






花费 100 亿美元打造,史上最强 AI 芯片到底强在哪?
这两天,我们再次回顾了黄仁勋在 GTC 2024 上的演讲,在对产品做更深一层的分析解读时,发现了一些当时熬夜忽略掉的亮点。
一是老黄的演讲风格,幽默、自然、很有交流感,也难怪能把一场科技产品发布会开成演唱会的模样。
二是结合着前几代产品,再次审视最新发布的 Blackwell 架构以及系列 GPU,只能说它的算力性能、成本造价和今后表现,远超乎我的想像。
就如英伟达的名字一样,NVIDIA 的前两个字母 N 和 V,代表着 Next Version「下一代」。

与往年的 GTC 一样,英伟达如期发布了下一代产品,性能更高、表现更好;但又和以前完全不同,因为 Blackwell 所代表的不仅是下一代产品,更是下一个时代。
重新认识,地表最强 GPU
自我介绍一般都从名字开始,那这颗最新最强的 AI 芯片,也从这里讲起吧。

Blackwell 的全名是 David Harold Blackwell,他是美国统计学家、拉奥-布莱克韦尔定理的提出者之一。更重要的是,他还是美国国家科学院的首位黑人院士,和加州大学伯克利分校的首位黑人终身教员。

GTC 2024 上发布的这颗「Blackwell」就来源于此,倒不是说 Blackwell 本人对英伟达有过什么突出的贡献,而是在英伟达的命名体系中,拿历史上一些著名科学家(或数学家)的名字来命名 GPU 微架构,已经成为了一种惯例。
自 2006 年起,英伟达陆续推出的 Tesla, Fermi, Kepler, Maxwel, Pascal, Volta, Turing, Ampere 架构,就对应着特斯拉、费米、开普勒、麦克斯韦、帕斯卡、伏打、图灵、安培这几位学术大佬。

一是有名,二是有料,至于是否和指定产品一一对应,实际上就没有那么强相关了。
这里需要强调一点,上面提到的这些以名字命名的对象,不是哪一颗单独的芯片,而是指整个 GPU 的架构(黄仁勋将其称为平台)。

芯片架构(Chip Architecture)指芯片的基本设计和组织结构,不同的架构决定着芯片的性能、能效、处理能力和兼容性,也影响着应用程序的执行方式和效率。
简单讲,你现在拥有了一座体育场(制作芯片的原材料),你打算将它彻底改造,这块地具体是用来开演唱会还是办运动会(芯片用途),决定了场地布置、人员雇佣、装扮和宣发的方式(芯片架构)。
因此芯片架构和芯片设计相互关联,也共同决定了芯片性能。
例如经常听到的 x86 和 ARM,就是针对 CPU 而设计的两种主流架构,前者性能表现强悍,后者能耗控制优秀,各有长项。

基于多代 NVIDIA 技术构建,在 Blackwell 架构下的芯片 B200、B100 具备出众的性能、效率和规模,也一同开启了 AIGC 的新篇章。
但为什么会被称为「AI 核弹」?新 GPU 到底有多强?在与上一代产品的对比下,我们会有更直观的感受。
2022 年的 GTC 上,黄仁勋发布了全新架构 Hopper 以及全新芯片 H100:

1. 由台积电 4nm 工艺制程,当中集成了 800 亿个晶体管,比上一代 A100 足足多了 260 亿个。
2. H100 的 FP16、TF32 以及 FP64 性能都是 A100 的 3 倍,分别为 2000TFLOPS、1000TFLOPS 和 60TFLOPS,训练 3950 亿参数大模型仅需 1 天,用老黄的原话解释「20 张即可承载全球互联网流量」。
3. H100 的发售,让英伟达市值突破了2 万亿美元,成为仅次于微软和苹果的第三大科技公司。
据市场跟踪公司 Omdia 的统计分析,英伟达在去年第三季度大约卖出了 50 万台 H100 和 A100 GPU,这些显卡的总重,近千吨。
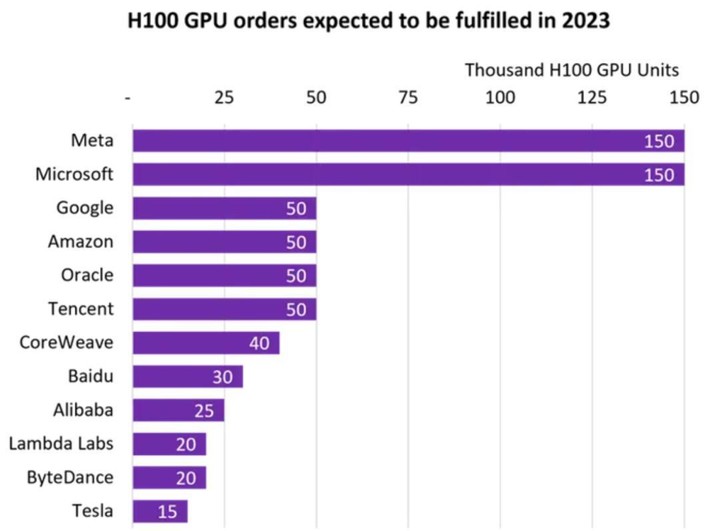
到目前为止,Hopper H100 仍是在售的最强 GPU,并遥遥领先。
而 Blackwell B200,再次刷新了「最强」的记录,性能的提升远超出了常规的产品迭代。
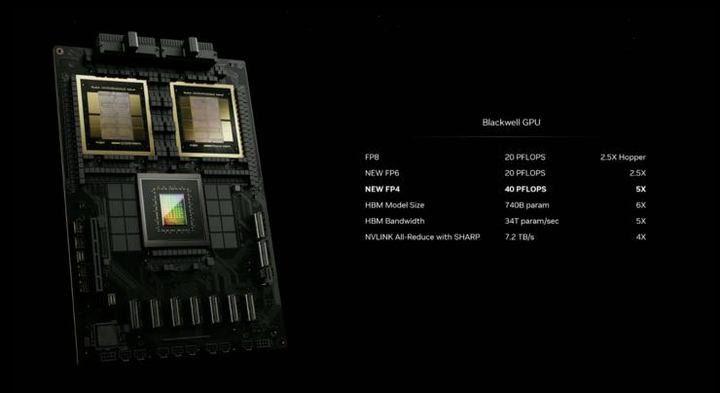
从制程工艺看,B200 GPU 采用第二代台积电的 4nm 工艺,采用双倍光刻极限尺寸的裸片,通过 10 TB/s 的片间互联技术连接成一块统一的 GPU ,共有 2080 亿个晶体管(单颗芯片为 1040 亿个),相较于制作Hopper H100 的 N4 技术,性能提升了 6%。,综合性能提升约 250%。

从性能看,第二代 Transformer 引擎使 Blackwell 可以通过新的 4 位浮点 AI 支持双倍的计算和模型大小推理能力,单芯片 AI 性能高达 20 PetaFLOPS(每秒可以执行 20×10^15 次浮点运算),比上一代 Hopper H100 提升了 4 倍,同时 AI 推理性能比上一代提升了 30 倍。
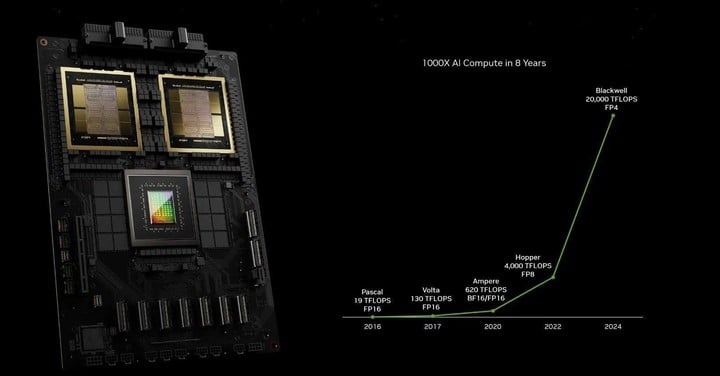
从能耗控制看,过去训练一个 1.8 万亿参数模型之前需要 8000 个 Hopper GPU 和 15 兆瓦的功率,如今 2000 个 Blackwell GPU 就可以做到这一点,而功耗仅为 4 兆瓦,直接降低了 96%。
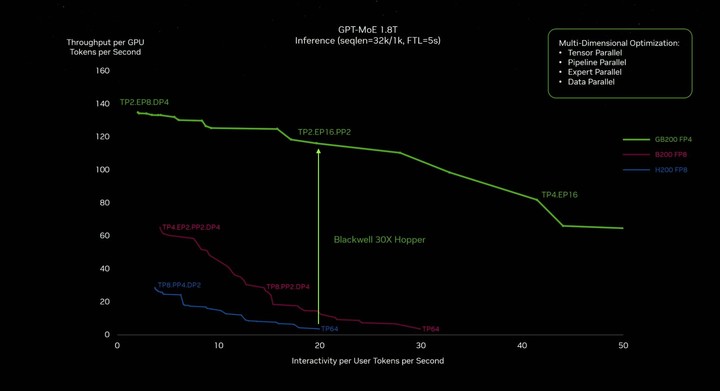
因此,黄仁勋的那句「Blackwell 将成为世界上最强大的芯片」并不是信口开河,而且已经成为事实。
不便宜的造价,不简单的用途
金融服务公司 Raymond James 分析师曾预估过 B200 的成本。
英伟达每制造一颗 H100 的成本约为 3320 美元,售价为 2.5-3 万美元之间,根据两者的性能差异推算 B200 成本将比 H100 高出 50%~60%,大概是 6000 美元。
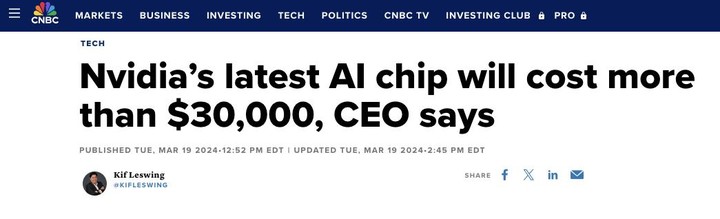
黄仁勋在发布会后接受 CNBC 专访时透露,Blackwell GPU 的售价约为 3 万~ 4 万美元,整个新架构的研发大约花了 100 亿美元。
我们必须发明一些新技术才能使其(新架构)成为可能。
按照以往的节奏,英伟达大约每两年就会发布新一代 AI 芯片,最新的 Blackwell 相较于前几代产品在算力性能和能耗控制上有了显著的提升,更直观的是, 结合了两颗 GPU 的 Blackwell 比 Hooper 大了将近一倍。

高昂的成本不仅与芯片有关,还与设计数据中心和集成到其他公司的数据中心紧密相连,因为在黄仁勋看来,英伟达并不制造芯片,而是在建数据中心。
根据英伟达最新的财报显示,第四财季营收达到创纪录的 221 亿美元,同比增长 265%。四季度净利润 123 亿美元,同比暴增 765%。
这当中最大的营收来源数据中心部门,达到创纪录的 184 亿美元,较第三季度增长 27%,较上年同期增长 409%。
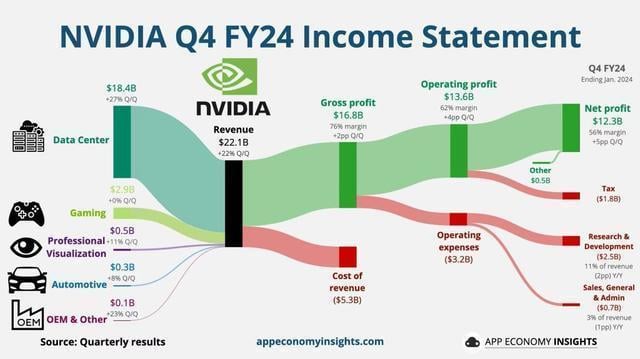
研发成本很高,但以此搏来的正向回报更高。
英伟达目前正在构建的数据中心,包含全栈系统和所有软件,是一套完整的体系,Blackwell 或者说 GPU,只是这当中的一环。
数据中心被分解成多个模块,用户能够根据自身需求自由选择相应的软硬件服务,英伟达会根据不同的要求对网络、存储、控制平台、安全性、管理进行调整,并有专门团队来提供技术支持。

如此的全局视野和定制化服务到底好不好,数据可以说明一切:截至 3 月 5 日,英伟达的市值继超越 Alphabet、亚马逊等巨头后,又超过沙特阿美,成为全球第三大公司,仅次于微软和苹果两大科技巨头,总市值达到 2.4 万亿美元。

目前,全球数据中心大约有 2000 亿欧元(约合人民币 7873 亿)的市场,英伟达正是这当中的一部分,黄仁勋预测这个市场在未来极有可能增长到 1-2 万亿美元。
英伟达 CFO 克雷斯分析:
第四财季数据中心的收入主要是由生成式 AI 及其相关训练所推动的。我们估计,过去一年中约有 40% 的数据中心收入来源于 AI。
不到一个月前,黄仁勋也在财报中表示
加速计算和生成式 AI 已经达到引爆点,全球范围内,企业、产业和国家的需求正在激增。
的确,定制化不是英伟达的专属,但在 AI 时代的风口,能够提供「从头到脚」的服务的企业所剩无几,英伟达就是其中之一。
猪能起飞,首先得在风口
在这个虚拟现实、高性能计算和人工智能的交叉口,GPU 甚至在取代 CPU 成为 AI 计算机的大脑。

生成式 AI 之所以引起各个行业的热烈讨论,最核心的一点是它开始像「人」一样工作学习,从聊天、写文案、画图片、做视频,到分析病情、调研总结……所有令人惊叹的生成结果,都需要天文数字般的样本数据作为支撑。
比如,你能记住「爱范儿」这个名字,可能是因为每天的公众号推送让信息不断重复加强了记忆;也可能是以前从未见过「爱」和「范儿」的组合,新奇感让你印象深刻;又或者是橙色的 logo 在你脑海中留下了独特的视觉符号。

每一个简单的小细节巩固了你脑海中「爱范儿」的画像,但当全国的科技媒体信息杂糅在一起的时候,就需要更多的符号来加深印象,以免搞混。
AI 的深度学习,大概就是这个逻辑,而 GPU 就是处理海量信息的最佳选择。
自 OpenAI 引燃 AIGC 后,大部分有名有姓的公司都开始极速上架自家的大小模型,智能汽车、翻译软件、电子文档、手机助手,连扫地机器人,都拥有了 AI。

GPU 仿佛在一夜之间就成了全球争夺的对象,根据市场跟踪公司 Omdia 的统计,这当中不乏腾讯、阿里巴巴、百度、字节跳动、特斯拉,Meta 和微软甚至各自采购了15 万颗 H100 GPU(去年最强芯片)。
技术原理和时代背景,共同促进了 GPU 的爆火,也成就了属于英伟达的「显卡帝国」。根据富国银行的统计,英伟达目前在数据中心 AI 市场拥有 98% 的市场份额。
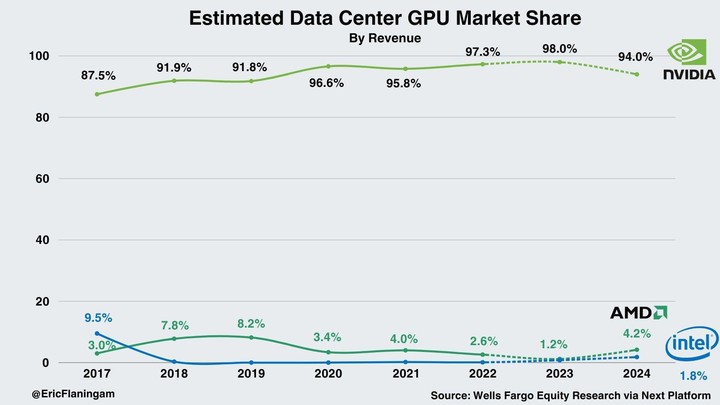
站在风口上,猪都可以飞起来。
但当一家公司在一个行业里的占有率接近 100% 时,背后一定有个和站在风口同样重要的原因。
1999 年,英伟达就率先提出了 GPU 的概念,2006 年就推出了 CUDA,这是英伟达发展史上一次重要的技术转折点,它降低了 GPU 的应用门槛,开发者可以用 C/C++ 等语言在 GPU 上边写程序,GPU 脱离了图像处理的单一用途,高性能计算走入了显卡的世界。

16 年 AlphaGo 的胜利,17 年比特币的暴涨以及挖矿热潮,在此期间押注自动驾驶市场,直到 23 年 ChatGPT 等 AI 大模型问世,让英伟达在多年前的播种,迎来了丰收时刻。

风口固然重要,但前瞻市场布局、多元化应用领域、大手笔的投入与创新,任何一环的失位,都不会造就当下接近满分的市场神话。
不过,于英伟达而言,如何在时代的十字路口保持领先地位,才是最重要的议题。
Blackwell,就是巩固成果的关键一步,在许多厂家还没收到已经下定的 H100 时,B200、B100 的流水线已经开启。

黄仁勋在演讲中,重申了自己在此前财报中提出的观点「通用计算已经到达瓶颈」。
因此现在需要更大的模型,也需要更大的 GPU,更需要将 GPU 堆叠在一起。
这不是为了降低成本,而是为了扩大规模。
这当中,有些谦虚,当然也有市场的巨大需求。
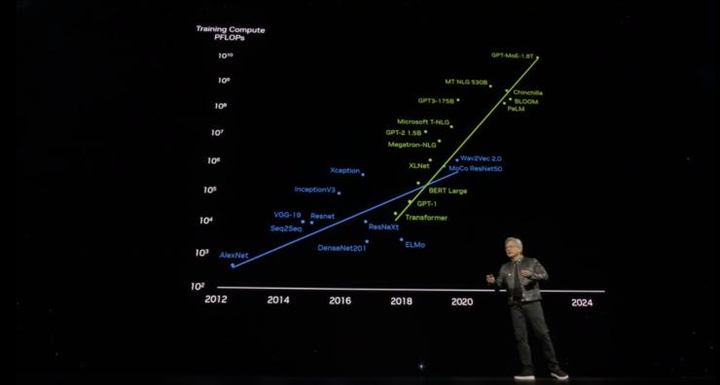
目前 OpenAI 最大的模型已经有 1.8T(万亿)参数,需要吞吐数十亿 token(字符串),即使是一块 PetaFLOP(每秒千万亿次)级的 GPU,训练这样大的模型也需要 1000 年才能完成。
Hopper 很棒,但我们需要更强大的 GPU。
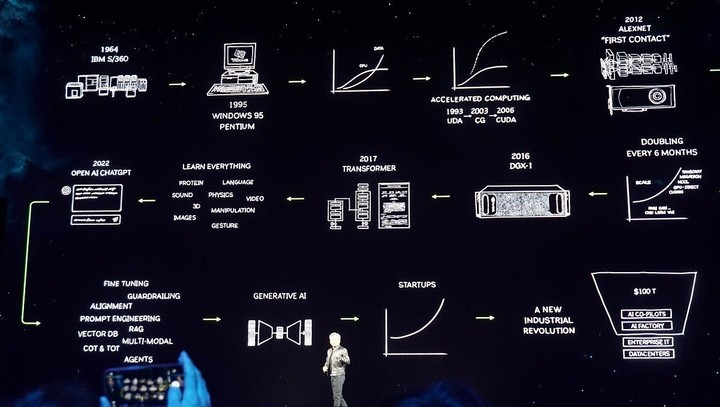
GTC 2024 带来的第一波讨论热潮在这几天慢慢淡去,可以预见的是,发布会上的 Blackwell GPU 系列、第五代 NVLink、RAS 引擎,在走向市场的时候会带来更多的震撼;难以预测的是「生成式 AI 已触及的引爆点」究竟还会给世界带来多少惊喜与改变?
在 AIGC 爆发的当下和 AGI 到来的前夕,英伟达引爆的这串 AI 鞭炮,目前还只是炸响了第一下。





