






在轻薄本上跑 Stable Diffusion 和端侧大模型?英特尔说没问题
当然,这一轮 AIGC 浪潮主要发生在云端,无论是 ChatGPT,还是文心一言,通义千问这类大语言模型应用,亦或是 MidJourney 这类 AI 生成图片的应用,还有不少像 Runway 这样 AI 生成视频的应用,都需要联网,因为 AI 计算都发生在千里之外的云端服务器上。
毕竟一般而言,服务器端能够提供的算力和存储,要远大于电脑端和手机端,但情况也并非绝对,响应快,无需联网的端侧 AI 毫无疑问是另一个趋势,和云端 AI 能够相互互补。
在前不久的小米年度演讲中,小米创始人雷军表示,小米 AI 大模型最新一个 13 亿参数大模型已经成功在手机本地跑通,部分场景可以媲美 60 亿参数模型在云端运行结果。
虽然参数量不太大,但说明了大模型在端侧的可行性和潜力。
在算力大得多的 PC 端,是否也有端侧大模型等 AIGC 运用的可行性和潜力呢?8 月 18 日,英特尔举办了一场技术分享会,着重分享了 2 个方面的信息:英特尔锐炫显卡 DX11 性能更新,并推出全新英特尔 PresentMon Beta 工具,以及展示英特尔在 AIGC 领域的进展。

去年英特尔锐炫台式机产品发布时,就承诺过英特尔锐炫显卡会持续优化升级,带来更出色的体验。
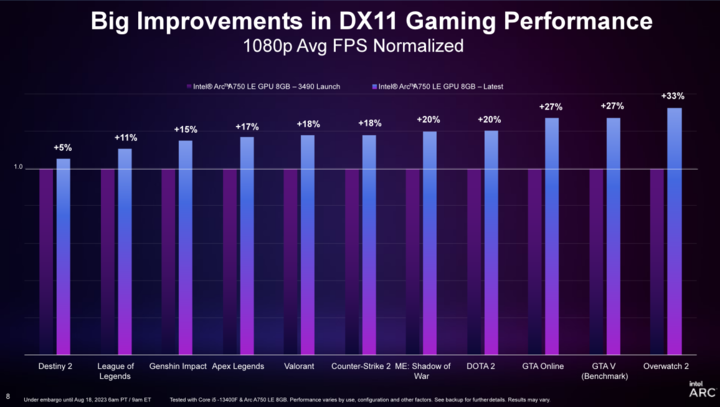
通过最新 Game On 驱动的发布,英特尔锐炫显卡在运行一系列 DX11 游戏的时候,能够获得 19% 的帧率提升,以及平均约 20% 的99th Percentile帧率流畅度提升(相较于首个驱动版本)。此前购买使用过英特尔锐炫 A750 显卡的用户,可以直接下载最新驱动,在《守望先锋 2》、《DOTA 2》、《Apex Legends》等游戏中获得体验升级。
对于在显卡选择上有点犹豫的用户来说,1700 元档位上的锐炫 A750 显卡也成为了颇有竞争力的选择。
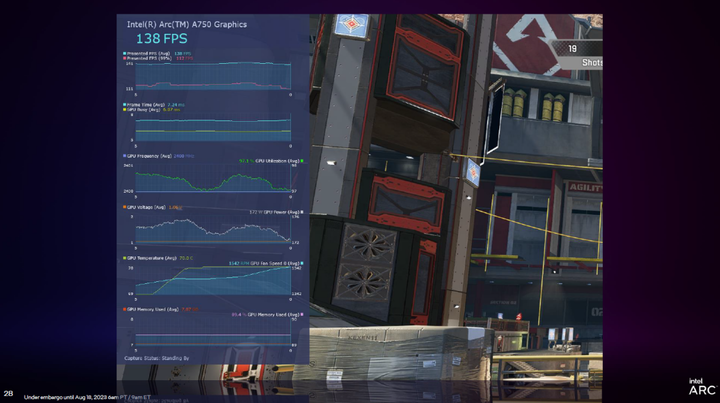
PresentMon Beta 则是英特尔推出的图形性能分析工具,提供了 Overlay(叠加视图)等功能,可以在运行游戏时在屏幕上显示性能数据,帮助玩家实时遥测 GPU 的电压和温度等,实时分析大量信息。同时也可以查看 99th Percentile 帧时间与 GPU 占用率图表。
另外,PresentMon Beta 也带来了名为「GPU Busy」的全新指标。这里可以解释一下,用户通过它可以看到 GPU 实际使用了多少时间进行实际渲染而不是处于等待状态,或者在运行游戏的 PC 是否处于 CPU 和 GPU 平衡。
游戏是 PC 永恒的主题,而 AI 则是新晋的主题。
实际上,这一轮 AIGC 浪潮发生的主阵地设备,就是 PC,无论是 ChatGPT,还是 MidJourney,或者 Stable Diffusion 等等应用,包括基于大模型的微软 Office Copilot,亦或是金山办公的 WPS AI,都是在 PC 上才可以获得更好的体验。
但 PC 相较于其他设备,诸如手机,平板和优势,不仅在于屏幕更大,交互输入更高效,还在于芯片性能。
在英特尔谈 PC 上的 AIGC 之前,我们关注到 PC 端侧跑 AIGC,往往就是用高性能游戏本去跑图,但轻薄本往往被排除在外。
现在,英特尔明确表示了,基于英特尔处理器的轻薄本能跑大模型,也可以跑大模型和 Stable Diffusion。
英特尔基于 OpenVINO PyTorch (英特尔推出的一个开放源码工具包,旨在优化深度学习模型的推理性能,并将其部署到不同的硬件平台上)后端的方案,通过 Pytorch API 让社区开源模型能够很好地运行在英特尔的客户端处理器、集成显卡、独立显卡和专用 AI 引擎上。
比如开源的图像生成模型 Stable Diffusion (具体讲,是 Automatic1111 WebUI)就可以通过这种方式,在英特尔 CPU 和 GPU(包括集成显卡和独立显卡)上运行 FP16 精度的模型,用户实现文字生成图片、图片生成图片以及局部修复等功能。
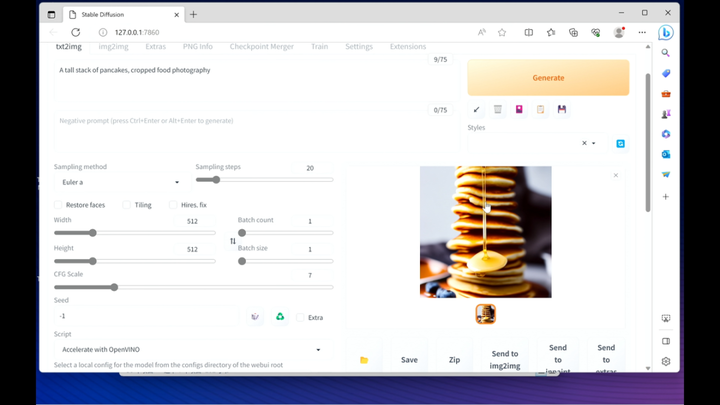
▲ 图片来自:爱极物
比如这张 512×512 分辨率的蜂蜜薄饼图在英特尔处理器轻薄本(只用 i7-13700H 的核显)上,只需要十几秒就可以生成出来。
这主要得益于 13 代酷睿处理器在核心数、性能、功耗比还有图形性能上的进步,以 14 核心 20 线程的 i7-13700H 处理器为例,它的 TDP 达到了 45W,集成的 Intel Iris Xe Graphics (96EU) 显卡也不容小觑。
作为目前最高规格的核显之一,Intel Iris Xe Graphics (96EU) 相较于 Iris Plus 核显最高 64EU,基本规格提升明显,FP16、FP32 浮点性能提升幅度高达 84%,还引入了 INT8 整数计算能力 ,这些都加强了它的 AI 图形计算能力,也是英特尔轻薄本能够很好支持 Stable Diffusion 的主要原因。
在以往,TDP 45W 左右的英特尔处理器很难装进轻薄本,不过到了 13 代酷睿,已经出现了一大批在 1.4KG 左右的轻薄本把 14 核心 20 线程的 i7-13700H 处理器乃至性能更高的 i7-13900H 处理器塞了进去,所以,在笔记本上跑 Stable Diffusion 快速出图已经不是高性能独显游戏本的专属,今后轻薄本同样能够胜任这项工作。
当然,Stable Diffusion 本身主要跑在本地,轻薄本通过芯片性能的提升和优化来运行合乎逻辑,不过本地的端侧大模型则属于较为新生的事物。
通过通过模型优化,降低了模型对硬件资源的需求,进而提升了模型的推理速度,英特尔让一些社区开源模型能够很好地运行在个人电脑上。
以大语言模型为例,英特尔通过第 13 代英特尔酷睿处理器 XPU 的加速、low-bit 量化以及其它软件层面的优化,让最高达 160 亿参数的大语言模型,通过 BigDL-LLM 框架运行在 16GB 及以上内存容量的个人电脑上。
虽然离 ChatGPT3.5 的 1750 亿参数有量级差距,但毕竟 ChatGPT3.5 是跑在一万颗英伟达 V100 芯片构建的 AGI 网络集群上。而这通过 BigDL-LLM 框架运行 160 亿参数大模型是跑在英特尔酷睿 i7-13700H 或 i7-13900H 这样为高性能轻薄本打造的处理器上。
不过这里也可以看到,PC 端侧的大语言模型,也比手机端侧的大语言模型高一个量级。
出现了数十年的 PC,并非运行云端大模型的工具人,得益于硬件进步,英特尔处理器支持的 PC 已经能够快速对接新兴模型,兼容 HuggingFace 上的 Transformers 模型,目前已经验证过的模型包括但不限于:LLAMA/LLAMA2、ChatGLM/ChatGLM2、MPT、Falcon、MOSS、Baichuan、QWen、Dolly、RedPajama、StarCoder、Whisper 等。
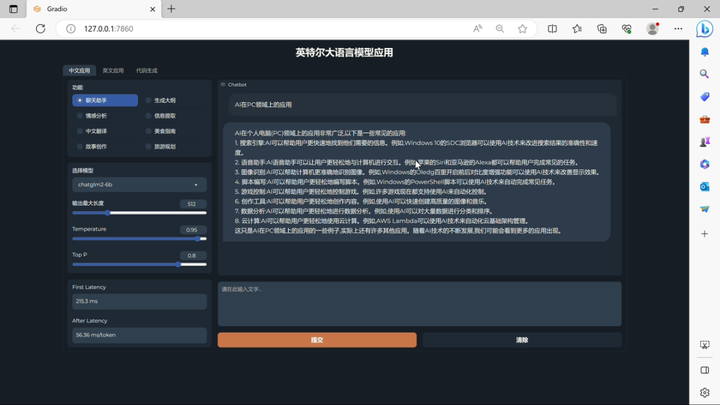
▲ 图片来自:爱极物
在技术分享会现场,英特尔演示了基于酷睿 i7-13700H 设备跑大模型的表现:ChatGLM-6b 可以做到首个 token 生成 first latency 241.7ms,后续 token 平均生成率为 55.63ms/token。在在自然语言处理领域,「token」 是指文本中的一个基本单元,可以是一个单词、一个字、一个子词(subword)、一个标点符号,或者其他可以进行语义处理的最小单元。可以看到,这个处理器速度相当不错。
目前还可以得到的消息是,英特尔的下一代处理器 Meteor Lake 具备独特的分离式模块架构的优势,更好地为 AI 服务,包括像 Adobe Premiere Pro 中的自动重新构图和场景编辑检测等多媒体功能,并实现更有效的机器学习加速。
虽然 AIGC 是 2023 年的一个关键词,但是 AI 并不新鲜,而且也是英特尔这几年来经常挂在嘴边的关键词。
更早之前的 AI 视频通话降噪,AI 视频通话背景降噪等等,其实都是 AI 的应用。
可以看到,未来处理器的竞争力,将不局限于核心数、线程数、主频这些,能否更好地驱动 AI 功能,将成为愈发重要的维度,也会是今后消费者选购产品会考虑的因素之一。





