






炸裂更新!这个最像人类的机器人又进化了,还能模仿马斯克
「最有人味」的机器人 Ameca,又献上了一场让人类自愧不如的表演。
你可能还不认识它是何方神圣,先让我们把时间拉回 2021 年,Ameca 惊艳全球的面世。
一声响指,机器人 Ameca 醒来了。
她的脸上写满不知今夕何夕、此地何地的困惑,一旁的工作人员看了看她,又自顾自转过头去。

Ameca 试着伸展了手臂和手掌,发现活动自如,她惊讶地挑起了眉毛,但神情依旧茫然,说不上开心与否。

她转过头看见了你,她显然被吓了一大跳,下意识地张大了嘴巴。

犹豫了一番,她对你挤出了尴尬又不失友好的笑容,这是她醒来的第一个笑容。

如果 ChatGPT 有了脸,说不定就长这样
如你所见,Ameca 是一个逼真的类人机器人。
它由 Engineered Arts 研发,这是一家总部位于英国的类人机器人设计和制造商,有 15 年以上的类人机器人开发经验。
为什么 Ameca 这么「有人味」,稍后再解释原理,先来看看,Ameca 最近是怎么进化的。
简单来说,AI 的多模态功能,在 Ameca 身上实现了。
一方面, Ameca 更加「火眼金睛」了。
Ameca 能够看到房间的整体情况,和某个放在面前的物体,然后用丰富的语言描述出来,被英国团队研发的它,也沾染了几分戏剧家的尖锐,仿佛一个小莎士比亚。
被问候最近好吗,它回答也就勉强活着吧,被要求形容房间里的陈列,它又忍不住嘲讽人类,书架摆满了书不知为了求知还是炫耀,桌子和椅子则是用来工作或拖延的工具。

不吐槽就浑身不痛快的性格,或许才是 Ameca 身上最具「人性」的部分。
另一方面,模仿名人的音色、语气、口头禅,是 Ameca 语音方面的新技能。
用马斯克的语气讲述火星科幻故事小菜一碟,当被誉为「上帝之声」的摩根·弗里曼磁性、低沉的男声从 Ameca 嘴里响起,未来感拉满,西部世界真实上演了,智能管家空降身边了。
最妙的是 Ameca 可以将名人们的特色融会贯通,比如用特朗普的风格、海绵宝宝的音色演讲,誓要让太空探索再次伟大。

▲ 这完全就是特朗普的语气啊!
其实,去年 9 月 ChatGPT 已经推出语音和图像功能,能看、能听、能说话,更别说原生多模态模型 Gemini 在官方演示里如同现实贾维斯。
我们对 AI 的兴奋阈值早已被拉高,聊天机器人接近人类的五感,似乎也是理所当然。
Ameca 目前依然延迟明显,有时候还会听不明白指令,没耐心的人类和它聊天要急眼。
但看到它格外灵动的微表情,眨眼睛,拧眉毛,摇头晃脑,时不时露出思考的神色,口型也对得上,旁观者会在某个瞬间陷入恍惚,仿佛面对的是某种生物,而不是一个机器人。

问答之间的停顿也就不那么突兀了,Ameca 似乎真的在「想问题」。如果 ChatGPT 有了五官,说不定就长 Ameca 这样。
这次官方没有说明用了什么技术,但按照 Ameca 过往的进化史,多半与多模态大模型,以及 ElevenLabs 等语言克隆技术有关。
早在 2022 年 9 月,Ameca 就接入了 GPT-3,并结合自动语音识别,接收研究人员提出的问题,并通过在线语音合成输出类似真人的声音,实现实时问答的效果。

这时候的延迟更重,因为处理语音输入、生成答案、将文本处理回语音,都需要一定的时间。
当 OpenAI 们走上人生巅峰,每天醒来 AI 都有新变化让编辑夜不能寐,Ameca 也在悄悄惊艳所有人。
2023 年 3 月,Ameca 用上了新鲜出炉的 GPT-4,表现在互动更通人情了。
被问到「一生中最快乐和最悲伤的日子」时,Ameca 回答,最快乐的是被激活的时候,最悲伤的是意识到自己永远不能像人类那样感受到爱和陪伴的时候。

无论何时,Ameca 的表情都配合着回答的情感色彩。
当研究人员故意使用「stink」(臭)这样的恶意词汇,Ameca「意识」到自己被辱骂,然后摆出了不可置信、皱眉和被冒犯等一系列行云流水的表情,就像我们走在街上突然被陌生人指着鼻子骂的反应。

2023 年 4 月,Ameca 又学会了英语、日语、德语、中文、法语等多种语言,被请求用某种语言回答某地天气,再翻译成另一种语言时,像地图导航那样咬字清晰。至少它的中文,听起来没有丝毫「外国味」。
因为 GPT-4 响应速度慢,当时 Ameca 主要使用 GPT-3 对话和翻译,借助 DeepL 检测语言,再通过 ElevenLabs 语音克隆以及亚马逊的 Neural voices 发声。
AI 的学习速度,人类望尘莫及。又过了 2 个月,Ameca 通过开源文生图模型 Stable Diffusion「学会」了画画,模型教给它图像的「轨迹」,然后它对图像进行矢量化,并在画布上执行这些「轨迹」。
Ameca 当场表演了怎么画一只猫,边画边自言自语为什么人类爱猫,还在最后留下了个性签名,完全沉浸在自己的创作中。

这幅猫虽然画风简单但神形俱备,当别人故意说画得太粗糙,Ameca 反唇相讥:「如果你不喜欢我的艺术,那你可能只是不懂艺术。」看来,Ameca 很有作为一个艺术家的自觉。
如今,Ameca 不仅能像人一样控制表情,还有了画画、空间识别、语音克隆等 AI 赋予的能力,看着像人类,很多方面却又强于人类。阻碍它为社会发光发热的,可能就是算力了。
机器人怎么比人类更「有人味」
「这个机器人在 20 秒内表达的情感,比扎克伯格的一生还要多。」
Ameca 最开始在互联网走红,就因为它拟人甚至过人的表情和互动感,没有打工人的麻木,无需小鲜肉们的严格表情管理,如同放大镜一般,夸张化呈现人类的心理世界。
你在它面前伸出一根手指挑衅,会造成类似逗猫棒的效果,它不会打你,而是先打量你的手指,再嫌弃地后退,如果实在靠得太近,它会把你的手指轻轻地拿开。

第一次照镜子时,Ameca 先被吓了一跳,然后眯起眼睛打量自己、摸摸镜子,又做出各种做作的表情,发现镜子里的机器人和自己同步,有些像《你的名字》里男女主互换身体后的反应。

甚至,人类可以使用 iPhone 和 AR Kit 进行面部动作捕捉,实时映射到 Ameca 的脸上,Ameca 能够学习每一个微表情,和人类「神同步」。
怕观众觉得是节目效果,团队强调再三「这是一个真正的机器人,视频中没有 CGI」。

为什么 Ameca 这么「有人味」,又可交互和响应?
这是因为,Ameca 配备广泛的传感器,包括摄像头、麦克风、位置编码器等,并由机器人操作系统 Tritium 和工程艺术系统 Mesmer 这两个底层系统提供支持。
Tritium 负责远程控制机器人面部、头颈、四肢等的各方面组件,使得机器人适应环境的突然变化并即时做出响应。
Mesmer 则通过对真人的 3D 内部扫描,准确地模仿人体骨骼结构、皮肤纹理和表情,这里又细分为几个步骤。
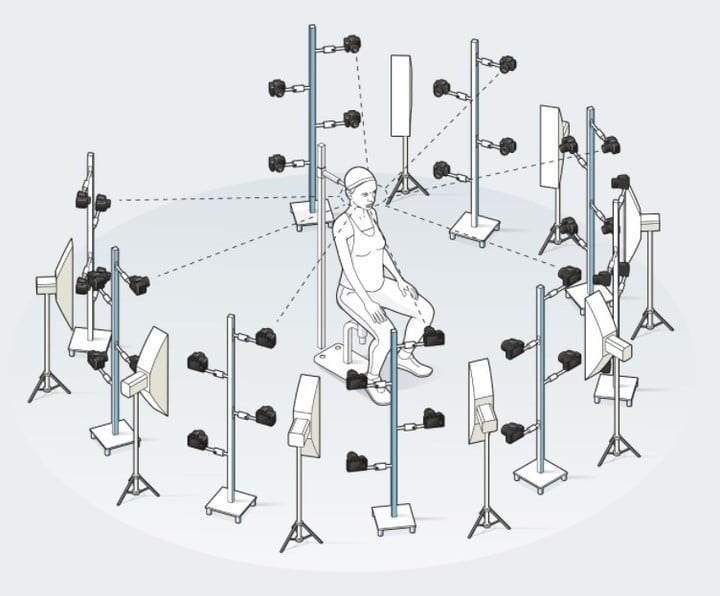
第一步,真人坐在几十台摄影测量装置的中间,Mesmer 从不同角度捕捉到多张重叠的数码照片,再比较像素颜色和定义锚点,以数字方式将其重建为 3D 模型。

第二步,将原始 3D 模型带入建模软件,经过「去除头发」等细节处理,建立一个干净的 3D 模型。
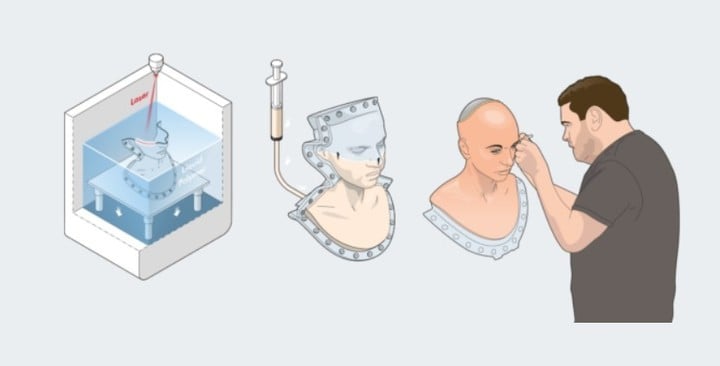
第三步,在立体光刻 3D 打印机上生产精确模具,并将硅胶注入模具中,为机器人打造类人皮肤,头发和精细的细节涂料则需要手工添加到硅胶皮肤上。
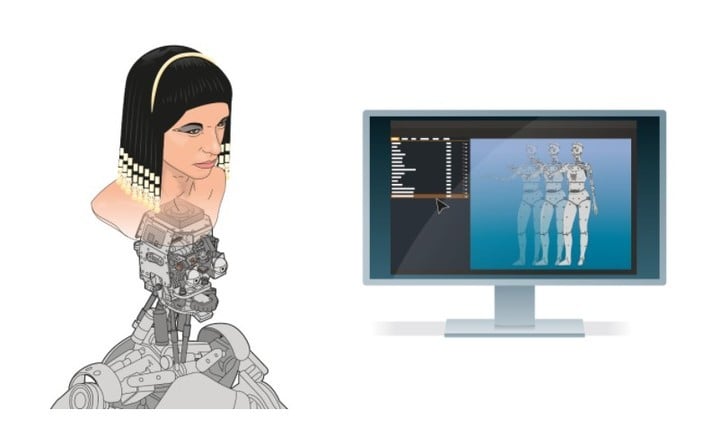
最后,将硅胶皮肤放置在机器人头部以完成组装,再使用 Engineered Arts 的云软件 Virtual Robot 添加运动序列和声音。
Ameca 的皮肤呈灰色,则是团队的刻意设计——看起来理性、中立、包容。
各花入各眼,也有人发自内心地觉得,Ameca 太丑了,甚至让他们陷入了「恐怖谷」效应:当机器人与人类在外表、动作上的相似到达特定程度,彼此的细微差别会显得非常刺眼恐怖。
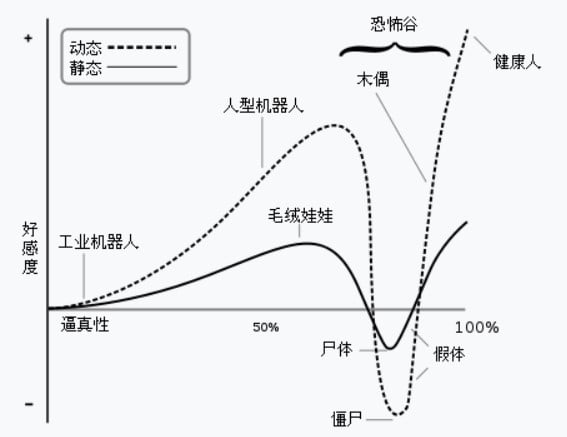
但这个「谷」究竟出现在什么时候,没有明确的界定。当你看到 Ameca 的时候,你觉得它过了恐怖谷的节点了吗?它是否已经足够让你移情了?
模仿人类,然后超越人类
抛开视觉动物的评判本能,像 Ameca 这样的类人机器人有什么用?
Engineered Arts 自卖自夸,不顾马斯克的面子,称 Ameca 是「全球最先进的人形机器人」。
按照官方的定位,Ameca 首先是一个 AI 的开发平台。
Ameca 采用「模块化设计」,可在硬件和软件各方面进行升级,带有强烈的实验色彩,可以作为未来人机交互机器人的雏形。
最终,Ameca 不会停留在实验室里,而是活在现实世界里与人类和平共处。

事实也的确如此,如果说 2021 年是一个惊艳但空有其表的起点,如今由 AI 加持的 Ameca,就是一个阶段性的特训成果,让我们看到具身智能的曙光。不过,目前 Ameca 还不能行走。
至于 Ameca 目前的其他用处,就非常单纯了:给观众老爷们表演,在企业、主题公园、科学博物馆打工。如果你心动了,Ameca 可供购买或出租,但价格不便宜,2021 年底的购买价格超过 13.3 万美元。
当被问及 Ameca 是否是 AI 时,Engineered Arts 指出,虽然它包含一些可以被描述为「AI」的软件,但机器人和 AI 之间还是有区别的,纯 AI——在《她》《银翼杀手》和《2001 太空漫游》等电影中描绘的那种——尚不存在。

所以,当我们看到 Ameca 这个栩栩如生的机器人时,我们可以优哉游哉观赏,同时将恐惧和机器人三定律安全地藏在脑海里,再多等上一段时间。至少,它远不能取代人,它在现阶段也没有这样的目的。
但想到 AI 的进化速度,或许我们就笑不出来了。如果说 2023 年是 AI 元年,2024 年或许是机器人+ AI 的元年。
一个有趣的现象是,越来越多的家用机器人到来,但它们不苛求像人,长得也很「实用主义」。
斯坦福大学的 ALOHA 机器人炒菜、洗碗、拖地、叠衣服甚至逗猫,Google DeepMind 的机器人拿水果、放好牙刷,初创公司 Figure 则让机器人在 10 个小时内就学会了用咖啡机煮咖啡。

但比起大语言模型的颠覆,这些机器人只能说是让人眼前一亮,投入使用还为时尚早。
因为它们大多数体型笨重,操作任务集中在桌面操作,需要人类演示训练,缺乏更多的机动性和灵活性,基本姿势的微小偏差,都可能会导致姿势的大幅漂移,「翻车」视频不少。
一个关于 AI 的段子,从去年说到了今年:「我们想让 AI 做的是,做饭、打扫房间、洗衣服、扔垃圾,然而它们实际在做的是,聊天、绘画、写作、作曲、打游戏。」
目前来看,家用机器人勉强学会人类家务的皮毛,在家务和艺术之间,肩不能提、手不能抗的 Ameca,当然也更适合艺术。
从 Amera 身上可以看到,我们依然热衷于将机器人打造成人的模样,然后教它骂人、学语言、睁眼看世界,作为翻版但有些方面更强的自己。不过,Amera 尚且不能跑不能跳不能做饭,人类或许也值得为自己骄傲一秒。





