






中国大模型价格战:大厂杀疯了,李开复王小川不跟风,最先被卷死的是谁
万万没想到,今年「618」竟然从 AI 大模型开始。
短短几天内,腾讯、阿里、百度、科大讯飞等国产大模型纷纷降价,让我们提前感受到了朴实的「购物节」氛围。
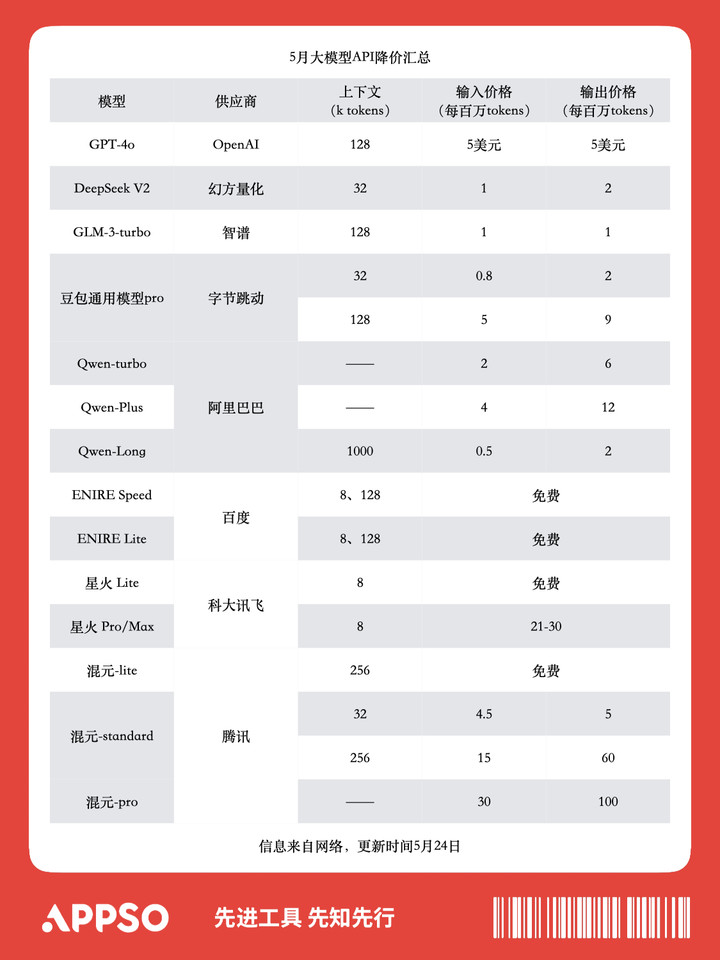
▲ 目前国产大模型降价情况汇总
不过在好戏开场之前,我们先弄清这些厂商所说的大模型价格到底指的是什么。
通常情况下,一家 AI 大模型公司在训练出自己的闭源大模型后,会将其 API(Application programming interface,应用程序编程接口)出售给开发者并收取费用。

▲ PI 就像是饭店中的服务生,图来自 hububble.com
开发者在大模型 API 的基础上,通过投喂数据、微调等方式进行优化,这就是很多大模型厂商的变现模式。
不难看出,大模型价格的变动或许不会直接影响到消费者,但会直接影响到开发者制作应用的成本。
虽然目前也有一些 AI 大模型公司采用会员制、计时制等模式,但普遍还是按使用量计费,类似于手机流量套餐,只不过计费单位从流量的 GB 变成了 token。
但 token 与汉字、字母的对应关系目前还没有统一标准,各家也有自己的定义。根据此前消息,腾讯 1 token≈1.8 个汉字,通义千问 1 token=1 个汉字,也有的是 1 token≈0.5 个汉字。
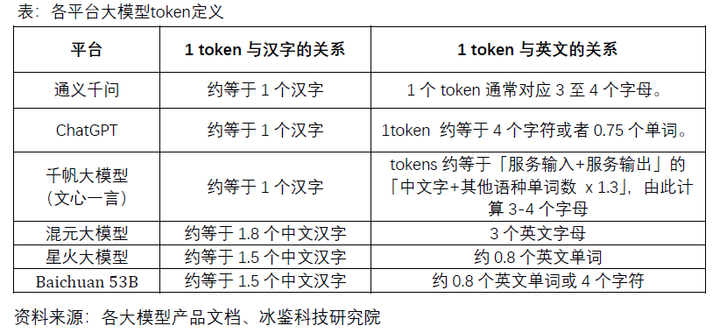
▲ 图片来自冰鉴科技研究院
因此,各家计费标准有所不同,但大致遵循大模型规模越大、定价越贵的规则,毕竟有训练成本在这里。
目前阶段,卖 API 调用量这一商业模式各大厂商仍在探索,很多厂商尝试通过各种方式提高大模型的 API 调用量,但增长却并不明显。
在这种情况下,大模型 API 降价可能会吸引一些开发者从「免费试用」开始尝试 AI 应用,对抢占市场、激活市场有一定的积极意义,这是这场「大战」的前提和背景。
预备,降!
5 月 6 日,幻方量化率先打响这波降价「大战」第一枪,旗下大模型 DeepSeek-V2的价格降到了每百万输入 tokens 仅需 1元的价格,还打出了「登录就送 500W tokens」的口号。

5 月 11 日智谱大模型也「跟上节奏」,推出新的优惠措施,新注册用户可以获得额度从 500 万 tokens 提升至2500万 tokens。
入门级产品 GLM-3-turbo 价格从5元每百万 tokens 将至 1 元,降幅达到了80%。
在公布价格的时候还「贴心」地把自己 GLM-3-turbo 与阿里、百度、ChatGPT做了对比,火药味十足。
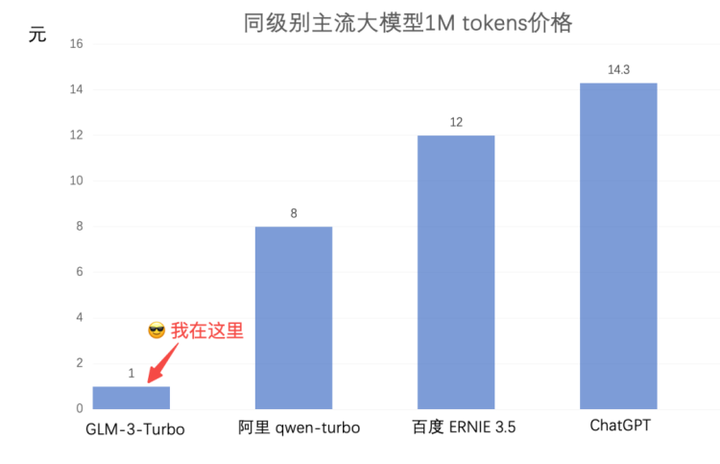
随后云厂商的入局把这波降价「大战」推向了高潮。
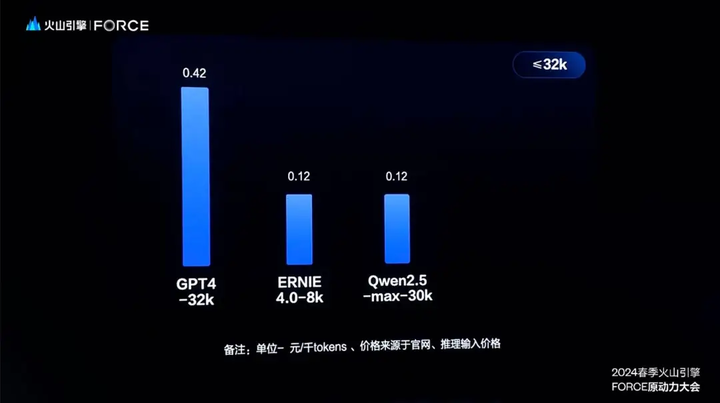
5 月 15日,字节豆包宣布:「把大模型的价格打下来了!」火山引擎总裁谭待宣布豆包主力模型在企业市场的定价为 0.0008 / 千 tokens,对比百度阿里及市面上同等规格模型的定价一般为 0.12 / 千 tokens,做到了「从分到厘」的价格内卷。
他还举了一个例子:「一元钱就能买到豆包主力模型的 125 万 tokens」,大约 200 万个汉字,相当于生成三本《三国演义》。
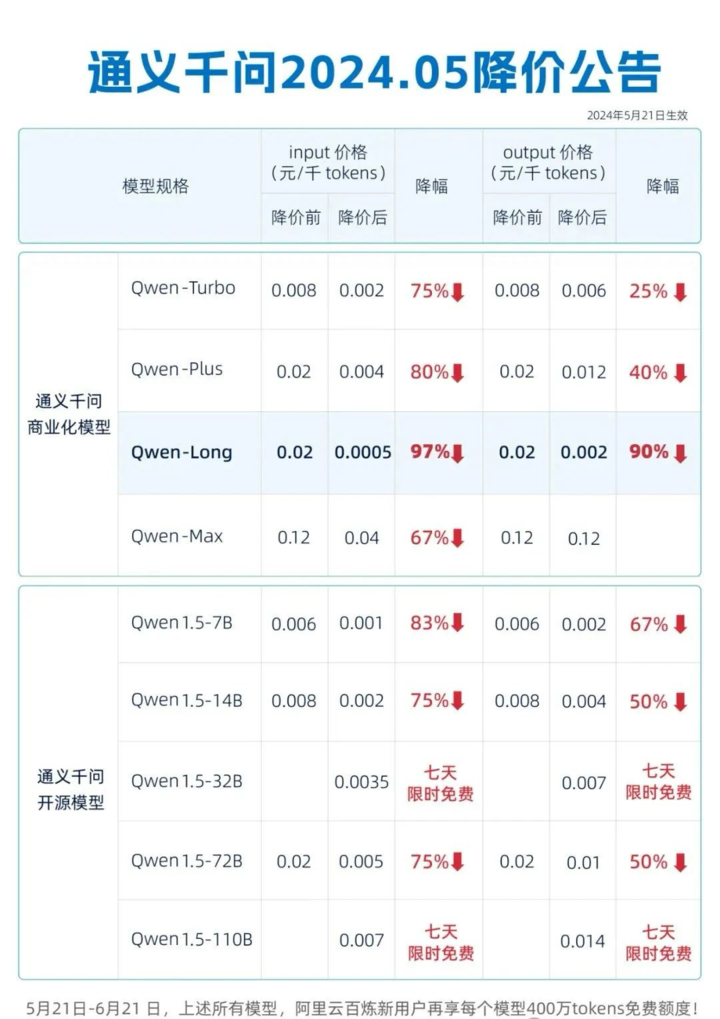
5 月 21日,面对字节跳动的价格战,阿里云相关负责人颇有反击意味地表示:
「友商大模型公司提出各种降价主题,降价目的是普惠市场,在中国什么样的公司真正有能力、有资本降价,要看模型基模能力是否领先、有没有推理资源、当下模型是不是已有很多用户在使用、大模型是不是最核心业务。」
与此同时,阿里云还打出了「击穿全球低价」的口号,旗下 9 款大模型集体降价,「GPT-4 级」助理模型 Qwen-Long 价格降到每百万 tokens 输入 0.5 元,输出 2 元。
也就是 1 块钱可以买到 200 万 tokens,相当于 5 本《新华字典》的文字量,但价格却仅为 GPT-4 的约 1/400。
仅仅几个小时后,另一个总是被对标的百度也展开行动,文心大模型两款主力大模型 ERNIE Speed 和 ERNIE Lite 直接全面免费。
这两款虽然不是其大模型中的旗舰款,却是目前百度文心大模型系列中服务用户最多的模型。

5 月 22 日,科大讯飞也宣布加入「降价火拼」,讯飞星火 Lite API 永久免费开放,讯飞星火 Pro/Max 低至 0.21 元 / 万 tokens,并表示「使用讯飞星火 3.5 max 仅需 2.1 元即可生成一部余华《活着》的内容量」。

同一天,腾讯云宣布加入大模型降价阵营,其混元-lite模型 API 价格从 0.008 元/千 tokens 全面免费,新上线的混元-standard、最高配置的万亿参数模型混元-pro API 均出现价格下调,并立即生效。

至此,几乎所有大模型大厂均已入局,似乎一夜之间,大模型就集体开启了疯狂的降价内卷。
「价格战」背后的技术革新
不仅是国产厂商,以 OpenAI 为代表的国外大模型也在不断下调大模型价格,虽然不像国产厂商这样集中,但行动的时间却比国产厂商更早。
2023 年 3 月推出的 GPT-3.5 turbo 将每千 tokens 的成本降到 0.002美元,相比之前的 GPT-3.5 turbo 降低了90%。
11 月发布的 GPT-4 Turbo 输入 tokens 价格仅为 GPT-4 的 1/3,输出 tokens 价格是 GPT-4 的 1/2。
近期发布的 GPT-4o 相比此前的 GPT-4 turbo,速度快了 2 倍,但价格却便宜了一半,从 2023 年至今已经连续四次降价。
不难看出,对于 OpenAI 而言,降价已经成为其不断升级与扩展市场的核心策略。其他大模型诸如 Gemini 等也都不忘在性能之后加上价格的变化,大降价已经成为大势所趋。

事实上,无论国产大模型还是国外大模型,降价的根本原因还是在于推理成本的快速降低。
不久前 DeepSeek-V2 就在一篇论文中为我们介绍了其利用 MLA(Multi-head Latent Attention,多头潜在注意力)结合 MoE(Mixture-of-Experts 专家混合模型),实现模型性能跨级别提升,同时减少计算量、推理现存及成本的案例。感兴趣的朋友可以点击查看原文:
https://github.com/deepseek-ai/DeepSeek-V2/blob/main/deepseek-v2-tech-report.pdf
随着算力的提升和算法的不断进步,这一趋势还将继续。创新工场董事长兼 CEO 李开复在近期的一次访谈中谈到近期出现的降价狂潮,也认为「整个行业每年降低 10 倍推理成本是可以期待的,而且必然也应该发生」。
不过,他也表示,目前出现的是一种不可持续的「ofo 式」双输打法,表示「如果技术不行,就纯粹靠贴钱、赔钱去做生意,我们绝对不会跟这样一个定价来做对标」。
这源于他对其大模型的自信,「就像特斯拉,不会因为别的牌子车比他卖得便宜,他也要来降价。」
不过,我们也都知道特斯拉其实也并非不降价,甚至有的时候会成为降价先锋,不知道他的言论会不会在未来成为「回旋镖」。

▲ 创新工场董事长兼 CEO 李开复,图片来自网络
浪潮近在眼前
除了李开复以外,百川智能创始人王小川也对此次价格战有不同的理解:
「我觉得就像原来的滴滴美团,这会刺激整个 to B 市场更快繁荣,大家会更愿意尝试使用。」
他认为价格战事实上也会提醒那些此前因为怕落后而盲目入局大模型的厂商,重新考虑自己的定位,并把一些「没想清楚」的公司清除出去。
「涨潮退潮最后才会有珍珠,一定有泡沫在里面,价格战会使得泡沫反而变得更加繁荣,并不是没泡沫就是好的状态。在之前的泡沫里面,很多公司觉得自己得去训模型,这是不健康的,市面上不需要那么多的模型提供方,不需要千模大战、万模大战。」

▲ 百川智能 CEO 王小川
猎豹移动董事长兼 CEO 傅盛则认为这是大模型出现同质化,性能难以甩开差距后的无奈之举:
「这次大降价基本宣告了大模型创业公司必须寻找新的商业模式。短期来看,大模型的性能遇到了瓶颈,谁也甩不开谁,谁也拿不出杀手锏,降低推理成本,降低售价成了现在每一家的高优先级任务。」
毫无疑问,各大厂商纷纷降价,对于很多大模型行业的创业公司而言,意味着更大的竞争压力。
事实上,当一个行业进入全面降价的阶段,也就意味着大规模淘汰赛的开始,最后往往只会剩下少数几个公司。
我们常常看到,在行业发展初期,由于「风口」的巨大诱惑,市场上往往会出现各种良莠不齐的企业相互竞争,但在一轮或几轮大规模降价后,行业重新洗牌,效率不高的公司被挤出市场。
目前来看,AI 领域的这一进程似乎正在加速,尤其对于部分大模型在市场并不具备优势的厂商而言更是如此。

不过另一方面而言,大模型降价对于用户而言却是一个好消息,因为这意味着他们可以用更低的成本访问和使用先进的 AI 技术,市场上也更容易催生出优秀的 AI 应用。
不过目前而言,整个行业商业化距离形成生态还有很远的距离,国内除了大模型公司以外, AI 应用的开发团队仍然有很大缺口。
根据百度公布的最新数据显示,文心大模型日处理文本 2500 亿 tokens,字节跳动日处理文本 1200 亿 tokens,但其中一大部分是大厂内部业务在调用 AI 应用和业务探索,可见目前其实整个行业还没形成生态。
彭博社此前也有分析师也指出:“中国在 AI 盈利方面将面临着漫长的道路,行业洗牌可能会推动该行业盈利,但这种情况似乎不太可能很快发生。”而成本的问题一直是限制行业发展的重要因素。
IDC 预测,2026 年中国 AI 大模型市场规模将会达到 211 亿美元,人工智能将进入大规模落地应用关键期。
相信随着大模型价格的下降,以及多模态发展、推理速度加快、成本降低,无论搜索、AI PC/手机或其他消费电子产品,都会成为 AI 应用发展的广阔空间。
这样的机会,或许会让很多人想起当初互联网方兴未艾之时,事实上两者也确有很多相似之处,这也是黄仁勋说当前正是「下一次工业革命」的重要原因。

边际成本下降,或许会成为 AI 平台革命的直接原因
A16Z 合伙人 Martin Casado 曾有这样一个观点,认为历史上曾经发生过两次由于边际成本下降,引发的平台转移和行业革命的案例,即芯片和互联网。
芯片的诞生,将计算的边际成本降到了趋近为零。在此之前,计算需要通过手工完成。人们需要在一个大房间里徒手作对数表。
然后 ENIAC 及其他机器被引入,计算速度迅速提高了四个数量级,随后引发的计算机革命带来了大批新的产业,让很多企业焕然一新,也催生出一批新的企业。

随后在互联网时代,分发的边际成本降到了 0,以前无论你发送什么(一个盒子或者一封信)都需要一定的成本,互联网出现后,每bit的价格急剧下降。
也是四个数量级的改进,促成后来相关产业迅猛发展,引领了互联网革命。这一时期出现了亚马逊、谷歌和 Meta 等公司都是其中代表。

与上述两种技术类似,AI 也同样是一场成本驱动型生产力革命。大模型则是将创造的边际成本降到了 0,比如创建图像和语言理解等等,他还举了这样一个例子。
假如想要创造一个关于他自己的皮克斯风格动画人物,大模型制作的成本约为 0.01 美分,且只需 1 秒钟,但雇用一位平面设计师 1 小时大约需要 100 美元,或许更贵。
人工智能不是稍微好一点,而是便宜且快了多个数量级。

▲ 对比人工智能与平面设计师在图像生成上的费用及所需时间
1865年,英国经济学家威廉·斯坦利·杰文斯观察到,提高煤炭使用效率的技术改进,反而会导致广泛行业煤炭消费量增加。
他认为,与很多人的直觉相反,效率提高导致了价格的下降,反而会刺激更多的需求。
换言之,当技术进步提高了使用资源的效率,但成本降低导致需求增加,令资源消耗的速度上升而非减少,这就是著名的「杰文斯悖论」。

▲ 威廉·斯坦利·杰文斯(1835.9.1—1882.8.13)
曾经的芯片、互联网就是这样一种资源,由于它的计算、信息效率提高、价格降低,刺激了更多的需求,产生了更多的价值和服务,催生出新的平台转移和行业革命,从而增加了生产力和人们的收入,最终改变了整个世界的样貌,也改变了我们每个人的生活。
这是芯片、互联网多年前的故事,也是如今关于 AI,正在发生的故事。





