),在这些珍贵的藏品里发现了许多有趣的故事。其中就包括全球首批中文数字字体,是如何被制作出来的。
托马斯将这段艰辛但充满艺术的历程,在《麻省理工科技评论》上讲述了出来。我们也得以机会看见这个具有时代意义的历史片段。
▲托马斯·穆拉尼
一台机器带来的契机
故事要从一个订单开始说起。
20 世纪 80 年代初,美国图形艺术研究基金会 (Graphics Arts Research Foundation) 找到了路易斯·罗森布鲁姆(Louis Rosenblum),想请他的团队,为其正在开发的机器 Sinotype III 创建出中文字体。
当时路易斯已年近 6 旬,毕业于麻省理工学院的他,是一名资深的印刷、排版专家。路易斯在 1965 年创立了 Photography Systems 公司,专门解决数字工程、摄影、应用数学等相关问题。

▲路易斯·罗森布鲁姆
虽然路易斯及其团队此前和图形艺术研究基金会有过多次合作,但这次为 Sinotype III 创建中文字体的项目,却是最棘手的。
因为当时中国还没开始生产个人电脑,其他国家或地区生产的电脑无法处理中文。所以在给 Sinotype III 这台实验性机器开发中文字体前,路易斯的团队需要先对苹果二代电脑(Apple II)编程,使其能够以中文运行。

▲Apple II. 图片来自:Wiki
万事开头难。由于苹果二代的 DOS 3.3 操作系统,无法输入和输出汉字文本,所以必须得从头编程,包括编写一个中文文字处理器。为此,其团队花费了几个月的功夫。
他们想出的解决方案,是先通过 BASIC 编程语言,编写一个「Gridmater」程序,然后将该程序放入苹果二代电脑的软盘上运行。如此一来,便能创建并保存汉字的数字位图了。
接着,将设计好的汉字位图及其相应的代码,植入到系统数据库,便可让 Sinotype III 机器处理并显示中文了。

▲Sinotype III 显示器的照片,显示了 Gridmaster 程序和汉字「电」. 图片来自:斯坦福大学
这里插入一个背景知识。早期的数字字体,均采用位图图像(也称点阵图像)来显示。
这是一种常见的储存图像的方式,我们今天相机拍摄的照片、截图,储存方式均属于位图。一张 JPEG、BMP、GIF 等格式的图片,是由很多像素点组成,这些点经过排列和染色,便构成了图样。
比如我们可以在电脑上将一张图片放大,放大至一定程度,便可看到正方形的像素点了。早期的字体便是在一定大小的网格内,通过排列和染色形成的。

▲ 将左图的眼睛部位放大,便可看到像素点了
中文数字字体,可比英文难做多了
中文数字字体之所以难做,首要原因就是汉字的数量实在太多了,其次是因为汉字的字形十分复杂多样。
在计算机问世之初,工程师和设计师约定采用大小为 5X7 的位图网格,来创建低分辨率的英文数字字体。如此一来,每个字符的大小约 5 个字节,计算机的内存不会有太多负担。
在美国信息交换标准代码(ASCII)中储存的所有 128 个低分辨率字符,包括英文字母表中的每个字母、数字 0 到 9,以及常见的标点符号,共计需要 640 字节的内存。而当时苹果二代的内存为 64KB,可以轻松承载英文字体库。
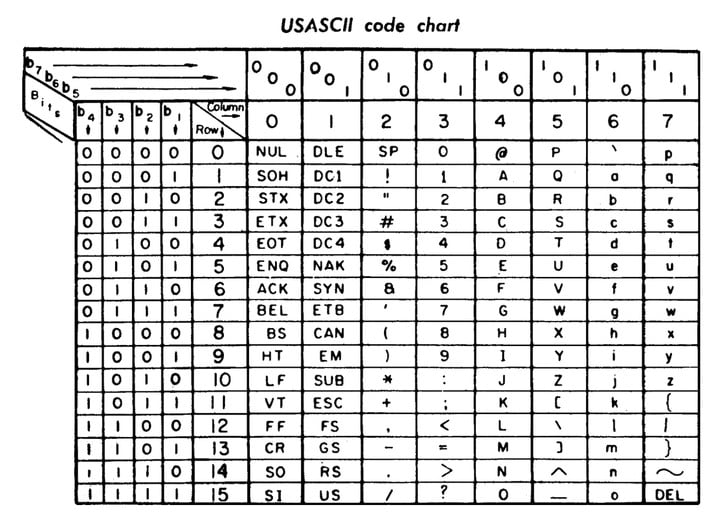
▲ASCII 字符表
而中文由于字形复杂,在 5X7 大小的网格中会糊作一团,难以辨认。因此至少需要一个 16X16 或者更大的网格。
这样换算下来,每个中文字符的大小至少有 32 字节。如果将 70000 个低分辨率的汉字打包,内存至少需要 2MB。再退一步,即便字库内只放进 8000 个常用的汉字,也需要约 256KB 的内存。
这无疑是一个大难题。因为在上世纪 80 年代初,大多数 PC 的总内存容量不超过 64KB,根本装不下庞大的中文位图字库。
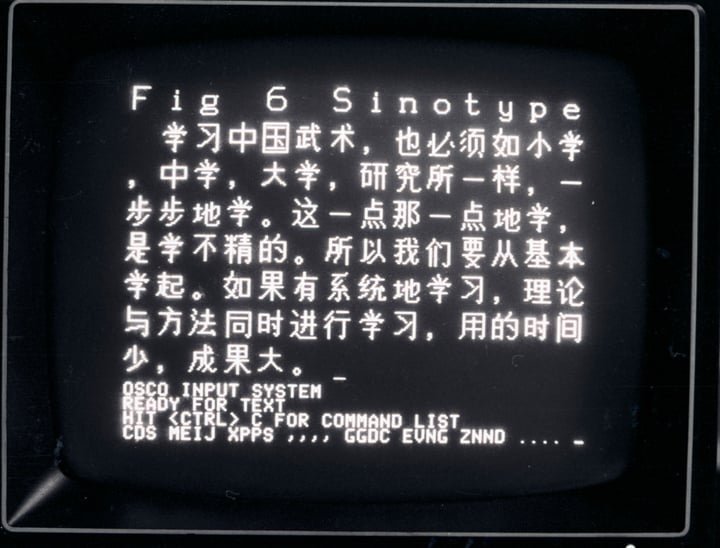
▲Sinotype III 显示器的照片,显示了中文字体. 图片来自:斯坦福大学
内存告急并不是最令人头疼的,因为这可以随着 PC 软硬件的进步得以解决。如何在 16X16 的低分辨率网格中,创造出既容易辨认又美观的中文字体,是更棘手的难题。
为此,路易斯团队的设计师们花了数年时间,尝试创造出满足低内存要求,且清晰易认,甚至有书法美感的中文位图。其中,凌焕铭(Huan-Ming Ling)和艾伦迪乔瓦尼(Ellen Di Giovanni)的贡献最为突出。
他们先是借助纸、笔、修正液来手绘出汉字的位图,然后借助上文提到的 Gridmater 程序将其数字化,植入到 Sinotype III 的系统中。
▲Sinotype III 显示的中文字体. 图片来自:Courtesy of Bruce Rosenblum
制作背后的匠人精神
托马斯教授在档案资料里,发现了路易斯团队设计汉字位图的全过程。在一个装满格子图的册子中,记录了设计师们是如何通过手绘散点符号来创造汉字位图的。
我们都知道,汉字的笔画并非「横平竖直」的,入口笔画、出口笔画、笔画渐变都有着丰富的细节。这也是设计师们面临的核心问题,即如何在 16X16 的方格中,尽可能将这种书法美展现出来。
在这本格子册中,可以发现每个汉字都经过设计师精心绘制。绿色的「X」是最初的标记,交由汉字编辑审核后,如果哪里不够规范,路易斯及其团队便会用修正液盖住原本的标记,再用红色的「X」标记上去。
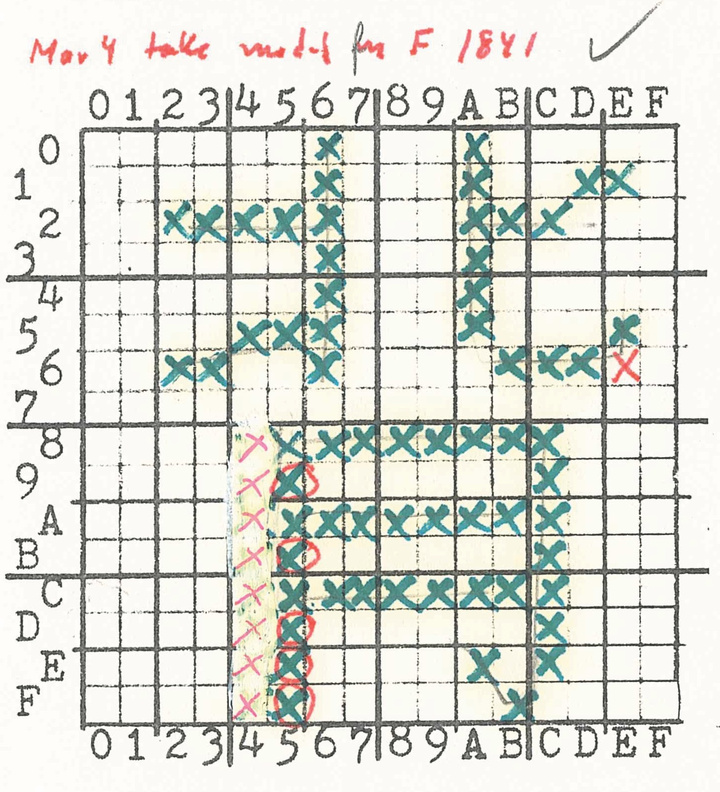
▲「背」字的位图草稿. 图片来自:斯坦福大学
经历反复修改,经过最终确认的位图,才会输入至系统中。
如果要满足消费者的需求,字库里至少要包含 3000 个常用的汉字。这个工程量对于团队来说是很大的。人们可能会猜测,他们是否会寻找一些讨巧的方法。
例如,对于相同偏旁部首的汉字,可以直接将偏旁部首复制过去。就像下图中「评」、「读」都是言字旁,按理说设计师只需要设计右侧不一样的部分就可以。

▲中文位图草稿. 图片来自:斯坦福大学
但是托马斯教授发现档案里类似的工作机制很少。路易斯坚持要求设计师逐字调整、设计,以确保每个字的偏旁部首看起来是协调的。即便有些改动十分细微,令人难以察觉。
托马斯教授按照档案资料重新复现了 Sinotype III 的中文字体。可以发现同样为「女」字旁的「娟」和「娩」,两个字的「女」字旁的设计样式并不一样。
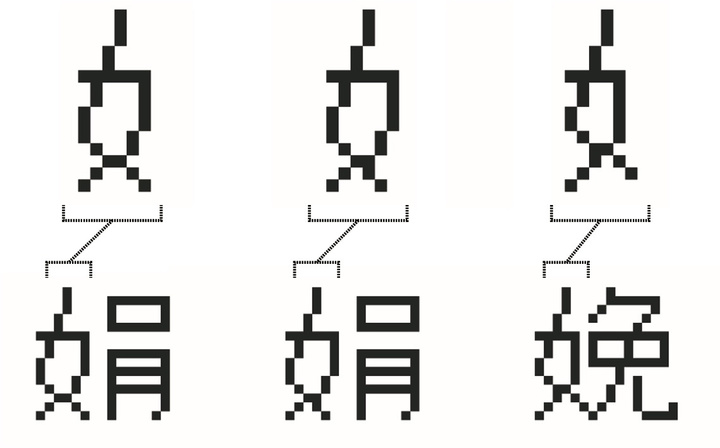
▲可以看出「女」字旁的不同吗? 图片来自:斯坦福大学
「女」字旁在「娟」字中的宽度为 6 个像素(网格),而在「娩」字中只有 5 个像素。另外「娩」字的「女」字旁撇点和撇的笔画,要比「娟」多一个像素,视觉上更加修长。
这样一丝不苟的设计并非个例。托马斯教授在字体库里发现了大量类似的工作,当他将位图的草稿与最终成品放在一起对比时,还能看到许多细微、有趣的变化。
比如在「罗」字中,左下角的笔画最初是以 45°向下伸展的。但最终版本,笔画的尽头被「拉平」,更符合书法的艺术感。

▲ 「罗」字的两个版本,左为最终版. 图片来自:斯坦福大学
可以看出,添加或缩减一个像素,便会对整体的平衡感、美感造成影响。这也体现出设计师们在创作首批字体的艰辛,以及背后的匠人精神。
实际上,16X16 的网格,对于创作中文字体并不是很友好。最主要的问题是对称性。
我们知道,大量的汉字是具有对称性的,而根据数学的规则,只有奇数大小的空间区域,才能创建出完全对称的形体。
因此,路易斯及其团队决定只利用 16X16 网格中的 15X15 区域,来实现汉字的对称。这进一步缩小了设计师的空间,对设计工作提出了更高的要求。
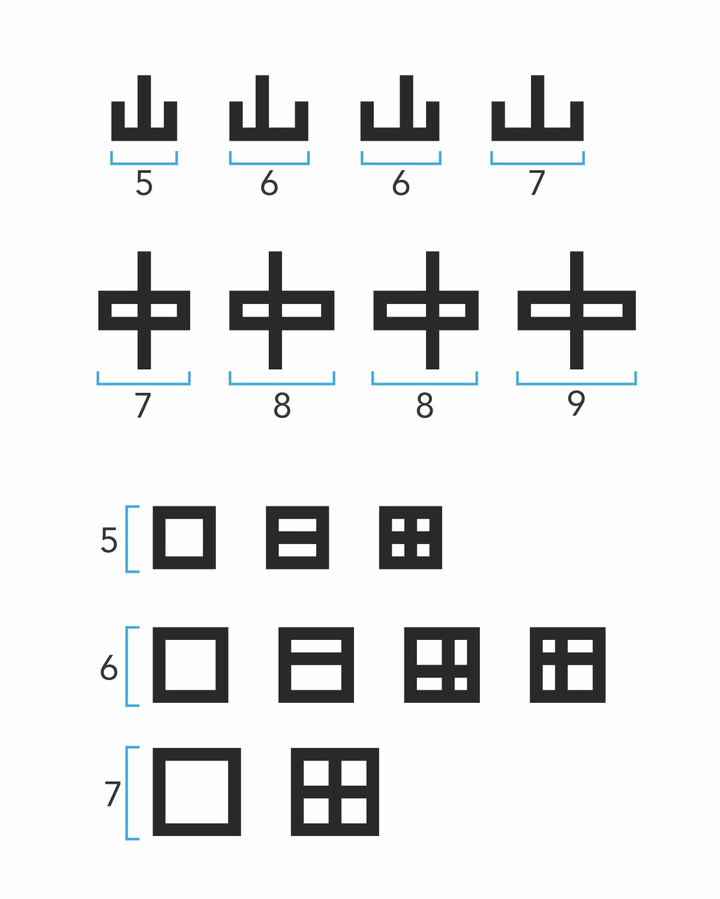
▲ 山、中、田的对称与非对称. 图片来自:斯坦福大学
得益于团队孜孜不倦的努力和一丝不苟的态度,Sinotype III 的中文字体库项目顺利完成。尽管它并未商业发布,但它的确是世界上最早能处理、显示、输入输出中文的 PC 之一。
当然,路易斯及其团队制作字体的方法,在当今的技术语境下看起来似乎太过古板和幼稚。现在广泛使用的 TrueType 字体技术,能够以矢量方式存储字体,占用空间小、渲染快、显示效果清晰锐利。

▲如今多数字体均是 TrueType 格式. 图片来自:themex
但正是他们使用「笨方法」,逐字画稿、反复修改,才让汉字得以进入数字世界。而「当代毕昇」王选院士主持研制的高分辨率字形信息压缩技术,更是彻底地解决了汉字编码储存的困境。
在这些前辈们的努力下,中文才没有被互联网大潮落下,汉语拉丁化的理论被扫进历史垃圾堆。我们今天能够使用中文在互联网上冲浪,应感谢他们曾为此付出的青春。





