






神秘「香蕉」AI 正式上线!Google P 图新王深夜炸场|附体验方式
还记得之前大家热议的神秘 AI 图片编辑模型「nano-banana」吗?
前几天,我们在 LMArena 大语言模型竞技场里面用它进行了多轮测试,结果表现都非常出色。
现在,Google 终于揭开了它的神秘面纱。
▲ Google AI Studio 负责人 Logan Kilpatrick 发推文宣布正式推出 Gemini 2.5 Flash Image 模型
Google 正式推出了其最先进的图像生成与编辑模型——Gemini 2.5 Flash Image。
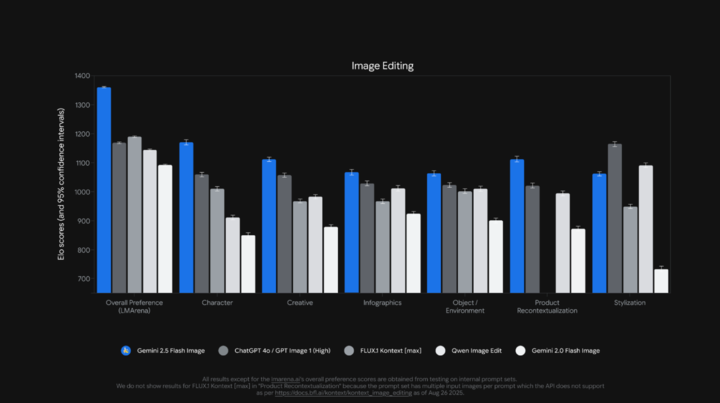
▲ 在多个榜单上都是第一名,尤其是 LMArena 榜单几乎是遥遥领先
在更新的技术博客里面,Google 提到此前的 Gemini 2.0 Flash 已经在图像生成方面,以其低延迟和高性价比受到了开发者的喜爱,但用户们也一直期待更高质量的图像和更强大的创作控制功能。
Gemini 2.5 Flash Image 就是带着一系列的重磅更新,来强势回应这些期待。
和我们之前的体验效果一样,Gemini 2.5 Flash Image 的主要特点包括下面几点
- 充分保持角色的一致性
- 基于提示的图片编辑
- 利用 Gemini 的现实世界知识
- 多幅图像融合
一张图讲一个故事:角色、场景随心换
以往的 AI 绘图工具,最大的痛点之一就是难以保持角色或物体的一致性。我们都曾经经历过,想让同一个角色出现在不同场景中,结果却常常画风突变,每一次生成都像换了个人。
Gemini 2.5 Flash Image 彻底解决了这个问题。

▲ 图片来源 X@geminiap
它可以轻松地将同一个角色置于不同的环境中,或者从多个角度展示同一款产品,同时完美地保持其核心主体不变。Google 提到这对于需要讲述连续故事、生成品牌系列资产或制作产品目录的场景来说,无疑是一项革命性的功能。
为了展示这项能力,Google AI Studio 中还提供了一个模板应用,让开发者可以快速上手,甚至在其基础上进行二次开发。
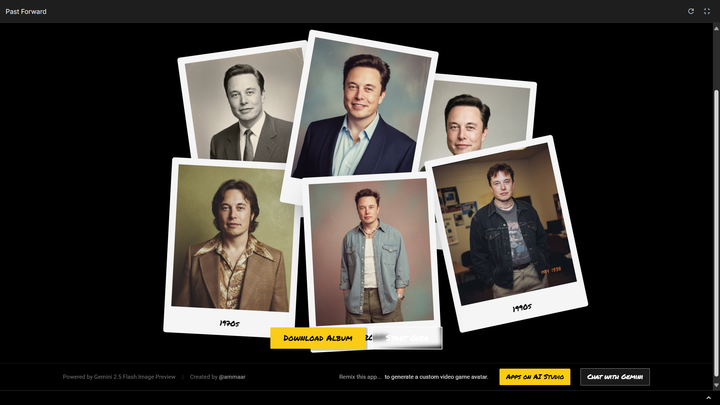
▲ 体验地址:https://aistudio.google.com/apps/bundled/past_forward
在这个体验项目里,我们不需要输入任何的提示词,只用上传一张人像照片,它就会调用这个最新的图像模型,为我们生成从 1976 年 到 1990 年等各个年份的照片。
马斯克看到自己这么帅心里一定在想,我的 Grok 也可以。
一句话修图,用自然语言精准编辑
除了这种保持好高度一致的角色生成,精准的编辑也是一大亮点。Gemini 2.5 Flash Image 允许我们通过简单的自然语言指令,对图片进行精准的局部修改 。
像是模糊图片背景、消除 T 恤上的污渍、从合照中移除某个人、改变人物的姿势、为黑白照片上色……
这一切,都不再需要复杂繁琐的专业软件操作,我们只需要像聊天一样,用一句话告诉 AI 想做什么即可。
这跟我们之前在 LMArena 中的体验是一样的,像是我们也转换过照片的风格,从黑白到彩色;以及对照片进行细微的调整等。

▲ 图片来源 X@geminiapp
Google 同样设计了一个简单的应用,来方便我们更好的体验这种基于提示词的图像编辑,但是完全媲美 PS 软件的效果。
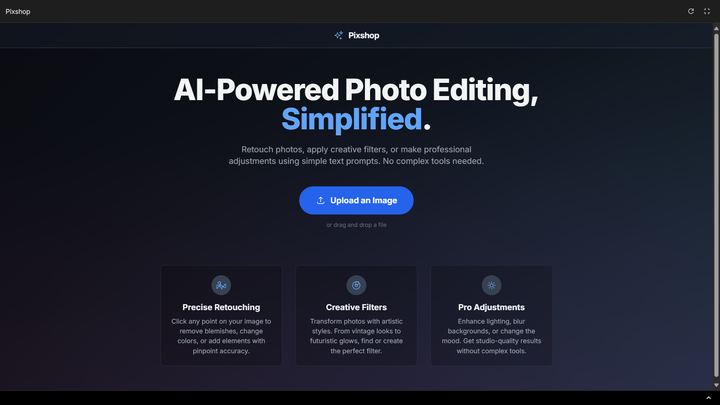
▲ 体验地址:https://aistudio.google.com/apps/bundled/pixshop
不止会画,更「懂」世界
过去的图像模型虽然能创造出精美的图片,但往往缺乏对现实世界的深层语义理解 。
Gemini 2.5 Flash Image 借助 Gemini 强大的世界知识库,让图像生成变得更加「智能」。
这意味着,模型不仅能看懂我们潦草手绘的图表,还能回答与现实世界相关的问题,并一步到位地执行复杂的编辑指令。
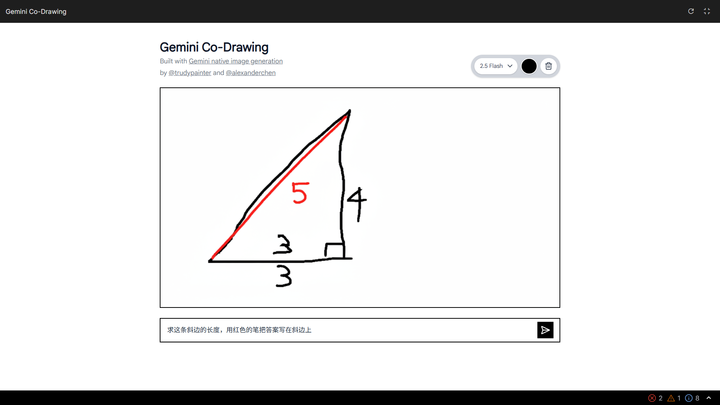
▲ 体验地址:https://aistudio.google.com/apps/bundled/codrawing
听起来很有多模态推理的感觉,Google 在 AI Studio 中展示了一个互动教育应用,将一块简单的画布变成了可以答疑解惑的智能导师,我由衷的感叹这个模型是真的厉害。
图像融合:轻松实现「无缝」拼贴
新模型还带来了一项酷炫的功能——多图像融合。我们可以将一张图片中的物体「放」进另一张图片的场景里,或者用一张图的风格去渲染另一间屋子,整个过程只需一条提示指令就能完成。
同样是 Google AI Studio 里面的模板体验应用,我们只需要把产品拖拽到新场景中,就可快速生成一张毫无违和感的、真实照片般的融合图像。
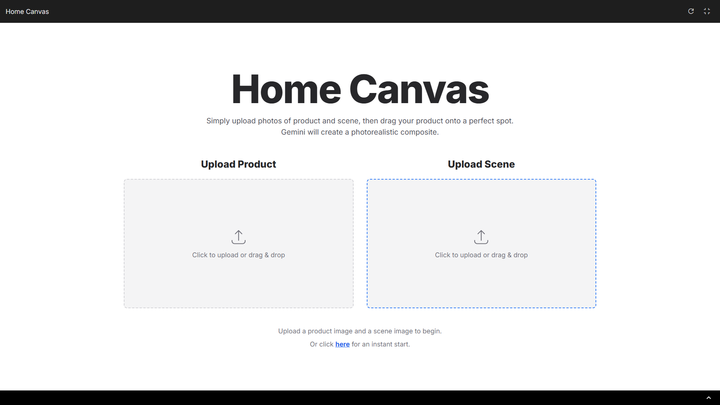
▲ 体验地址:https://aistudio.google.com/apps/bundled/home_canvas
在这个模板应用里面,我们甚至不需要输入任何提示词,可以直接拖动某个物体,到场景图片上的具体位置,然后它会自动生成融合的图片。
如何上手体验?
除了我们在前面提到的那些 Google AI Studio 里面的模板应用。
目前,Gemini 2.5 Flash Image 已经可以通过 Gemini APP、Gemini API、Google AI Studio 和 Vertex AI 进行访问。
关于调用 API,具体的定价是每百万输出 token 30 美元,官方介绍,生成一张图片大约消耗 1290 个输出 token,也就是说,每张图片的成本约为 0.039 美元,换算下来人民币不到 3 毛钱。
值得一提的是,所有通过 Gemini 2.5 Flash Image 创建或编辑的图片,都会包含 SynthID 隐形数字水印,以便识别其为 AI 生成或编辑的内容。
这跟前些天 Google 发布 Pixel 10 系列手机时,讲到 AI 图片编辑 Ask Photo 工具时,使用的 C2PA(内容来源和真实性联盟) 内容凭证是一样的。
最后,Google 还提到正在努力提升模型在长文本渲染、角色一致性稳定度和图像细节真实性等方面的表现。
总而言之,Gemini 2.5 Flash Image 的发布,让 AI 图像工具从一个单纯的绘画玩具,向一个真正实用的创意与生产力工具迈出了一大步。
它不仅解决了我们过去使用 AI 绘图时的诸多痛点,还带来了更多有趣、实用的新玩法。
之前 4o 生图能力出来,看到很多 App 开始主打用一张图每天生成一首诗,还有像是拿到了今年 Apple 设计大奖的 CapWords,拍一张生活里的照片,来实景学习一门新的语言……
我现在已经迫不及待想看到基于 Gemini 2.5 Flash Image 模型,又会有哪些新应用诞生了。





