






ChatGPT 们难以复制的原因,除了耗显卡,还有水电费太贵?
一觉醒来,世界又变了。
ChatGPT 走入大众视野之后,AIGC 行业迎来了爆发,尤其是上个月,仿佛每一天都可能是「历史性」的一天。

以 ChatGPT 为代表的生成式 AI,看似超前,但却以一种极其「古典」的交互形式出现在大众面前。
它没有花里胡哨的图标,也没有深入人心的 UI 设计,而是用最简单的对话框来「震撼」世界。
![]()
不过,如此简单的形式,却成为了当下网络上和现实里最火热的话题,果然「好看的皮囊千篇一律,有趣的灵魂万里挑一」。
只是存在于一个个 web 网页,一条条简单的问答中,往往会让我们忽略不少问题。

看似毫无负担的一个个「回答」,背后却用着世界上屈指可数的云算力。
随着 ChatGPT 成为常态,隐藏在 ChatGPT 们背后的这些角落也逐步被报道出来。
烧钱费电,还喜欢喝水
生成式 AI 耗费显卡这种情况,有些类似于「挖矿」。

▲ 由 TPU v4 组成的 Google 机器学习中心 图片来自:Google
对大语言模型(LLMs)进行训练,参数越多,性能越好。2018 年的 LLM 大约有 1 亿个参数,而到了现在,大约就要对 2000 亿个参数进行训练。
运行他们需要算力更强的 GPU,英伟达也在 2020 年推出了相对应的 A100 高性能 GPU,并且也可以打包八张 A100 形成 DGX A100 服务器。

▲ AI 的精神食粮
这些计算服务器,或者说显卡组,最终被安放在所谓的云计算中心,比如说微软的就是 Azure 云服务。
不光训练大语言模型需要大量算力,当每个用户请求一次,ChatGPT 们回答一次,都要调用部分算力。
流量就是金钱,我想 OpenAI、微软应该有刻骨铭心的体会。

根据 Similarweb 的数据,上个月 ChatGPT 吸引了全球 16 亿次访问,是一月时的近三倍。
这种情况下,即便微软有所准备,给 ChatGPT 准备了一万多张 A100,但面对如此的流量,OpenAI 还是坚持不住了,出现了宕机、封号和暂停 Plus 会员的开通。
有人做过预估,想要吃下当下的流量,微软还得买几万张 A100、H100 显卡,Azure 现在的算力远远不够。
但买更多的显卡,除了烧钱,也会衍生出许多问题。

八张 A100 组成的 DGX A100 服务器大概售价 19.9 万美元,最高功率为 6.5kW。
按照一万张来算的话,光在硬件上微软就要花去 2.5 亿美元,运行一个月就要用掉 585 万度电,电费就要得交
而按照国家统计局公开的数据,我国居民月度用电量大约是 69.3 度。ChatGPT 运行一月,大概与我们 8 万人用电相当。
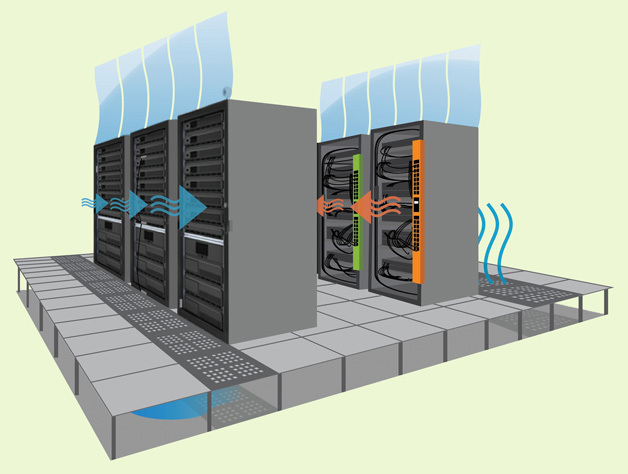
除了显卡本身的价值,以及维持他们工作所需的电能外,给他们创造一个凉爽的环境,配置一套蒸发冷却装置。
原理也比较简单,就是利用蒸发水来散热,但运行起来需要消耗大量的清水,并且在循环的过程里,大概会有 1%~2% 的水会作为细水雾被风吹走。
虽然站在宏观角度,水仍然维持着动态平衡,但在冷却塔的小环境中,却是一种无形的消耗。

结合 AIGC 需要庞大算力的计算中心,卡罗拉多大学与德克萨斯大学的研究人员就在论文里预估了在训练过程中所消耗的清水。
以 GPT-3 为例,训练过程中所需的清洁淡水相当于填满核反应堆冷却塔所需的水量。果然 AI 最终还是要跟核电挂上钩。
如果再具体点,则大约消耗了 70 万升,并且他们还算出,一个用户与 ChatGPT 进行 25~50 个问题的对话,大概就相当于请 ChatGPT 喝了 500ml 水。

同时,他们也发现,蒸发冷却塔在工作时,平均每消耗一度电,就会让一加仑水(3.78L)消失。
其实不止是微软,Google 在 2019 年为其三个数据中心使用了超过 23 亿加仑的清水。

▲ Google 的数据计算中心 图片来自:Google
在美国本土,Google 拥有 14 个数据中心,为其搜索和现在的 LaMDA 和 Bard 提供算力。且在训练 LaMDA 语言模型的过程要比 GPT-3 还耗能费水。
原来,AI 不止费显卡,住恒温的大 house,胃口还出奇的好,大口吃电,大口喝水。
无处不在的 AI 鸿沟
在 AIGC 行业里,一个简单的,能准确响应的对话框,背后不止是展示技术实力,也展示了雄厚的金钱实力。
Sasha Luccioni 博士就表示,大型复杂的语言模型,世界上只有少数的公司和组织才有资源训练它们。

▲ Sam Altman(左)和微软 CEO Satya Nadella(右)图片来自:Wired
还是以 GPT-3 为例,训练 1800 亿参数,成本大约是 460 万美元,还不包括后续的运行和迭代维护等等。
这些有形和运行过程中带来的无形成本,很多公司很难承受。
由此,在 AIGC 浪潮里,无形之中有了那么一个 AI 鸿沟,大概也分成了两类公司。

一种是,花得起耗得起资金,能够训练先进复杂的大预言模型的大型科技公司。另一种就是无法承担成本的的非盈利组织和小型公司。
在许多关于 AIGC 到底消耗了多少电力、资源的许多研究报告中,大多是以 GPT-3,或者用「预估」等字眼。
就像对训练 GPT-3 用了多少水的研究里,由于 OpenAI 并没有披露 GPT-3 训练所需的时间长度,因此研究人员只能从微软所公布的 Azure 计算中心冷却塔的数据来预估。

而关于碳排放等一系列参考数据,也多是从 2019 年的 Bert 训练模型中预测而得。
除了资金、GPU、数据中心、网络带宽等等硬实力,Google、微软也把大语言模型的训练算法、过程、时间、参数等等都列成了最高机密。
我们想使用和了解它,只能通过提供的 API ,或者直接询问 ChatGPT 或者 Bard 本身。
无形之中,这也成为了一个「AI 鸿沟」。
AIGC 发展的如此迅速,并且能力也在无限扩大,许多国家地区和组织都在考虑如何给 AIGC 设立一些规范,免得它(产生自我意识,开始觉醒……)恣意妄为。

但就如同相关的研究人员一般,目前 AIGC(如 GPT-4)几乎没有公开的信息,更像是一个黑盒。
诚然对于大公司而言,AIGC 可能就是下一个新时代的开端,塑造科技壁垒,无可厚非。
但对于资源的消耗,无论是对于立法机构,还是对于大众,都该保持一些透明度,
这也是 AI 在提供便利的同时,为何研究人员不断挖掘和道明相应的代价。
发展 AI,其实也是人类的一次登月
对于 AI 耗电、排碳,以及最新的费水等研究,并非是在谴责、或者说反对发展 AIGC 用资源去换取技术的改进。
这些数据,其实是提供了 AIGC 行业的另外一个角度,在一条条符合人味儿回答的背后,到底我们或者说大型科技公司为此付出了什么。

也并非是要呼吁 Google、微软立刻做碳中和,并为耗费的水资源、电能和间接的一些环境问题买单,让它们变成 Google Green 或者是绿软。
AIGC 的爆发,并不是一簇而就,也不是简单开窍式的技术爆发,它背后涵盖了相当多的产业链,更像「水到渠成」。
大公司云计算中心算力的增强,以及 GPU 对复杂算法的高效计算,以及大语言模型参数的复杂化,再加上 AIGC 企业本身一直在不计成本的投入。

▲ 大型数据计算中心只是 AIGC 行业的一环
而在 GPT-3 出现之前,AI 们的能力还显得比较稚嫩,大众也没意识到 AI 可能会改变世界。
但随着 GPT-4、Midjourey V5 等等涌现,AIGC 也终于成为了硅谷宠儿。
此时此刻,OpenAI、微软、Google 等大企业对资源的消耗,对大算力的使用也有了一个初步的成果。

▲ 《为了全人类》剧照
同样地,当下的 AIGC 节点,有些类似于阿姆斯特朗刚踏上月球的那一刻。
登月动用了当时相当的资金财力资源,但月球上并没有所谓的水和可利用资源(暂时)。
但并不能否认登月没有意义,就如同现在花去大量的资源、财力喂给 AI,发展 AIGC。
只是,AIGC 能发展到如何,谁也说不准,它可能像是《终结者》里的天网,也可能是《星战》里的 CP30,有着无限可能。





