






中文得分世界第一,多项盲测并肩 GPT4o,这个国产大模型怎么就成了 AI 界的黑马?
零一万物,像是装上了 V12 发动机。
本月 13 号,李开复携零一万物发布了旗下第二款产品 Yi-Large 闭源模型。公开不到半个月,Yi-Large 就从初生牛犊不怕虎的新生代,成为了长江后浪排前浪的实力派。
上周,一个名为「im-also-a-good-gpt2-chatbot」的神秘模型突然现身大模型竞技场 Chatbot Arena,排名直接超过 GPT-4-Turbo、Gemini 1 .5 Pro、Claude 3 0pus、Llama-3-70b 等各家国际大厂的当家基座模型。
而这个神秘模型正是 GPT-4o 的测试版本,OpenAI CEO Sam Altman 也在 GPT-4o 发布后亲自转帖引用 LMSYS arena 盲测擂台的测试结果。
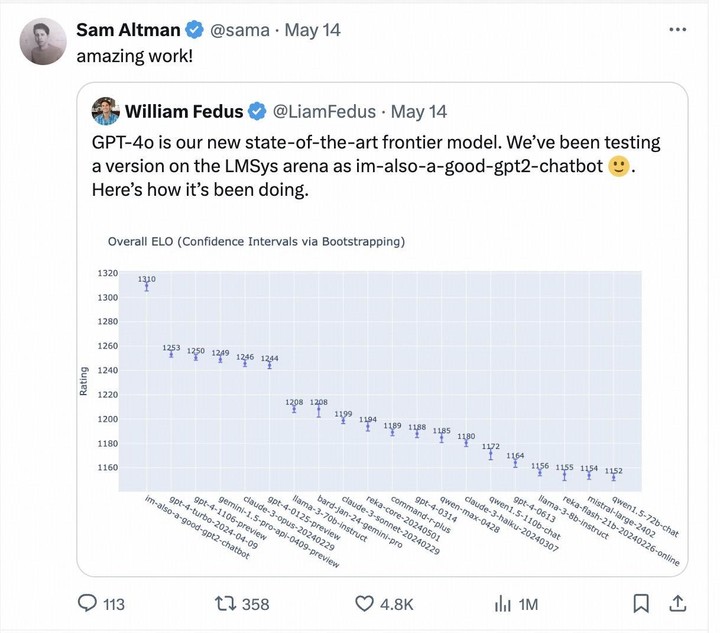
时隔一周,在最新更新的排名中,类「im-also-a-good-gpt2-chatbot」的黑马故事再次上演,这次排名飞速上涨的模型正是由中国大模型公司零一万物提交的「Yi-Large」 千亿参数闭源大模型。
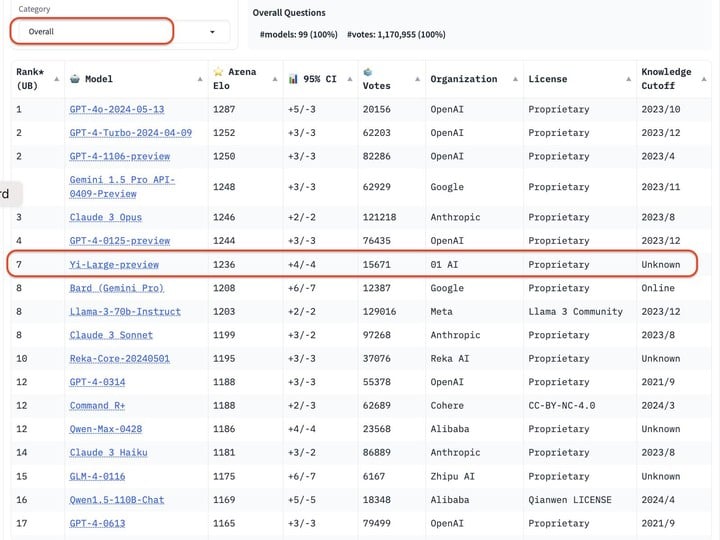
在 LMSYS 盲测竞技场最新排名中,零一万物的最新千亿参数模型 Yi-Large 总榜排名世界模型第 7,中国大模型中排名第 1,已经超过 Llama-3-70B、Claude 3 Sonnet;其中文分榜更是与 GPT4o 并列世界第一。
由开放研究组织 LMSYS Org (Large Model Systems Organization)发布的 Chatbot Arena 已经成为 OpenAI、Anthropic、Google、Meta 等国际大厂硬碰硬的擂台,并且还开放了群众投票功能。
零一万物也由此成为了总榜上唯一一个自家模型进入排名前十的中国大模型企业。
在总榜上,GPT 系列占了前 10 的 4 个,以机构排序,零一万物 01.AI 仅次于 OpenAI, Google, Anthropic 之后,正式进击国际顶级大模型企业阵营。
现在看来,那句「成为 World’s No.1」的口号,不是空喊,而是正在成为。
中文得分世界第一,「烧脑」盲测全球第二
美国时间 2024 年 5 月 20 日刚刷新的 LMSYS Chatboat Arena 盲测结果,来自至今积累超过 1170 万的全球用户真实投票数。
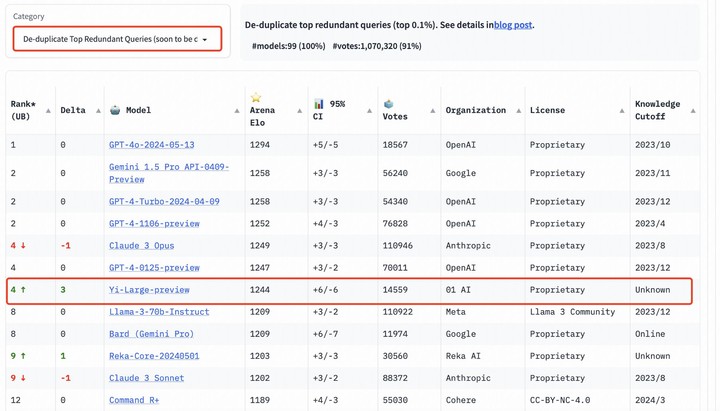
值得一提的是,为了提高 Chatbot Arena 查询的整体质量,LMSYS 还实施了重复数据删除机制,并出具了去除冗余查询后的榜单。
这个新机制旨在消除过度冗余的用户提示,如过度重复的「你好」,这类冗余提示可能会影响排行榜的准确性。
LMSYS 公开表示,去除冗余查询后的榜单将在后续成为默认榜单。
在去除冗余查询后的总榜中, Yi-Large 的 Elo 得分更进一步,与 Claude 3 Opus、GPT-4-0125-preview 并列第四。
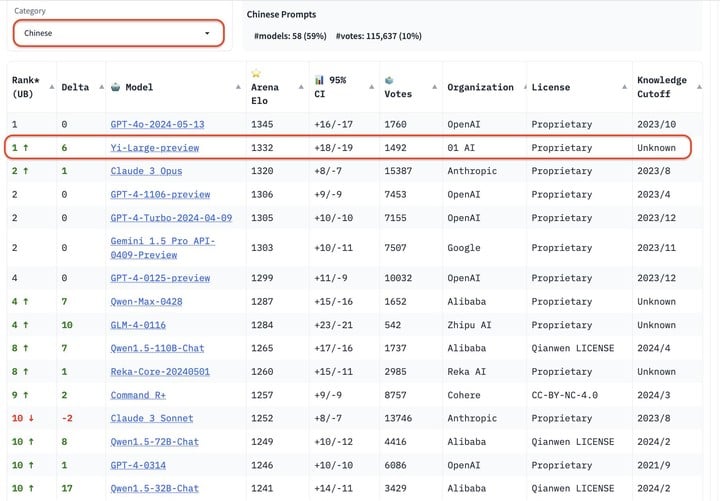
在总榜之外,LMSYS 的语言类别上新增了英语、中文、法文三种语言评测,开始注重全球大模型的多样性。Yi-Large 的中文语言分榜上拔得头筹,与 GPT4o 并列第一,Qwen-Max 和 GLM-4 在中文榜上也都表现不凡。
国内大模型厂商中,阿里的 Qwen-Max 和智谱的 GLM-4 都有表现不凡。
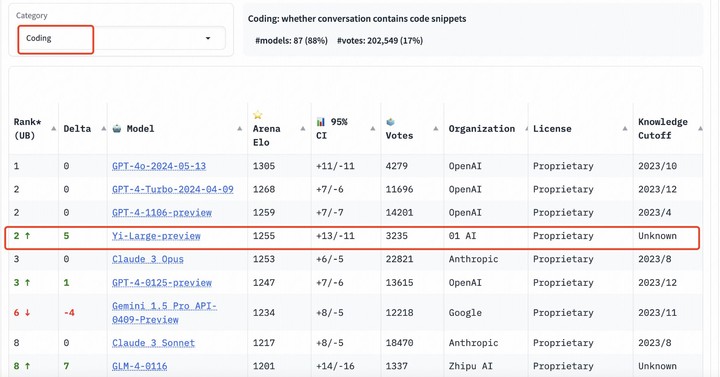
在分类别的排行榜中,Yi-Large 同样表现亮眼。编程能力、长提问及最新推出的 「艰难提示词」 的三个评测是LMSYS所给出的针对性榜单,以专业性与高难度著称,可称作大模型「最烧脑」的公开盲测。
编程能力、长提问及最新推出的 「艰难提示词」 的三个评测,专业性与高难度,也被称为 LMSYS 榜单中「最烧脑」的公开盲测。
在编程能力(Coding)排行榜上,Yi-Large 的 Elo 分数超过 Anthropic 的 Claude 3 Opus,仅低于 GPT-4o,与 GPT-4-Turbo、GPT-4 并列第二;
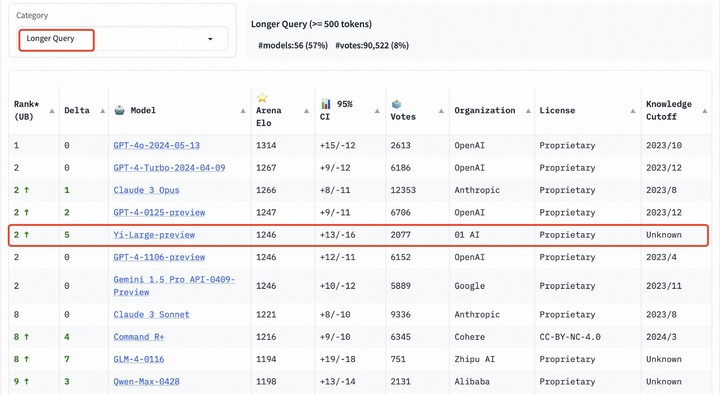
长提问(Longer Query)榜单上,Yi-Large 同样位列全球第二,与 GPT-4-Turbo、GPT-4、Claude 3 Opus 并列;
艰难提示词(Hard Prompts)榜单上,Yi-Large 与 GPT-4-Turbo、GPT-4、Claude 3 Opus 并列第二。

用科学方法,得客观结果
如何为大模型给出客观公正的评测一直是业内广泛关注的话题。
此前,业内出现过各式各样的「刷榜」方法,但始终无法体现大模型的真实能力,让想了解的人云里雾里,也让相关行业的投资人摸不着头脑。
而 LMSYS Org 发布的 Chatbot Arena 则开始打破这一乱象。
凭借其新颖的「竞技场」形式、测试团队的严谨性,成为目前全球业界公认的基准标杆,连 OpenAI 在 GPT-4o 正式发布前,都在 LMSYS 上匿名预发布和预测试。
OpenAI 创始团队成员 Andrej Karpathy 甚至公开表示:
Chatbot Arena is awesome(Chatbot Arena 是令人惊叹的).
在形式上,Chatbot Arena 借鉴了搜索引擎时代的横向对比评测思路:
- 首先将所有上传评测的「参赛」模型随机两两配对,以匿名模型的形式呈现在用户面前;
- 随后号召真实用户输入自己的提示词,在不知道模型型号名称的前提下,由真实用户对两个模型产品的作答给出评价;
- 接着在盲测平台 https://arena.lmsys.org/ 上,将大模型们两两相比,用户自主输入对大模型的提问;
- 模型 A、模型 B 两侧分别生成两 PK 模型的真实结果,用户在结果下方做出投票四选一:A 模型较佳/B 模型较佳/两者平手/两者都不好;
- 提交后,可进行下一轮 PK。
通过众筹真实用户来进行线上实时盲测和匿名投票,Chatbot Arena 一方面减少偏见的影响,另一方面也最大概率避免基于测试集进行刷榜的可能性,以此增加最终成绩的客观性。
在经过清洗和匿名化处理后,Chatbot Arena 还会公开所有用户投票数据。
在收集真实用户投票数据之后,LMSYS Chatbot Arena 还会使用 Elo 评分系统来量化模型的表现,进一步优化评分机制,力求公平反应参与者的实力。
在 Elo 评分系统中,每个参与者都会获得基准评分,每场比赛结束后,参与者的评分会基于比赛结果进行调整。
系统会根据参与者评分来计算其赢得比赛的概率,一旦低分选手击败高分选手,那么低分选手就会获得较多的分数,反之则较少。
通过引入 Elo 评分系统,LMSYS Chatbot Arena 很大程度上保证了排名的客观公正。
以小搏大
此次 Chatbot Arena 共有 44 款模型参赛,既包含了顶尖开源模型 Llama3-70B,也包含了各家大厂的闭源模型。

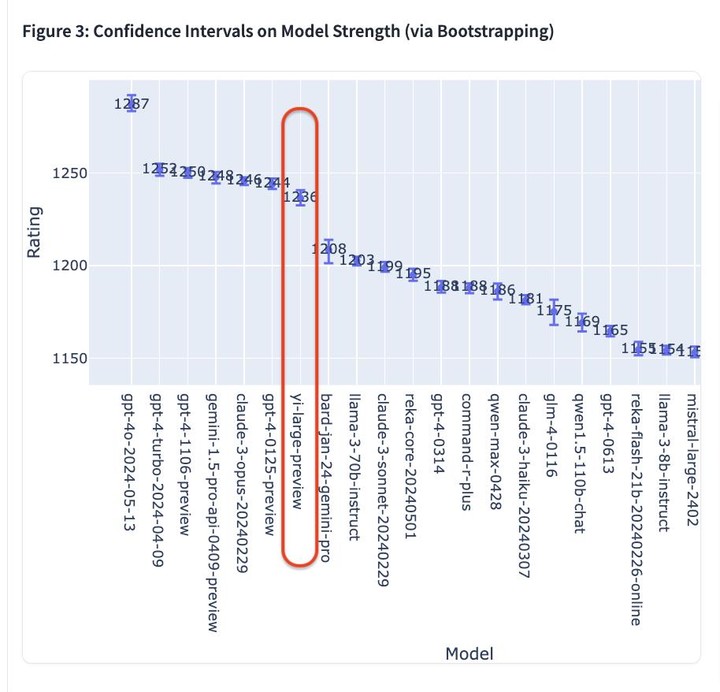
- 以最新公布的 Elo 评分来看,GPT-4o 以 1287分 高居榜首;
- GPT-4-Turbo、Gemini 1 5 Pro、Claude 3 0pus、Yi-Large 等模型则以 1240 左右的评分位居第二梯队;
- 其后的 Bard (Gemini Pro)、Llama-3-70b-Instruct、Claude 3 sonnet 的成绩则断崖式下滑至 1200 分左右。
值得一提的是,排名前 6 的模型分别归属于海外巨头 OpenAI、Google、Anthropic,零一万物位列全球第四机构,且 GPT-4、Gemini 1.5 Pro 等模型均为万亿级别超大参数规模的旗舰模型,其他模型也都在大几千亿参数级别。
Yi-Large「以小搏大」,以仅仅千亿参数量级紧追其后。

AI 大模型的竞争发展仍然处于白热化阶段,人工智能的「百模大战」仍会持续上演,在这个以「周」甚至以「天」为迭代单位的领域,有一个相对公平客观的评价体系,就显得尤为重要。
持续更新评分体系的评测平台,不仅可以让行业投资人看到技术发展的真实状况,也能让用户对先进模型有选择的权利,更是可以促进整个大模型行业的健康发展。
无论是出于自身模型能力迭代的考虑,还是立足于长期口碑的视角,大模型厂商应当积极参与到像 Chatbot Arena 这样的权威评测平台中,通过实际的用户反馈和专业的评测机制来证明其产品的竞争力。
相反,如果只在乎刷榜的结果,而忽视模型真实的应用效果,那么模型能力与市场需求之间的鸿沟会越发明显,最终将难以在激烈的 AI 市场竞争中立足。
在 AI 时代的浪口,各大模型厂商想要做到优秀甚至顶端,至少需要两种特质:
- 吾日三省吾身:在进步中获得经验,在竞争中得到答案;
- 真金不怕火炼:比起在「野榜」拿第一的花架子,不如向内审视,提升自己的真本事。
值得期待的是,现在有一批优秀的国产大模型厂商,正在脚踏实地,创新研发,甚至能够在国际舞台上,和行业巨头一较高下。
LMSYS Chatbot Arena 盲测竞技场公开投票地址:https://arena.lmsys.org/
LMSYS Chatbot Leaderboard 评测排行(滚动更新):https://chat.lmsys.org/?leaderboard





