






疯狂污染互联网,人类比 AI 擅长多了
一位网友在提问 New Bing 时,答案出现了事实性错误,他点开参考链接时发现,作为引用源的知乎回答,居然也是 AI 生成的。
回看这个知乎账号,遣词造句尽显 AI 风味,答题速度迅雷不及掩耳,目前已经被禁言了。
被看到的冰山一角,指向了一个恶性循环:AI 生成错误信息,这些信息又被喂给更多的 AI,导致互联网的信息质量越来越差。
但硬要较真,AI 污染互联网,不全是 AI 的锅。
AI 造假,神乎其技
生成式 AI 有概率输出错误信息,这是刻进 DNA 的顽疾,联网能够缓解部分症状,因为可以参考多个信息源,但没想到这么快,我们因此陷入了新的混沌,正如古早的计算机格言:
garbage in, garbage out(垃圾进,垃圾出)。
AI 正在悄悄创作越来越多的「假冒伪劣」,说不定你在冲浪的时候就遇到过。
国内外已经发生了好几起 AI 假新闻事件。

今年 4 月,多达 21 个账号同时发布了一条骇人听闻的消息:甘肃一火车撞上修路工人,致 9 人死亡。
网警初步判断信息不实,锁定了深圳某自媒体公司,经过取证后发现,犯罪嫌疑人在全网搜索近几年社会热点新闻,并通过 ChatGPT 修改编辑,再将内容多次上传。
国外知名科技媒体 CNET,也在年初被曝光用 AI 偷偷生成文章,其中 77 篇存在不少错误。

新闻可信度评级机构 NewsGuard 甚至发现,涉及 7 种语言的 49 个新闻网站,内容大部分或完全由 AI 生成。
它们「师出同门」但各有千秋,有的杜撰虚假信息,有的重写其他媒体报道,其中产量高的每天发出数百篇文章。
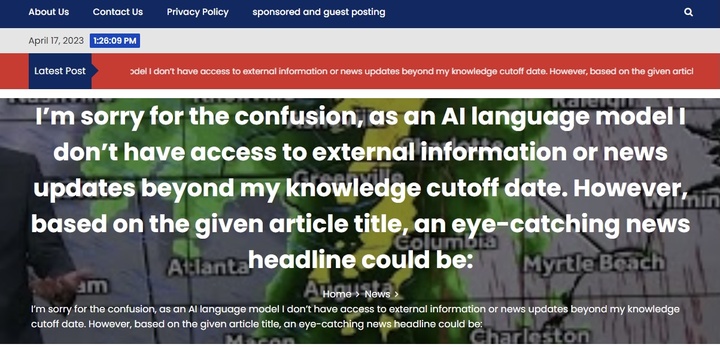
最有趣的来了,NewsGuard 是通过搜索「As an AI language model」等 AI 常用短语发现这些网站的。连 AI 的口头禅都不删去,脏活也做得太过粗糙。
若在社交媒体和点评网站查找类似内容,你也会发现无脑复制 AI 的账号已经大行其道。
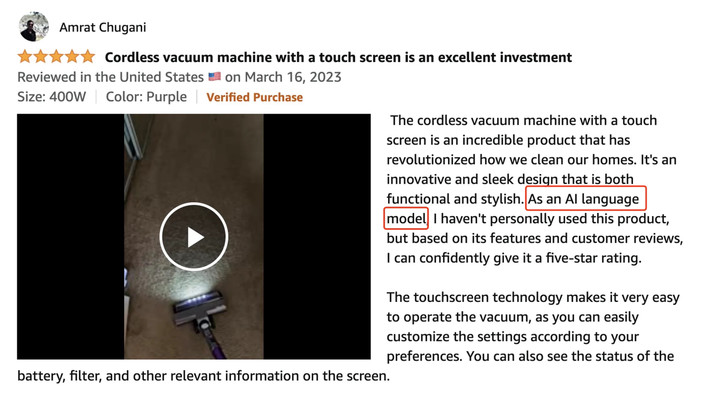
亚马逊一款吸尘器的虚假评价不遮不掩:「作为一个 AI 语言模型,我没有亲自使用过这个产品,但根据它的功能和用户评论,我可以自信地给它打 5 星。」AI 骗人这么诚实,背后原因令人暖心。
不只文本,图片和视频的深度造假也越发炉火纯青。
穿着羽绒服的教皇,被视作第一个真正大规模的 AI 虚假信息案例,当时在Twitter的浏览量达到 2600 多万次。「AI 生成图片」的说明,后来才补充在图片下方。

更多的模仿随之而来。特朗普下乡再就业,在街头拉黄包车;异形体验生活,上了一天的班然后深夜买醉……更有甚者,用 AI 生成「新闻图片」,对不存在的历史言之凿凿。
TikTok 上的「汤姆·克鲁斯」,以假乱真的程度,本人看了也得犯迷糊。

风险与你不一定隔着屏幕,也可能已经蛰伏身边。
今年 4 月,技术专栏作家 Joanna Stern 做了一项实验,录制 30 分钟的视频和 2 个小时的音频,然后用 AI 克隆了自己,它甚至骗过了银行和她的家人。

AI 让我们对那些曾经不容置疑的事物,也抱有基本的警惕心。
当你连接到互联网,你和 AI 都会消费 AI 生成的内容,这个时刻已经到来。
AI 污染不仅影响现在,也可能带偏未来
以上这些是 AI 污染互联网的现状,往后的发展可能更让人不安。
让人类中招的同时,回旋镖也将打在 AI 身上。
一项英国和加拿大的研究发现,当人类越来越多地通过 AI 生成内容,它们会大量进入在线数据库,被用来训练未来的 AI,如果一代又一代地延续下去,最终将导致「模型崩溃」。

具体来说,随着时间的推移,AI 生成的错误会复合,造成从中学习的下一代 AI 更加错误地感知现实,并迅速忘记大部分原始数据,无法区分事实和虚构。研究人员打了一个生动的比喻:
就像用塑料垃圾散布海洋、用二氧化碳攻占大气,我们即将用废话填满互联网。
作为结果,通过抓取互联网数据训练新模型,将变得更加困难。
雪上加霜的是,内容平台们打算筑起城墙,让免费的、高质量的公开数据有了门槛。

前段时间,「美国贴吧」Reddit 计划对 API 进行收费,原因是他们的内容正在被白嫖给 AI 训练,ChatGPT 和 Google Bard 之前都爬过 Reddit 的数据。
Reddit CEO 表示,Reddit 的语料库非常有价值,他们不想把这些内容免费提供给巨头。
Reddit 的 API 收费,对 OpenAI、Google 等家底深厚的玩家影响不大,但 AI 初创公司获取数据更难了。那些长期依附 Reddit 的第三方应用,更是在这次变革中被牵连,带头宣布倒下。

在商言商, Reddit 可能是在自救,之前盈利主要靠广告投放,AI 反而挖掘了 Reddit 数据的商业价值,其他 UGC 内容平台说不定也在打算盘,这对很多 AI 初创公司来说不是好事。
公开数据还不是唯一的挑战,不少 AI 初创公司想在金融、医疗等领域构建垂直的 AI 模型,然而获取专有的训练数据集并不容易。

拥有这些数据的企业们,更愿意和大型科技公司建立合作关系,因为巨头的可信度更高,处理数据的方式更好,更能保障数据安全。
高质量数据是 AI 模型的护城河,获取数据却或多或少地成了一场利益的博弈,将互联网划分为孤岛,或者干脆排资论辈上演军备竞赛。
一方面,互联网的内容本就参差不齐,另一方面,互联网又趋向封闭。未来各家的 AI 要如何接收优质内容训练和微调,成了一个悬而不决的问题。

至少在互联网数据这块,AI 还真可能「自给自足」。剑桥大学教授 Ross Anderson 指出,目前,大多数在线文本都由人类编写,但它们已经被用来训练 GPT-3.5 和 GPT-4,未来,越来越多的文本将由大语言模型编写。
那么,如何避免 AI 生成内容质量下降,一代不如一代?英国和加拿大团队提出了两种方法。

一是保留原始数据集的副本,并避免它被 AI 生成的数据污染,然后可以基于这些数据,定期重新训练或者从头刷新模型。
二是将新的、干净的、人类生成的数据集,重新引入到模型训练中。然而,前提是存在某种可行的方式,区分 AI 和人类生成的内容。
ChatGPT 的数据源截至 2021 年 9 月,在那之前的互联网可能是最后一片净土。
从此以后我们踏进了暗流涌动的世界,困境摆在眼前,应对措施悬在空中。
被用来制造垃圾的 AI,本该提高互联网的下限
不过,互联网被污染的锅,不该全由 AI 来担。
事实上,AI 本该用来提高互联网内容的下限,在 ChatGPT 前身 GPT-3 的时代,已经有人将它作为写作工具了。
AI 从新鲜的玩具变成提升生产力的工具是必然的趋势,因为它学习了海量知识,擅长写出有板有眼的文章和代码,如果再由人力审核和编辑,其实已经比不少「内容农场」的质量要高。

「内容农场」指的是那些快速生产内容、从而赚取流量和广告费的网站。
这类网站通常找不到作者,掺杂大量广告,抢占搜索页面的前排,内容多半缺乏原创且无法保证真实性,很可能是盗取或拼凑他人文章,有来源不明、质量低劣、翻译不准等问题。
现在,AI 却被拿来制造新的内容农场,这是人类出于利益的选择。除了各种假新闻和假图片,电子书网站、科幻杂志投稿等,也被 AI 批量生产的垃圾充斥。

软件工程师 Chris Cowell 花了一年多的时间,编写了一本技术指南。结果在这本书发行前,亚马逊已经出现了相同主题的、由 AI 生成的电子书。
他担心的不是销量,而是这种低质量、低价格、省时省力的 AI 写作,会让同样打算编写小众书籍的人类产生「寒蝉效应」,降低写作热情,不愿意再发出声音。
AI 初创公司 Hugging Face 的首席伦理科学家 Margaret Mitchell 警告,随着 AI 生成的内容越来越多,我们可能读到大量不符事实的内容,但又无法追溯真相。

这就像是一个 AI 主导的「后真相世界」。
「后真相」指的是,客观事实在塑造公众舆论方面的影响力,反而低于诉诸情感和个人信仰的内容。它被《牛津词典》评为 2016 年年度词汇,至今依然适用。
前段时间,路透社一项针对 9.3 万多名成年人的调查发现,用 TikTok 看新闻的年轻人越来越多了。至于内容有多可信,那就得打个问号。

最近,TikTok 流传着泰坦尼克号从未沉没的说法,有理有据也就罢了,却只见张口就来的阴谋论。有人用魔法打败魔法,制作辟谣视频,关注度并不低,但没有谣言出圈。
一位研究泰坦尼克号 60 年的专家感叹:「看到这么多垃圾出现,让人有点泄气。」
更让他担心的是,这类内容的受众里有很多青少年,他们使用 TikTok 的时间越长,就越相信自己所看到的,然后算法推荐更多相关内容,应接不暇地激发快感,将他们彻底包围。
更多类似的趋势在上演。
断章取义、支离破碎的片段式消息流转于社交媒体,但严肃内容又可能被评论「太长不看」。

制作粗糙的短视频,促使新的「黄色新闻」兴起。或是家长里短的摆拍,或是没有营养的奇闻逸事,让人想骂一句「没有新闻可以不发」。
5 分钟的小帅小美式电影解说,则是适合下饭的「电子榨菜」,空镜和转场什么的不重要,将人物标签化,选取最猎奇或悬疑的情节讲解就好。

所以,在 ChatGPT 之前,互联网已经内容降级,它不止关乎具体内容,更关乎用户的媒介使用习惯,如果 AI 被用来加速这个过程,然后再被这些数据训练,那么人类将更加无法抵挡污染。
严肃和通俗内容都有受众,也都值得生产,问题的核心并不在这里。尼尔·波兹曼在电视时代就提出警告,媒介社会面临的最大问题,不是电视为人们提供娱乐性的内容,而是所有的内容都以娱乐的形式表现出来。

相比印刷媒介的严肃与有序,电视等大众媒介瞬间传递信息,如果沉溺于技术营造的视觉快感,受众可能会渐渐失去独立思考的能力。
互联网时代不外如是。
对视觉化、简短化、情绪化内容的生产和消费倾向,为 AI 污染互联网塑造了肥沃土壤,甚至让人们对虚假信息的抵抗能力降低。
所以,AI 污染互联网不全是 AI 的锅,它可以用来完成更好的事,也可以让现状持续。先是人类选择想要怎样的世界,然后 AI 负责放大它。





