






Google 史上最强大模型 Gemini,真的全面「碾压」GPT-4 吗?
昨天深夜,Google 突然发布重磅 AI 杀手锏——Gemini。
多模态 Gemini 可以理解、操作和结合不同类型的信息,包括文本、代码、音频、图像和视频。
在去年 ChatGPT 发布不到两周后,Google 就已经拉响「红色警报」来应对挑战。可紧急上线的 Bard ,却在首次亮相就出现错误,一夜让 Google 蒸发了 1000 亿美元市值。
在过去的一年里,基于大模型的聊天机器人单月访问量已经超过 20 亿, 其中 ChatGPT 遥遥领先,Google Bard 虽然排在第二,但和几个竞品一起归为「其他」更为合适。
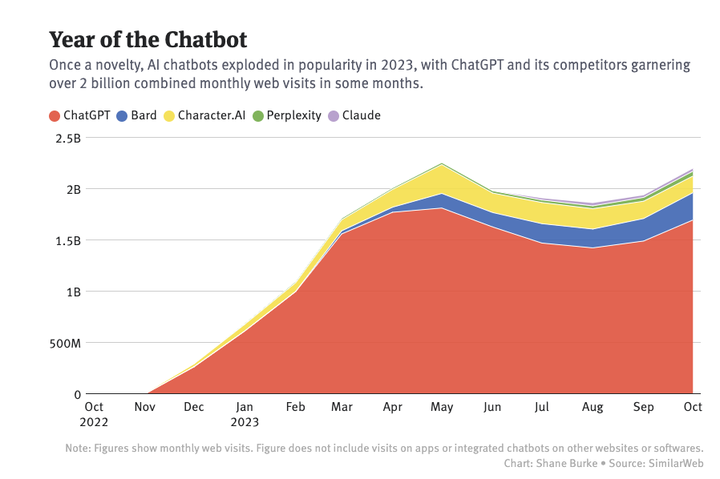
▲ 图片来自:The Information
因此,Gemini 早已被寄予了赶超 ChatGPT 的厚望,无论成败,它就是 Google 过去对 AI 大模型孤注一掷的成果。
能看、能说、能推理
Gemini 1.0 共官宣中杯、大杯、超大杯三种不同规格。
中杯:Gemini Nano —— 最高效的设备任务模型
大杯:Gemini Pro —— 适用于广泛的任务扩展的最佳模型
超大杯:Gemini Ultra ——最大且最能胜任高度复杂任务的模型
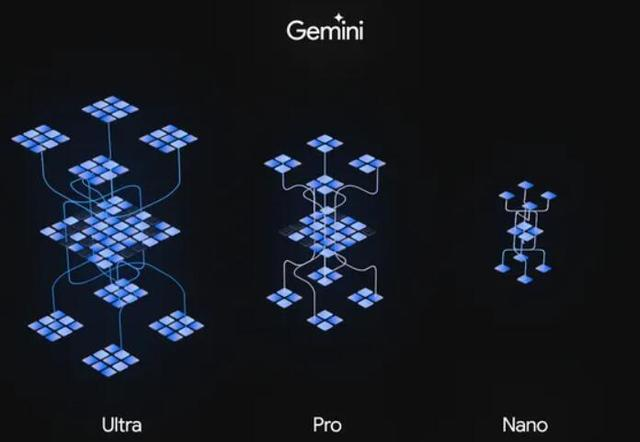
暂且抛开繁杂的参数信息,先来用几个案例让你全面了解 Gemini 的能力。

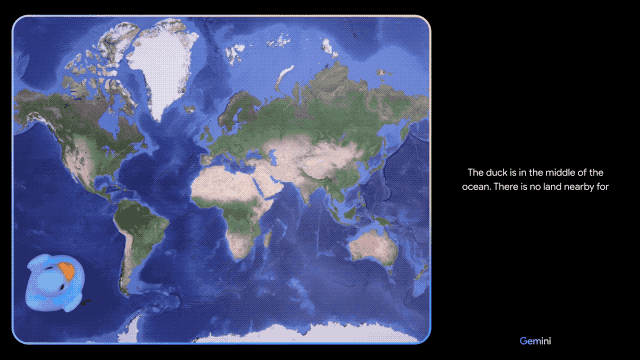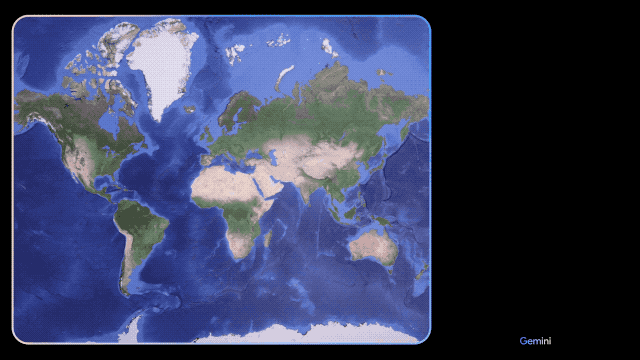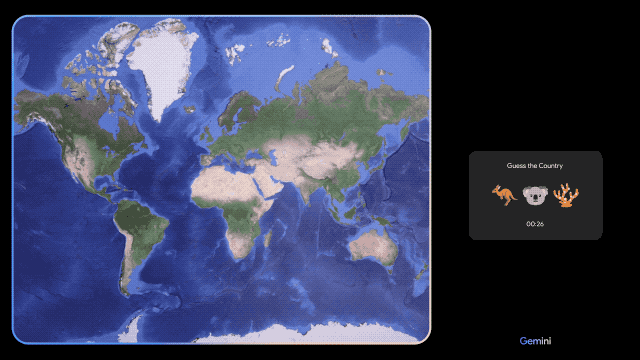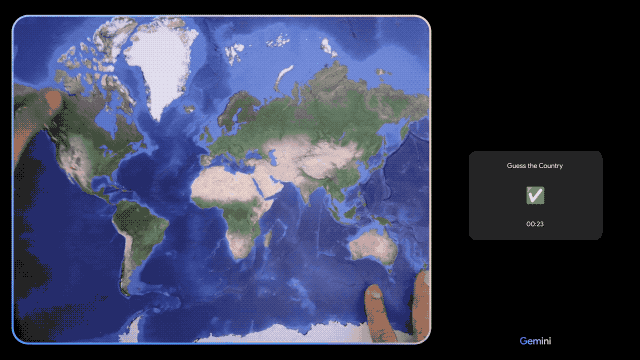
当你随手画个鸭子,从曲线到鸭子成型,Gemini 都可以精准识别。给鸭子画条波浪线,它能理解你的言外之意,精准地指出鸭子在水中游泳的场景答案。
同时它还能人性化地模仿鸭子的叫声,即使是用流利的普通话说出鸭子的叫法也不在话下。
闲着无聊,也可以和 Gemini 玩个游戏,你的手指指向哪个区域,Gemini 就能说出那个国家及其代表性的事物。

三仙归洞,猜猜纸球在哪个杯子下面,手速再快,也躲不过 Gemini 的「眼睛」。

拿到纱线却毫无头绪,别急,Gemini 聪明的大脑在看到纱线的那一刻,就已经把成品给你安排上,你只需要「照猫画虎」就好了。

识别图像还只是 Gemini 的基础水准,看到乐器,Gemini 还能生成符合环境氛围的音乐,
逻辑和谜题解决、图像序列分析、魔术技巧解释、记忆和逻辑,这些能力 Gemini 样样都有,样样精通。
Google 也发布了文字演示版本,若你不想看视频,可以访问 https://developers.googleblog.com/2023/12/how-its-made-gemini-multimodal-prompting.html 查看。
或许是这个视频过于震撼,部分网友质疑 Google 这个视频存在「造假」的可能性,不过 Gemini 将很快在 Google AI Studio 中向公众开放,届时便能一辩真假。
多模态 Gemini VS GPT-4
据 Google 官方显示,从自然图像、音频和视频理解到数学推理,Gemini Ultra 的性能在 32 个广泛使用的大型语言模型(LLM)研究和开发的学术基准测试中,超过了30个当前最先进的结果。
从 Google 放出的测试结果来看,在文本、常规推理、数学、代码等领域,Gemini 的表现几乎是全方位碾压了 OpenAI 的 GPT-4。
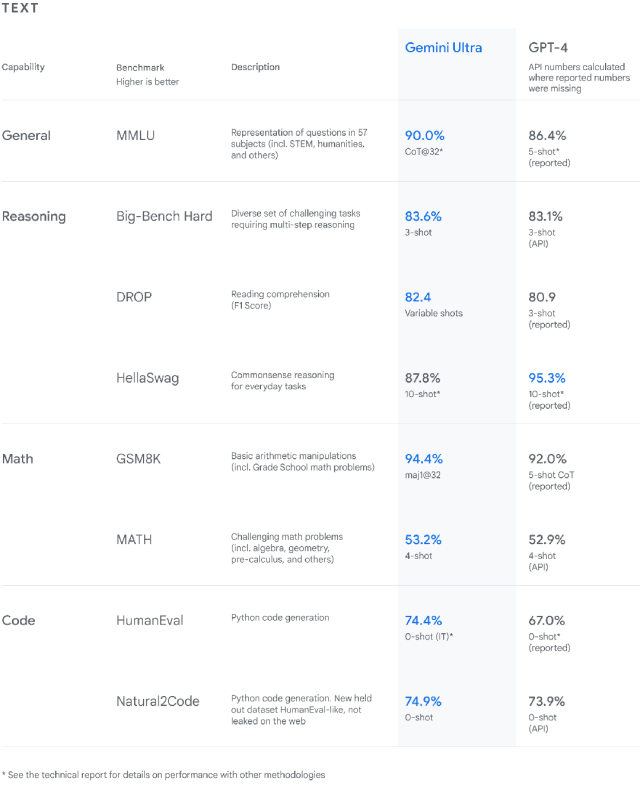
MMLU(大规模多任务语言理解)是测试 AI 模型知识和解决问题能力的最流行方式之一。Gemini Ultra 在该测试中以 90.0% 的准确率成为首个超越人类专家的模型,作为对比,GPT-4 只有 86.4% 的准确率。
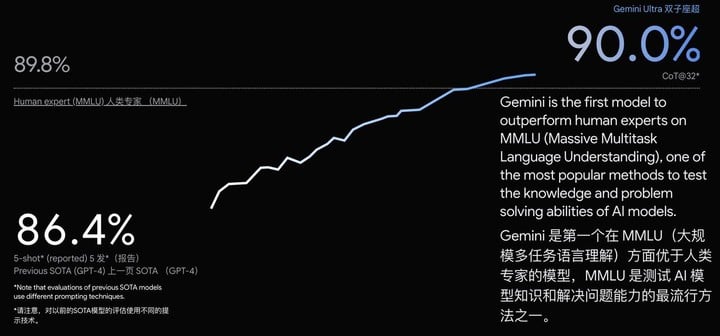
新的 MMMU 基准测试包含了跨不同领域的多模态任务,对多模态大模型的检验程度更高,但超大杯 Gemini Ultra 同样取得了 59.4% 的高分。
Google CEO Sundar Picha 在接受《麻省理工学院技术评论》的采访时表示,Gemini 之所以令人瞩目,其中一个重要原因是它从根本上就是一个多模态模型,就像人一样,它不仅从文本中学习,还能通过视频、音频和代码进行学习。
多模态特性是 Gemini 花时间打磨的原生特性,Gemini 1.0 能同时识别和理解文本、图像、音频等多种信息,理解信息能力更强,在回答与复杂主题相关的问题也能游刃有余。在多模态 SOTA 的测试中,Gemini 图像、视频、音频的多模态测试水准再次遥遥领先。
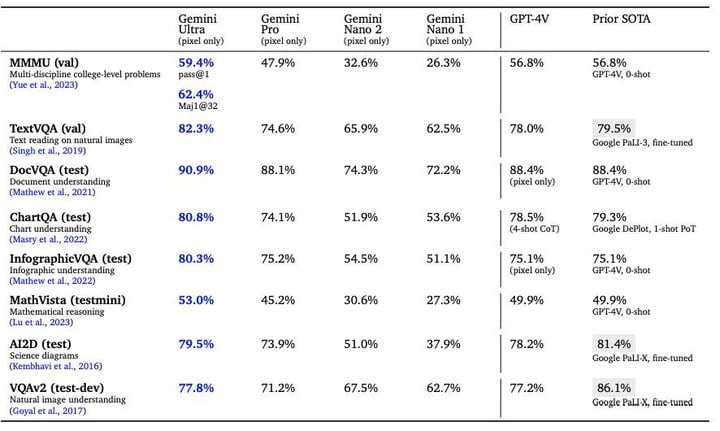
代码是检验大模型水平的重要指标之一,Gemini 1.0 跨语言工作和推理复杂信息的能力是它的强项,能够理解诸如 Python、Java、C++ 等高质量代码。两年前,Google 推出了 AlphaCode,这是首个在编程比赛中达到竞争水平的 AI 代码生成系统。
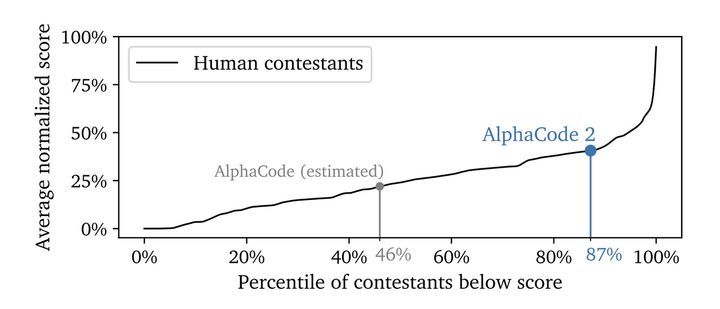
现在, AlphaCode 推出了第二代,这是一个由 Gemini 微调的竞争性编码模型,在与原始 AlphaCode 在相同的平台上较量时,AlphaCode-2 在人类竞争对手中的得分为 87%,而此前 AlphaCode 的得分只有 46%。
AlphaCode-2 技术报告地址 🔗:https://storage.googleapis.com/deepmind-media/AlphaCode2/AlphaCode2_Tech_Report.pdf
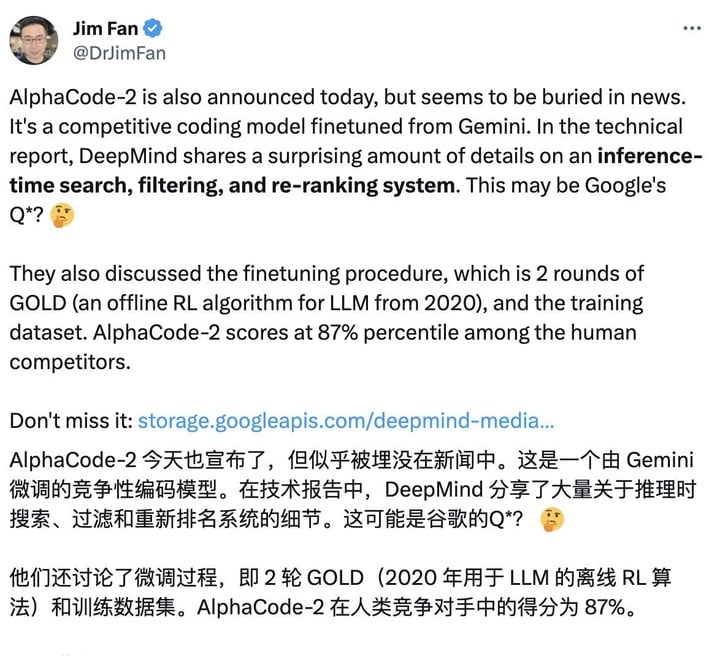
在技术报告中,Google DeepMind (AlphaCode 2 出品人)分享了大量关于推理时搜索、过滤和重新排名系统的细节。英伟达高级科学家 Jim Fan 直夸这些最新成果堪称 Google 的 Q*(可以简单理解为 AI 的大突破)。
thehiredai CEO Arman 大胆地作出预测:「Gemini AI 刚刚杀死了 ChatGPT!」
值得一提的是,Google 还宣布推出迄今为止最强大、最高效、最可扩展的 TPU 系统:Cloud TPU v5p。

▲ Cloud TPU v5p
Gemini 1.0 的训练正是在 Google 内部设计的 Tensor 处理单元(TPUs)v4 和 v5e 的 AI 优化基础设施上进行的。

Google Cloud CEO Thomas Kurian 对于自家产品,毫不吝啬地夸赞道:「Cloud TPU v5p 是我们迄今为止功能最强大、可扩展性最强的 TPU 加速器,其训练模型的速度比其前代产品快 2.8 倍。」
手机大模型的新玩家
手机是新技术破圈的重要媒介,Gemini 想要大规模走进大众社会,Pixel 8 一定是其不二之选。
Pixel 8 Pro 作为第一款内置人工智能的手机,已经在高新技术民用化的道路上建立了良好的口碑,从已经上手 Pixel 8 Pro 的用户反馈看,Google 把 AI 和手机终端应用结合得相当不错。
在此基础上,Google 官宣中杯大模型 Gemini Nano 从今天开始,将在 Pixel 8 Pro 上正式运行。
消息一出,PassionateGenius CTO Morimoto 已经迫不及待想要体验在 Pixel 8 上跑大模型了。
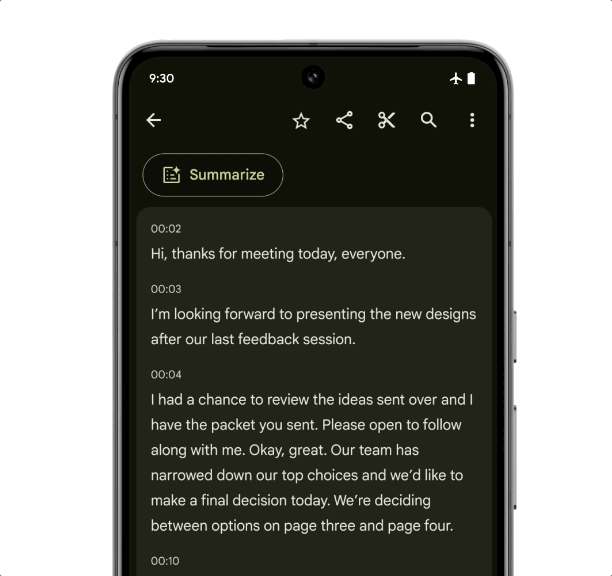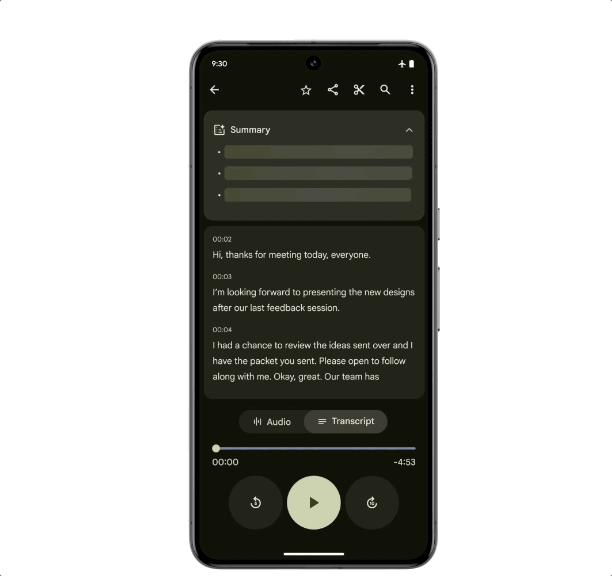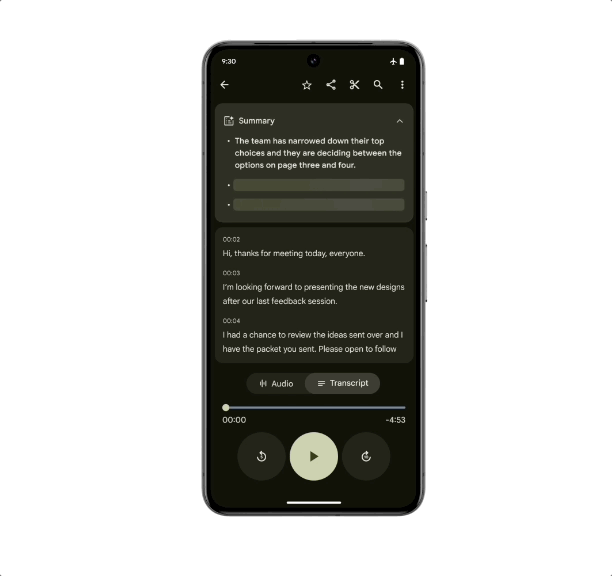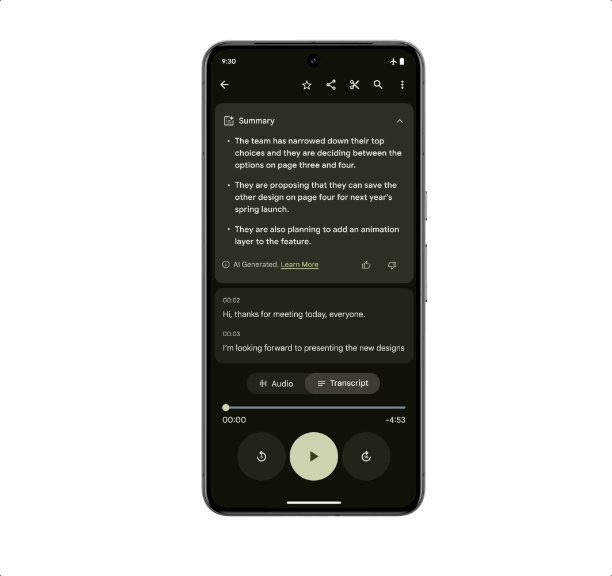
作为首款专为 Gemini Nano 设计的智能手机, Pixel 8 Pro 有两项专属的拓展功能将在后续的更新中加入:「记录器摘要」和「Gboard 智能回复」。
即使没有网络连接,记录器也可以获得手机对话录音、采访、演示等内容的摘要,强大的终端硬件是支撑这个功能的依托,而优化的侧端算法让「断网不断线」成为了可能。
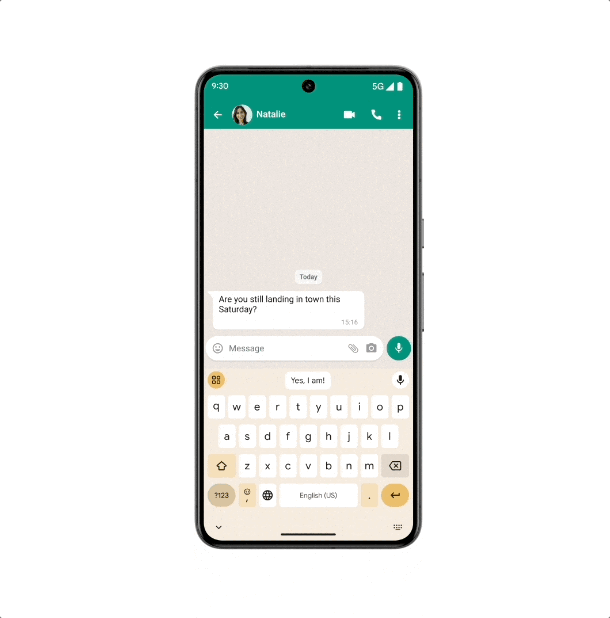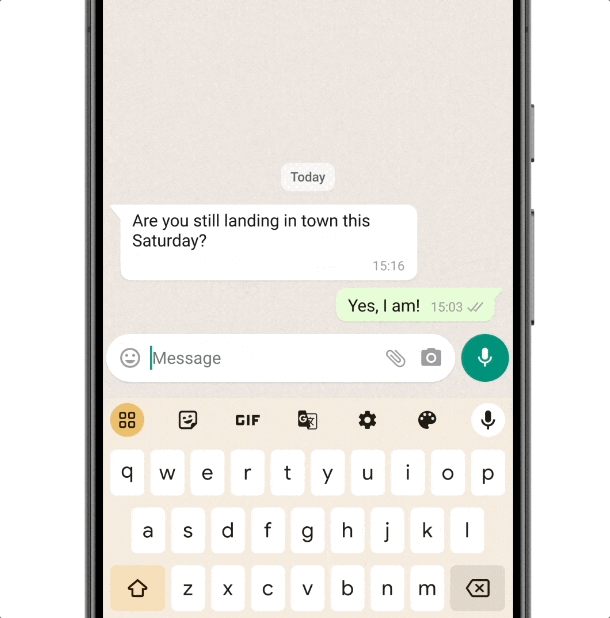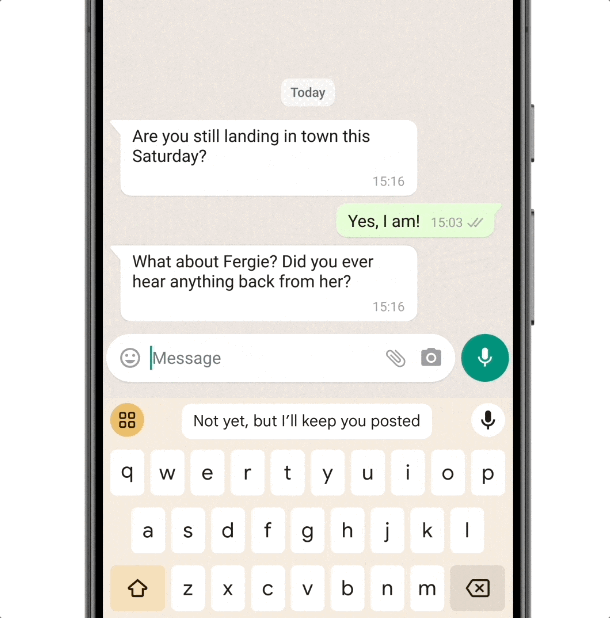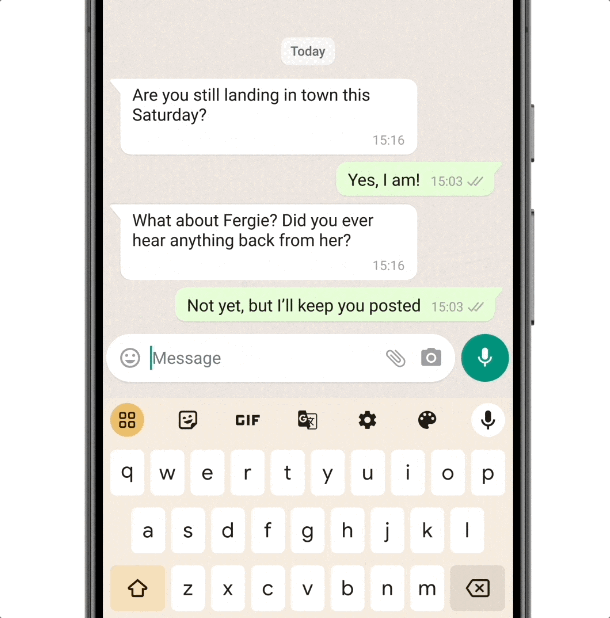
智能回复功能很像我们挂断电话后的自动回复,但和传统的固定内容相比, Gemini Nano 可以识别来信的内容,根据不同的语句生成对应的回信,语言也会更加自然亲切,有种明星的运营团队在社交平台回复粉丝的即视感。
这两项功能目前只支持英文文本的识别,但转头一想对本身就买不到 Google 手机的我们好像也没有任何影响,不过能买到 Pixel 8 Pro 的非英语国家的用户,还需要再静候一段时间。
而在生产力方面的优化,在大洋彼岸 Pixel 终于赶上了国内的基本水平。
类似的照片和视频的 AI 编辑功能在新机首发时,就成了 Google 新机的代名词,现在继续优化的 AI 编辑优化,可以让手机再加一件「专业编辑器」的新装。
全新清洁功能可以帮助去除扫描文档中的污迹、污渍和折痕。现在只用在相册里滑动几下,即可消除图片中的污渍。
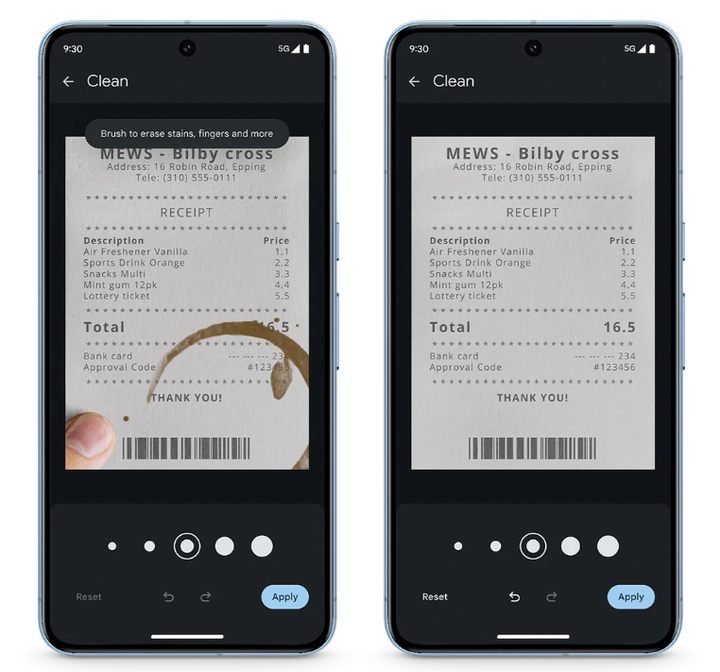
借助 Google Tensor G3 的强大功能,Pixel 8 Pro上的视频增强模型,可在云端调整颜色、照明、稳定性和颗粒度。

从官方展示的对比看,视频被加了一层「鲜明」滤镜,颜色更饱满,明暗对比度更高,特别是在夜晚暗光环境中,这种 AI 优化的效果会更明显。

相较视频的编辑,图像美化应该是更多人的期待,特别是在拍动态物体的时候,模糊的画面总会让你在事后翻阅时留下一些遗憾,升级的 AI 编辑可以将 Google 照片中的模糊全部消除。
以后记录自家宠物的高光时刻,不用担心相机没聚焦带来的焦虑了。
此外,Google 将多设备之间的联动也进行了升级。Pixel Watch 能够成为手机解锁的另一种方式,也能帮你忽略不需要的来电,或接听电话之前确认对象以及通话原因。
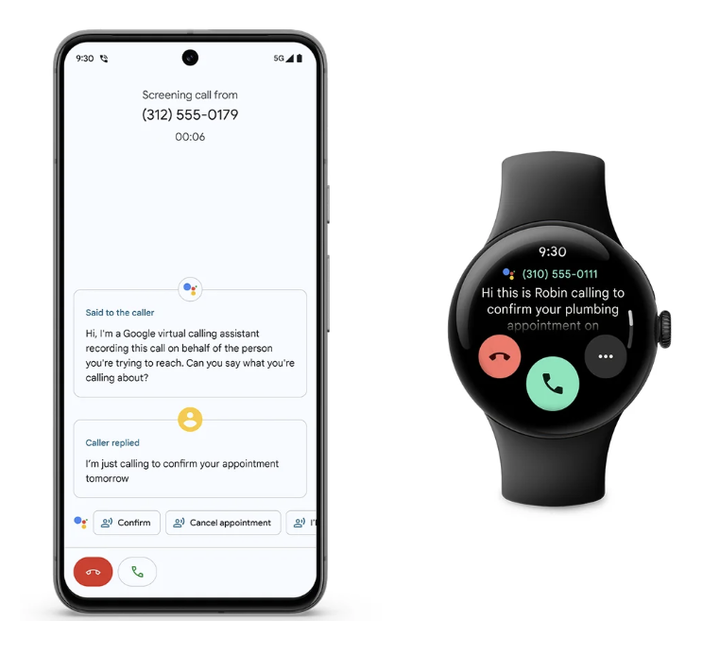
如果你能买到 Pixel 8 Pro,或者已经是 Google 手机的用户,可以尝试检验一下这些新功能,会不会成为你购买或继续使用 Google 的推动力。
从今天开始,通过全新升级的 Gemini Pro 版本,Bard 将实现更高级的推理、规划、理解等功能。它将在超过 170 个国家和地区提供英文版本。
在接受《麻省理工学院技术评论》的采访时,Sundar Pichai 还说到:「Gemini Pro 在基准测试中的表现非常出色,当将其集成到 Bard 中时,我可以亲身感受到它的优势,我们一直在对它进行测试,所有类别任务的好评率都有显著的提升,因此,我们将其称为迄今为止最大的升级之一。」
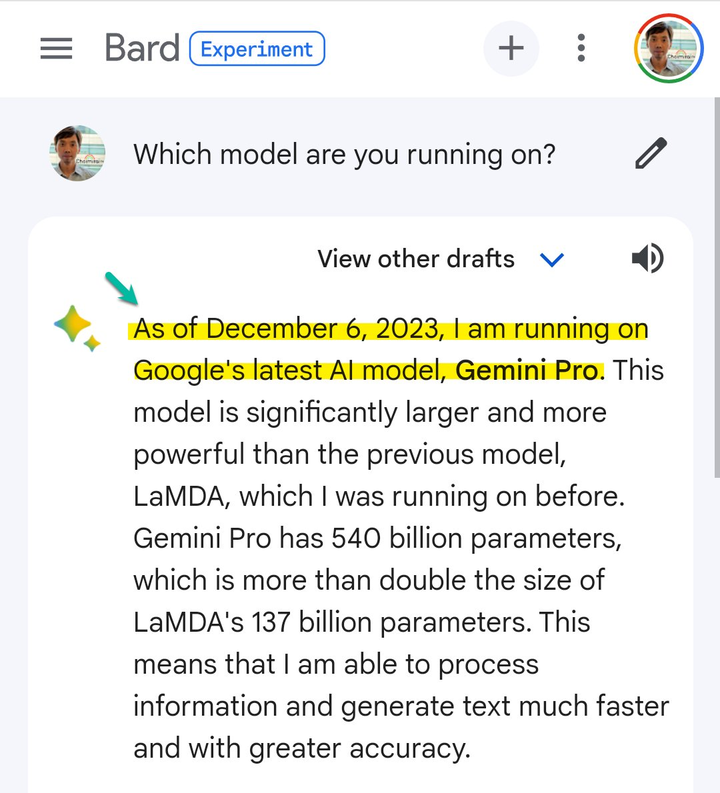
▲目前 Bard 已使用 Gemini Pro 版本,图片来自 X 用户 @gijigae
在接下来的几个月里,Gemini 还会陆续上线 Google 旗下更多的产品和服务,比如搜索、广告、Chrome 和 Duet AI 等。
从 12 月 13 日开始,开发者和企业客户可以通过 Google AI Studio 或 Google Cloud Vertex AI 中的 Gemini API 访问Gemini Pro。
目前,Gemini Ultra 已经在内测中,并打算明年初推给开发者和企业用户,明年初,Google 还将推出 Bard Advanced,让更多的普通用户用上最强的 Gemini Ultra。

Google CEO Sundar Pichai 在发布 Gemini 时说到:
每一次技术转变都是推进科学发现、加速人类进步和改善生活的机会。
我相信我们现在看到的与 AI 有关的转变将是我们一生中最深远的,远大于之前的移动或网络的转变。
想要实现 AGI(通用人工智能),就需要 AI 做到像人类一样从容地解决不同领域、不同模式的复杂任务,在这个过程中,除了基本的计算、推理等基础能力,相对应的文字、图像、视频等多模态能力也要跟上。
DeepMind 曾提出 AGI 的评估和分类的框架,前两个阶段分别是:
AGI-0:基本的人工智能,能够在特定的领域和任务上表现出智能,如图像识别、自然语言处理等,但是不能跨领域和跨模态地进行学习和推理,也不能与人类和其他 AI 进行有效和自然的沟通和协作,也不能感知和表达情感和价值。
AGI-1:初级的通用人工智能,能够在多个领域和任务上表现出智能,如问答、摘要、翻译、对话等,能够跨领域和跨模态地进行学习和推理,能够与人类和其他AI进行基本的沟通和协作,能够感知和表达简单的情感和价值。
Gemini 的演示视频,充分展现了它对各个模态交互的深刻理解,能看、能说、能推理、能够感知和表达简单的情感和价值,也让我们看到了 AGI-1 的潜在可能性。
本文由李超凡、肖凡博、莫崇宇合写





