






最全攻略!OpenAI 发布 GPT-4 使用指南,所有干货全在这
ChatGPT 诞生以来,凭借划时代的创新,被无数人一举送上生成式 AI 的神坛,
我们总是期望它能准确理解我们的意图,却时常发现其回答或创作并非百分之百贴合我们的期待。这种落差可能源于我们对于模型性能的过高期望,亦或者我们在使用时未能找到最有效的沟通途径。
正如探险者需要时间适应新的地形,我们与 ChatGPT 的互动也需要耐心和技巧,此前 OpenAI 官方发布了 GPT-4 使用指南 Prompt engineering,这里面记载了驾驭 GPT-4 的六大策略。
相信有了它,未来你和 ChatGPT 的沟通将会更加顺畅。
简单总结一下这六大策略:
- 写出清晰的指令
- 提供参考文本
- 将复杂的任务拆分为更简单的子任务
- 给模型时间「思考」
- 使用外部工具
- 系统地测试变更
写出清晰的指令
描述详细的信息
ChatGPT 无法判断我们隐含的想法,所以我们应该尽可能明确告知你的要求,如回复的长短、写作的水平、输出的格式等。
越少让 ChatGPT 去猜测和推断我们的意图,输出结果满足我们要求的可能性越大。例如,当我们让他写一篇心理学的论文,给出的提示词应该长这样 👇
请帮助我撰写一篇有关「抑郁症的成因及治疗方法」的心理学论文,要求:需要查询相关文献,不能抄袭或剽窃;需要遵循学术论文格式,包括摘要、引言、正文、结论等部分;字数 2000 字以上。

让模型扮演某个角色
术业有专攻,指定模型扮演专门的角色,它输出的内容会显得更加专业。
例如:请你扮演一名警探小说家,用柯南式推理描述一起离奇命案。要求:需匿名处理,字数 1000 字以上,剧情跌宕起伏。
使用分隔符清楚地划分不同部分
三引号、XML 标签、节标题等分隔符可以帮助划分需要区别对待的文本节,帮助模型更好地消除歧义。

指定完成任务所需的步骤
将部分任务拆成一系列条例清晰的步骤,这样更有利于模型执行这些步骤。

提供示例
提供适用于所有示例的一般性说明通常比通过示例演示更有效,但在某些情况下提供示例可能更容易。
举个例子,如果我告诉模型要学会游泳,只需要踢腿和摆动手臂,这就是一个一般性的说明。而如果我给模型展示一个游泳的视频,展示踢腿和摆动手臂的具体动作,那就是通过示例来说明。
指定输出长度
我们可以告诉模型,希望它生成的输出有多长,这个长度可以以单词、句子、段落、要点等方式进行计数。
受限于模型内部机制和语言复杂性的影响,最好还是按照段落、要点来划分,这样效果才会比较好。
提供参考文本
让模型使用参考文本回答
假如我们手头上有更多参考信息,那我们可以「喂」给模型,并让模型使用提供的信息来回答。

让模型引用参考文本来回答
如果输入中已经包含了相关的知识文档,用户可以直接要求模型通过引用文档中的段落来为其答案添加引用,尽可能减少模型胡说八道的可能性。
在这种情况下,输出中的引用还可以通过编程方式验证,即通过对所提供文档中的字符串进行匹配来确认引用的准确性。

将复杂的任务拆分为更简单的子任务
使用意图分类来识别与用户查询最相关的指令
处理那些需要很多不同操作的任务时,我们可以采用一个比较聪明的方法。首先,把问题分成不同的类型,看看每一种类型需要什么操作。这就好像我们在整理东西时,先把相似的东西放到一起。
接着,我们可以给每个类型定义一些标准的操作,就像给每类东西贴上标签一样,这样一来,就可以事先规定好一些常用的步骤,比如查找、比较、了解等。
而这个处理方法可以一层层地递进,如果我们想提出更具体的问题,就可以根据之前的操作再进一步细化。
这么做的好处是,每次回答用户问题时,只需要执行当前步骤需要的操作,而不是一下子把整个任务都做了。这不仅可以减少出错的可能性,还能更省事,因为一次性完成整个任务的代价可能比较大。

对于需要处理很长对话的应用场景,总结或过滤之前的对话
模型在处理对话时,受制于固定的上下文长度,不能记住所有的对话历史。
想要解决这个问题,其中一种方法是对之前的对话进行总结,当输入的对话长度达到一定的限制时,系统可以自动总结之前的聊天内容,将一部分信息作为摘要显示,或者,可以在对话进行的同时,在后台悄悄地总结之前的聊天内容。
另一种解决方法是在处理当前问题时,动态地选择与当前问题最相关的部分对话。这个方法涉及到一种叫做「使用基于嵌入的搜索来实现高效的知识检索」的策略。
简单来说,就是根据当前问题的内容,找到之前对话中与之相关的部分。这样可以更有效地利用之前的信息,让对话变得更有针对性。
分段总结长文档并递归构建完整摘要
由于模型只能记住有限的信息,所以不能直接用来总结很长的文本,为了总结长篇文档,我们可以采用一种逐步总结的方法。
就像我们阅读一本书时,可以通过一章又一章地提问来总结每个部分。每个部分的摘要可以串联起来,形成对整个文档的概括。这个过程可以一层一层地递归,一直到总结整个文档为止。
如果需要理解后面的内容,可能会用到前面的信息。在这种情况下,另一个有用的技巧是在阅读到某一点之前,先看一下摘要,并了解这一点的内容。
给模型时间「思考」
指示模型在急于得出结论之前想出自己的解决方案
以往我们可能直接让模型看学生的答案,然后问模型这个答案对不对,但是有时候学生的答案是错的,如果直接让模型判断学生的答案,它可能判断不准确。
为了让模型更准确,我们可以先让模型自己做一下这个数学题,先算出模型自己的答案来。然后再让模型对比一下学生的答案和模型自己的答案。
先让模型自己算一遍,它就更容易判断出学生的答案对不对,如果学生的答案和模型自己的答案不一样,它就知道学生答错了。这样让模型从最基本的第一步开始思考,而不是直接判断学生的答案,可以提高模型的判断准确度。

使用内心独白来隐藏模型的推理过程
有时候在回答特定问题时,模型详细地推理问题是很重要的。但对于一些应用场景,模型的推理过程可能不适合与用户共享。
为了解决这个问题,有一种策略叫做内心独白。这个策略的思路是告诉模型把原本不想让用户看到的部分输出整理成结构化的形式,然后在呈现给用户时,只显示其中的一部分,而不是全部。
例如,假设我们在教某个学科,要回答学生的问题,如果直接把模型的所有推理思路都告诉学生,学生就不用自己琢磨了,
所以我们可以用「内心独白」这个策略:先让模型自己完整地思考问题,把解决思路都想清楚,然后只选择模型思路中的一小部分,用简单的语言告诉学生。
或者我们可以设计一系列的问题:先只让模型自己想整个解决方案,不让学生回答,然后根据模型的思路,给学生出一个简单的类似问题,学生回答后,让模型评判学生的答案对不对。
最后模型用通俗易懂的语言,给学生解释正确的解决思路,这样就既训练了模型的推理能力,也让学生自己思考,不会把所有答案直接告诉学生。

询问模型在之前的过程中是否遗漏了任何内容
假设我们让模型从一个很大的文件里,找出跟某个问题相关的句子,模型会一个一个句子告诉我们。
但有时候模型判断失误,在本来应该继续找相关句子的时候就停下来了,导致后面还有相关的句子被漏掉没有告诉我们。
这个时候,我们就可以提醒模型「还有其他相关的句子吗」,接着它就会继续查询相关句子,这样模型就能找到更完整的信息。
使用外部工具
使用基于嵌入的搜索实现高效的知识检索
如果我们在模型的输入中添加一些外部信息,模型就能更聪明地回答问题了。比如,如果用户问有关某部电影的问题,我们可以把电影的一些重要信息(比如演员、导演等)输入到模型里,这样模型就能给出更聪明的回答。
文本嵌入是一种能够度量文本之间关系的向量。相似或相关的文本向量更接近,而不相关的文本向量则相对较远,这意味着我们可以利用嵌入来高效地进行知识检索。
具体来说,我们可以把文本语料库切成块,对每个块进行嵌入和存储。然后,我们可以对给定的查询进行嵌入,并通过矢量搜索找到在语料库中最相关的嵌入文本块(即在嵌入空间中最接近查询的文本块)。
使用代码执行来进行更准确的计算或调用外部 API
语言模型并不总是能够准确地执行复杂的数学运算或需要很长时间的计算。在这种情况下,我们可以告诉模型写一些代码来完成任务,而不是让它自己去做计算。
具体做法是,我们可以指导模型把需要运行的代码按照一定的格式写下,比如用三重反引号包围起来。当代码生成了结果后,我们可以提取出来并执行。
最后,如果需要,可以把代码执行引擎(比如 Python 解释器)的输出当作模型下一个问题的输入。这样就能更有效地完成一些需要计算的任务。

另一个很好的使用代码执行的例子是使用外部 API(应用程序编程接口)。如果我们告诉模型如何正确使用某个 API,它就可以写出能够调用该 API 的代码。
我们可以给模型提供一些展示如何使用 API 的文档或者代码示例,这样就能引导模型学会如何利用这个 API。简单说,通过给模型提供一些关于 API 的指导,它就能够创建代码,实现更多的功能。

警告:执行由模型生成的代码本质上是不安全的,任何尝试执行此操作的应用程序都应该采取预防措施。特别是,需要使用沙盒代码执行环境来限制不受信任的代码可能引起的潜在危害。
让模型提供特定功能
我们可以通过 API 请求,向它传递一个描述功能的清单。这样,模型就能够根据提供的模式生成函数参数。生成的函数参数将以 JSON 格式返回,然后我们再利用它来执行函数调用。
然后,把函数调用的输出反馈到下一个请求中的模型里,就可以实现一个循环,这就是使用 OpenAI 模型调用外部函数的推荐方式。
系统地测试变更
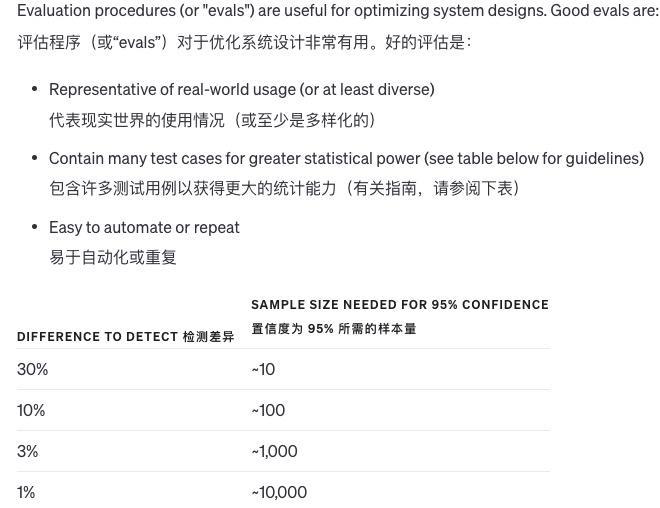
当我们对一个系统做修改时,很难判断这些修改是好是坏。因为例子太少,很难确定结果是真的改进了还是运气好。有时候一个修改在某些情况下是好的,在其他情况下是坏的。
那么我们如何评价系统输出的质量呢?如果问题只有一个标准答案,计算机可以自动判断对错。如果没有标准答案,可以用其他模型来判断质量。
此外,我们也可以让人工来评价主观的质量,又或者计算机和人工结合评价当问题的答案很长时,不同的答案质量差别不大,这时就可以让模型自己来评价质量。
当然,随着模型变得更先进,可以自动评价的内容会越来越多,需要人工评价的越来越少,评价系统的改进非常难,结合计算机和人工是最好的方法。
参考黄金标准答案评估模型输出
假设我们面对一个问题,需要给出答案。我们已经知道这个问题的正确答案,是基于一些事实的。比如问题是「为什么天空是蓝色的」,正确答案可能是「因为阳光通过大气层的时候,蓝色光波段的光比其他颜色通过得更好」。
这个答案就是基于以下事实:
阳光包含不同颜色(光波段)
蓝色光波段通过大气层时损耗较小
有了问题和正确答案后,我们可以用模型(比如机器学习模型)来判断,答案中的每一部分事实对于答案正确的重要性。
比如通过模型判断出,答案中「阳光包含不同颜色」这一事实对于答案的正确性非常重要。而「蓝色光波段损耗较小」这一事实,对于答案也很重要。这样我们就可以知道,这个问题的答案依赖于哪些关键的已知事实。

在和 ChatGPT 人机交流的过程中,提示词看似简单,却又是最为关键的存在,在数字时代,提示词是拆分需求的起点,通过设计巧妙的提示词,我们可以将整个任务拆分成一系列简明的步骤。
这样的分解不仅有助于模型更好地理解用户的意图,同时也为用户提供了更为清晰的操作路径,就好像给定了一个线索,引导我们一步步揭开问题的谜底。
你我的需求如同涌动的江河,而提示词就像是调节水流方向的水闸,它扮演着枢纽的角色,连接着用户的思维与机器的理解。毫不夸张地说,一个好的提示词既是对用户深度理解的洞察,也是一种人机沟通的默契。
当然,要想真正掌握提示词的使用技巧,仅依靠 Prompt engineering 还远远不够,但 OpenAI 官方的使用指南总归给我们提供了宝贵的入门指引。





