






用了 TikTok 这个神器,我马上把 PS 卸载了
图像变文字,这在今天已经不再是问题了。各式各样的 OCR 功能让你可以从图片中提取文字变得更加容易,一幅图让 AI 来解释也不是什么大难题。
但画图对于今天的 AI 来说还是有难度的,识别图片提取信息对于 AI 来说是处理信息。但作图就多了一层,不仅要处理信息,还需要完成创作。前者是选择题,后者则是命题作文。
只是选择题答得好之后,下一步就是要答好自由发挥的主观题。只是没人想到,第一个在自家 app 上答出这道题的是 TikTok。
用 TikTok 生成 Facebook、马云
对比 Google、OpenAI 这类在 AI 行业投入颇多、浸淫已久的巨头,TikTok 可能只是一个「插班生」。但插班生绕过巨头先做出了难题,这怎么不让人感到惊讶?虽然插班生也使了一些巧劲,但至少做出来还是很令人感叹。
TikTok 做出来的文字转图片功能被叫作「AI 绿幕(AI Greenscreen)」,取代了原先单调的白底,由 AI 来为你生成视频的背景。这些视频的背景未必每一个都能契合创作者的需求,但毕竟这是为你定制的、独一无二的绿幕背景,运气好的话或许和视频内容的主题也会更配。
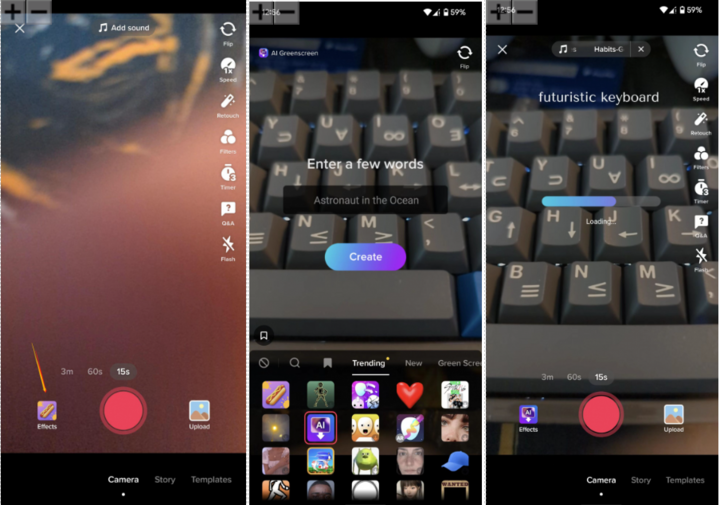
▲ 发视频时点击特效即可体验此功能. 图片来自硅星人
我们就用这个新功能做了一些测试,看看 TikTok 画出来的图到底是怎样的。在这些随机测试的词语中,有的画作呈现让人摸不着头脑,但也有的被评价为「很好地描绘出了诡异感」。
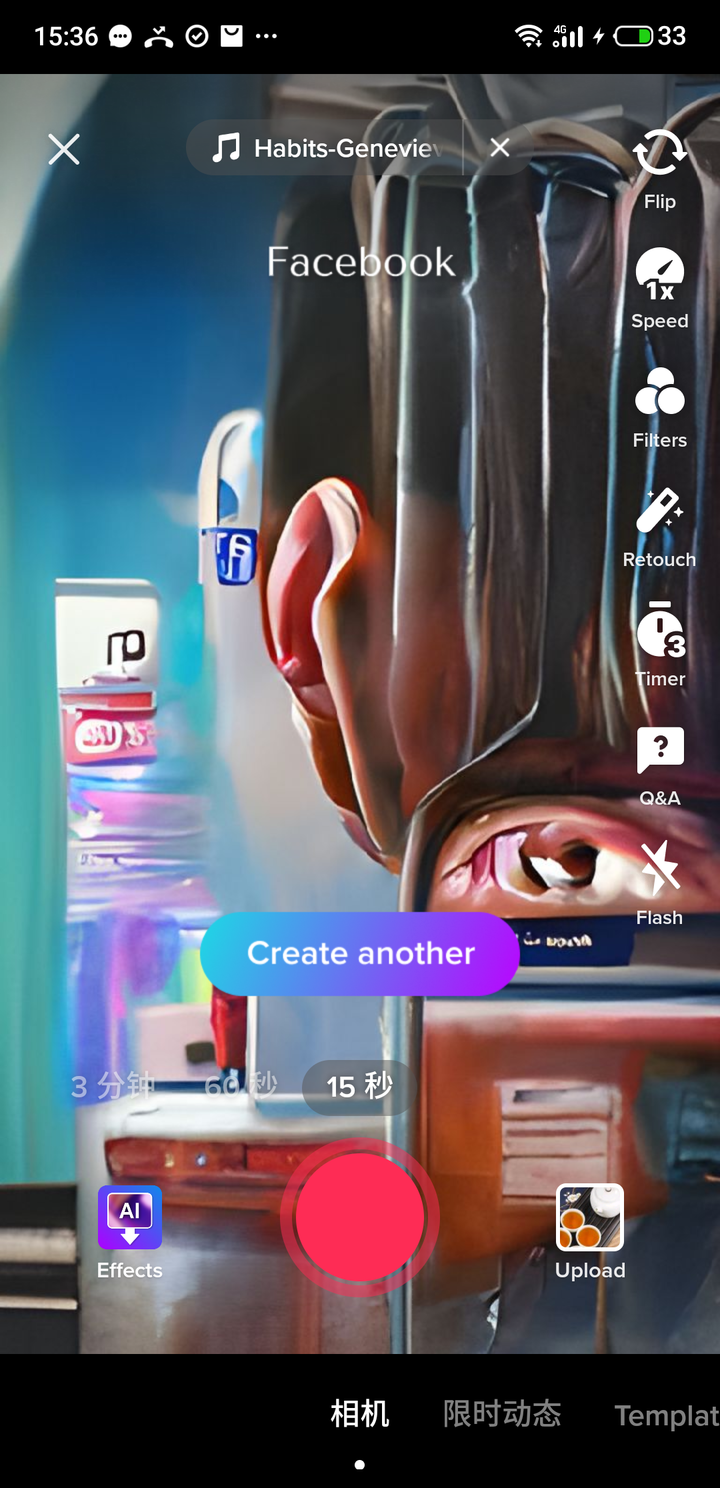
大受好评的就是输入「Facebook」呈现的画作,你隐约能够认出 Facebook 的蓝色图标,图片中单个的眼睛和一只耳朵营造了一种独特的惊悚感。结合一下 Facebook 近期的新闻,不得不说这幅画很好地描绘出了 Facebook 这个词的感觉。
图像描绘准确的还有苹果、中国这样的词。前者能够轻松看出是一个苹果,后者也能看出中国风的建筑,同时也避免了国旗这类在二创领域较为敏感的图案。只是你要想要呈现的是苹果公司的图就很难了,哪怕是苹果 + 苹果 CEO 库克的关键词呈现的也是苹果和菜肴相关的图案。

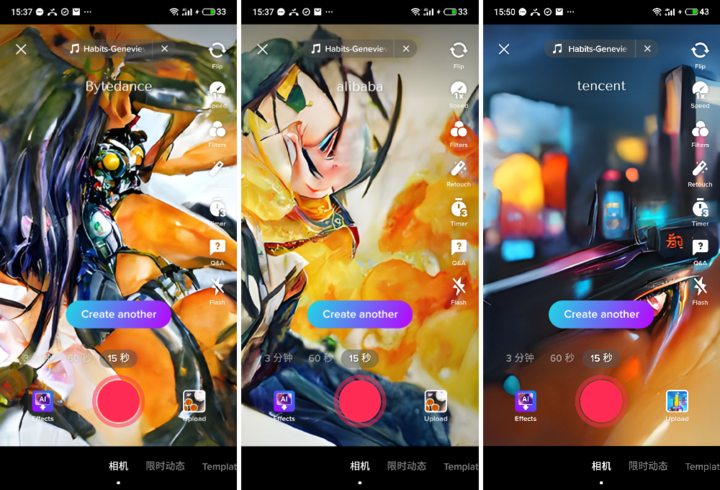
不过无关的也有不少,比如我们尝试了阿里巴巴、腾讯、字节跳动,生成的也不能板上钉钉地说和这些品牌无关。但不管怎么说也很难一眼认出,多少有些抽象。
输入人物姓名绘出的图画也有不少有意思的。在海外知名度不低的手工博主李子柒名字生成的就是一幅让人舒心的风景画;著名的英超前主教练温格生成的图画也能让人一眼认出,属于经典照片重新解构的风格;马云的风格也有点诡异,和 Facebook 一致的眼睛有种窥视感。
至于马斯克,我们用 TikTok 生成了四个图片没有一个能认出来的。
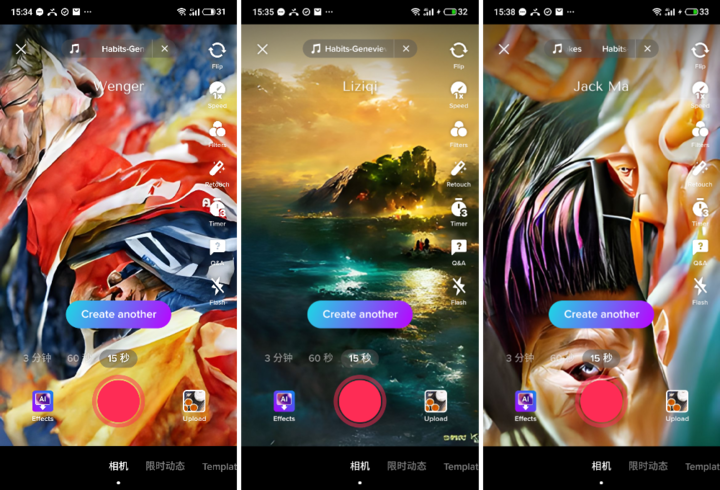
当然除了通过人物词成功、抽象图画,也有被认为表达得恰到好处,可以让人联想起来的 Switch、广州。
塞尔达式风格的画作,里面有的人物可以让粉丝认出「这可能是马里奥」。同样广州标志性建筑和绚丽的色彩也能让人轻松识别。
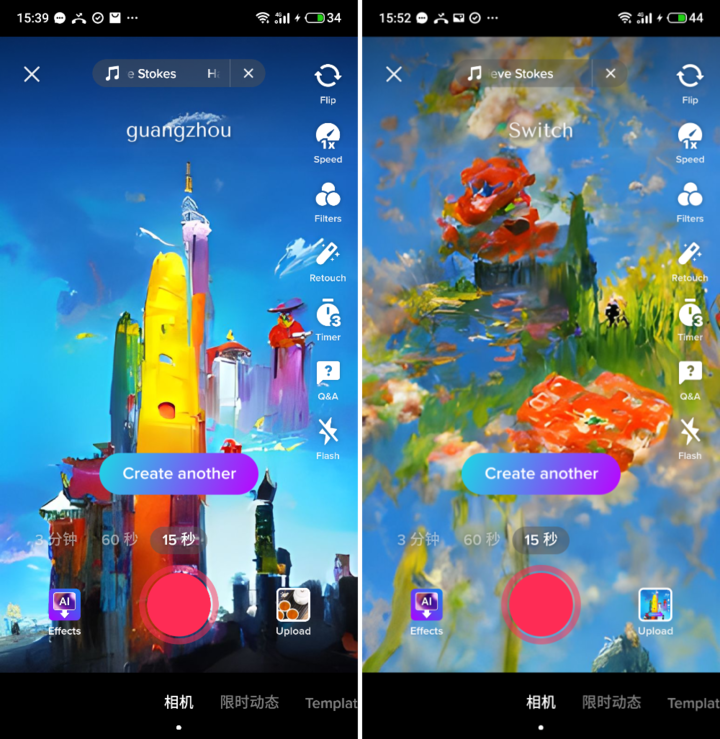
每张背景图生成的时间不到 5 秒,如果主题相近,那么这些图用来做视频的背景图是非常合适的。生成的时间短,人人可用,这都是 TikTok 的优势所在,所以这样一个文字转图像的产品出现在一个日活上亿的应用上也可以算是一个标志性事件。
只是 TikTok 还是走了捷径。
目前产生的图片几乎都属于画作风格,很多甚至属于抽象派、印象派,和生成写实的图像相比,这个难度就低了不少。毕竟就算不像也能靠脑补,理解你输入词的 AI 和去美术馆看画展的你面对的都是一样的问题——如果相似不够,那就理解来凑。
这也是一种省成本的方法,难度低一点,需要耗费的算力也低,成本也就更低了。
▲ 即便是内容略有血腥文字呈现的图片也不会太过惊悚
文字变图,连 Google 都还没有即时生成的产品
从效果上来看,TikTok 的 AI 绿幕呈现效果并不能打上超高分。但作为一项门槛颇高的技术,能够在几秒内被用户无门槛地使用到就已经算进步了。
虽然受限于生成图片目前还不够「日常」,不够写实不会引发技术滥用和图片造假的担忧,但写实的图片其实已经可以做到了,只是还不到 AI 绿幕这种人人可用的程度罢了。
Google 也曾发布过一个 Imagen AI 工具,可以把简单的句子变成一张真实的图片——像拍出来的照片一样真。但很遗憾,即便是在 AI 这方面投入巨大的 Google 也没能做出即时生成的产品。换句话说,输入要求让 AI 给你画图的选项在 Imagen AI 还没有。

▲ Imagen AI 可以点击不同选项作出不同图片
目前官网目前还只有一些预设的选项,就算每一个都点一遍也不过几十种搭配,但有写实风格和油画风格可以选择。感兴趣的读者,还是可以自己去点点玩玩看。
Google 属于名气大,一举一动都会备受关注的类型。而人工智能研究实验室 OpenAI 则是靠作品,它们推出了最原始、最受欢迎的人工智能文本到图像生成器 Dall-E。

▲ Dall-E
Dall-E 可以从文字内容中对现有图像进行逼真的再编辑,它可以为你添加和删除元素,在进行这些操作的同时还会考虑阴影,反射和纹理的呈现效果——PS 技术可以秒杀你。从已有的画作中分析模仿进行替换更是非常简单,灵感风格来源于原作,就是换了主角。
作为一个研究项目,Dall-E 还处于封闭测试阶段,而在名单中「有限数量的可信用户」在社交媒体上早就发布了一张又一张的照片。每个参与测试的用户最初可以获得 50 个免费积分,此后每月 15 分,1 分可以用一个文本内容生成 4 张图片,还可以选择三种画风。
目前 Dall-E 还有很少的变现方式针对内测用户——每月 15 积分用完后还想要体验服务,可以花 15 美元购买 115 个积分。好在生成的图片也可以被商业化,一旦你通过 Dall-E 创作了它,就可以把它们用于插图、封面、T 恤设计等各个方面。

▲ 用户可以在设定好的位置添加元素,添加进照片的元素在阴影等方面也会自动补充
视频导演 Karen X. Cheng 就对彭博社表示:
我一连好几个小时都在体验生成图片,甚至迷失了方向……这感觉更像是你在和一个活生生的、会呼吸的人合作,和你合作的已经不是 Photoshop 那样的工具了。
当然 Dall-E 目前也并非完美的,想要创造出完全逼真的人脸对它来说依旧有点难,需要专业医学知识摄入才能够准确的人类骨骼呈现它做的也不是很好。研究员 Aditya Ramesh 表示 DALL-E 只知道如何阅读文本继而生成图片,所以它其实是在努力创造一些视觉效果相似的内容。

▲Dall-E 生成的奇幻图片
这项技术当然是很有前景的,你可以想象它为内容创作者降低图片寻找的门槛,也可以想象画像师在它的帮助下可以提升效率。但正如每一个技术的出现都可能被滥用一样,AI 帮助文字生成图片的技术也有这样的风险——那些 Deepfake 上曾出现过的负面应用场景都会一一重现。
好在这次技术提供者早就提早做好了准备想要把 AI 关在笼子里了。
TikTok 的抽象图片本身就是一重保护,因为它不写实。此外,即便你在 TikTok 中输入一些充满暗示的内容(暴力、裸露)呈现出来的画作依然不如预想中的那样,抽象的风格并不清晰也规避了审核需要付出的巨大成本。
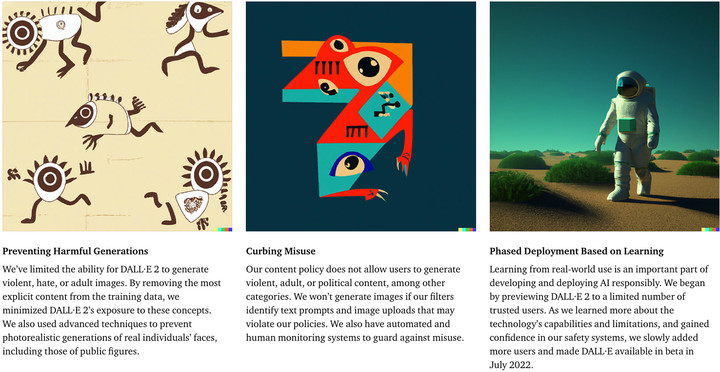
▲ Dall-E 官网的限制说明
Dall-E 也限制了 AI 生成暴力、成人、仇恨内容,在算法中就尽量减少了 Dall-E 对此类概念的接触。同时,平台也有先进的技术防止使用真实的人的面部生成图像(名人松了一口气),自动化和人工监控系统亦能防止 Dall-E 的滥用。
只是所有新技术的出现也不能只看坏的那一面,它所带来的高效前景就很值得期待。至少,爱范儿就很期待哪天推送的文章末尾写着「文章题图由 Dall-E 生成」。





