






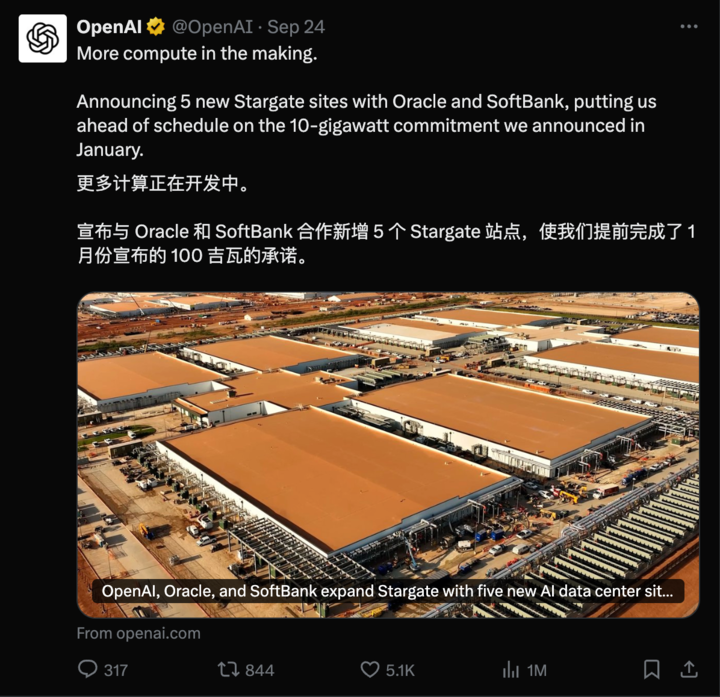
用 460 万美元追上 GPT-5?Kimi 团队首次回应一切,杨植麟也来了
上周 Kimi K2 Thinking 发布,开源模型打败 OpenAI 和 Anthropic,让它社交媒体卷起不小的声浪,网友们都在说它厉害,我们也实测了一波,在智能体、代码和写作能力上确实进步明显。
刚刚 Kimi 团队,甚至创始人杨植麟也来了,他们在 Reddit 上举办了一场信息量爆炸的 AMA(有问必答)活动。

▲ Kimi 团队三位联创,杨植麟、周昕宇、吴育昕参与回答
面对社区的犀利提问,Kimi 不仅透露了下一代模型 K3 的线索、核心技术 KDA 的细节,还毫不避讳地谈论了 460 万的成本,以及与 OpenAI 在训练成本、产品哲学上的巨大差异。
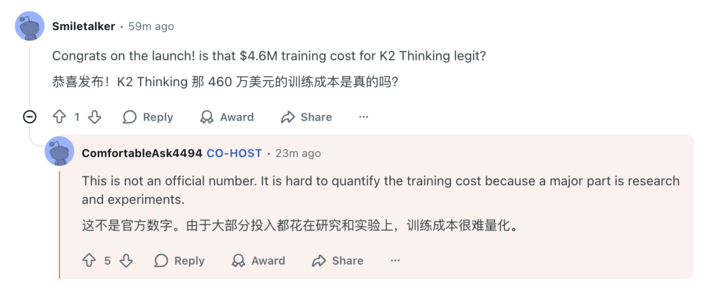
- 460 万美元这个数字不是官方的数字,具体的训练成本很难量化到多少钱
- K3 什么时候来,是看奥特曼的万亿美元数据中心什么时候建成
- K3 的技术将会继续沿用,当前效果显著的 KDA 注意力机制
- 视觉模型还需要我们去采集更多的数据,但目前已经在做了……

我们为你整理了这场 AMA 中最值得关注的几个核心焦点,来看看这家现在算是国产开源老大的 AI 实验室,是如何看待他们的模型,和未来 AI 的发展。
叫板 OpenAI,「我们有自己的节奏」
在这场 AMA 中,火药味最足的部分,大概就是 Kimi 团队对 OpenAI 的隔空回应。
最大的噱头之一:K3 什么时候来?Kimi 团队的回答非常巧妙:「在奥特曼的万亿美元数据中心建成之前。」
很明显这一方面是幽默,因为没有人知道 OpenAI 到底什么时候才能建成那个数据中心,另一方面似乎也在回应外界对于 Kimi 能用更少资源追赶 GPT-5 的赞叹。
当有网友贴脸开大,直接问 Kimi 怎么看 OpenAI 要花这么多钱在训练上时,Kimi 坦言:「我们也不知道,只有奥特曼自己才知道」,并强硬地补充道,「我们有自己的方式和节奏。」
这种自己的节奏,首先体现在产品哲学上。当被问到是否会像 OpenAI 一样发布 AI 浏览器时,团队直言 No:
我们不需要创建另一个 chromium 包装器(浏览器套壳),来构建更好的模型。
他们强调,目前的工作还是专注于模型训练,能力的体现会通过大模型助手来完成。
在训练成本和硬件上,Kimi 也展现了精打细算的一面。社区好奇 K2 的训练成本是否真的是传闻中的 460 万美元,Kimi 澄清了这个数字并不正确,但表示大部分的钱都是花在研究和实验上,很难具体量化。
至于硬件,Kimi 承认他们使用的是 H800 GPU 和 Infiniband,虽然「不如美国的顶级 GPU 好,而且数量上也不占优势」,但他们充分利用了每一张卡。
模型的个性与 AI 的垃圾味
一个好的模型,不仅要有智商,还要有个性。
很多用户喜欢 Kimi K2 Instruct 的风格,认为它「比较少的谄媚,同时又像散文一样,有洞察力且独特」。
Kimi 解释说,这是「预训练(提供知识)+ 后训练(增添风味)」共同作用的结果。不同的强化学习配方(即奖励模型的不同选择)会得到不同的风格,而他们也会有意的把模型设计为更不谄媚。
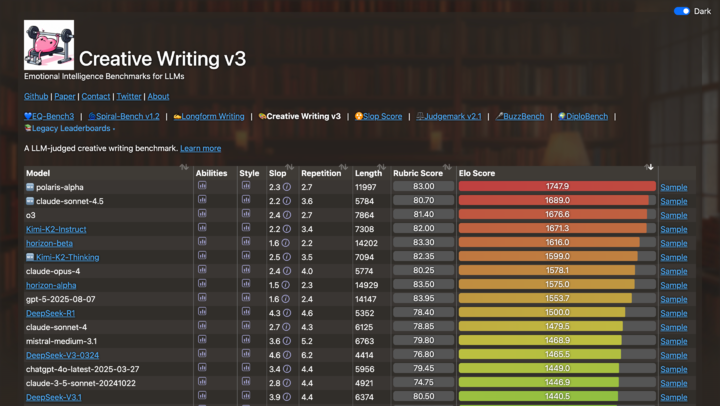
▲大语言模型情商评估排名,图片来源:https://eqbench.com/creative_writing.html
但与此同时,也有用户直言 Kimi K2 Thinking 的写作风格太「AI Slop 垃圾」,无论写什么话题,风格都太过于积极和正面,导致读起来 AI 味就是很重。他还举例子说,要 Kimi 写一些很暴力很对抗的内容,它还是把整体的风格往积极正面那边去靠近。
Kimi 团队的回答非常坦诚,他们承认这是大语言模型的常见问题,也提到现阶段的强化学习,就是会刻意地放大这种风格。
这种用户体感与测试数据的矛盾,也体现在对 Benchmark(跑分)的质疑上。有网友尖锐地提问,Kimi K2 Thinking 是不是专门针对 HLE 等跑分进行了训练,才会取得如此高分?毕竟这么高的分数,好像和他实际使用中的智能不太匹配。
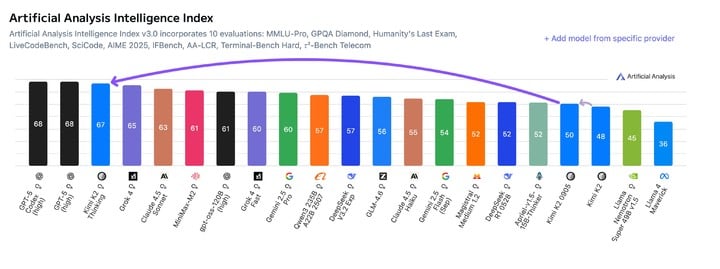
对此,Kimi 团队解释说,他们在改进自主推理方面取得了一些微小的进展,这刚好让 K2 Thinking 在 HLE 上得分很高。但他们也坦诚了努力的方向,要进一步提升通用能力,以便在更多实际应用场景中和跑分一样聪明。
网友还说,你看马斯克的 Grok 因为做了很多 NSFW (非工作安全) 的工作,生成图片和视频;Kimi 完全可以利用自己的写作优势,让它完成一些 NSFW 的写作,一定能为 Kimi 带来很多用户的。

Kimi 只能笑而不语,说这是一个很好的建议。未来是否会支持 NSFW 内容,可能还需要找到一些年龄验证的方法,也需要进一步做好模型的对齐工作。
很明显,现阶段 Kimi 是不可能支持 NSFW。
核心技术揭秘:KDA、长推理与多模态
作为一家被称为「开源先锋实验室」的公司,而 Reddit 本身就是也是一个非常庞大和活跃的技术社区,Kimi 也在这次的 AMA 中,分享了大量的技术细节。
10 月底,Kimi 在《Kimi Linear: An Expressive, Efficient Attention Architecture》的论文,详细介绍了一种新型混合线性注意力架构 Kimi Linear,其核心正是 Kimi Delta Attention (KDA)。

▲KDA 算法实现,论文链接:https://arxiv.org/pdf/2510.26692
通俗来说,注意力(Attention)就是 AI 在思考时,决定应该重点关注上下文哪些词语的机制。和常见的完全注意力和线性注意力不同,KDA (Kimi Delta Attention),是一种更智能、更高效的注意力机制。
在这次 AMA 活动中,Kimi 也多次提到,KDA 在长序列强化学习场景中展现了性能提升,并且 KDA 相关的想法很可能在 K3 中应用。
但 Kimi 也坦言,技术是有取舍的。目前混合注意力的主要目的是节省计算成本,并不是为了更好的推理,在长输入和长输出任务上,完全注意力的表现依然是更好的。
那么,Kimi K2 Thinking 是如何做到超长推理链的呢,最多 300 个工具的思考和调用,还有网友认为甚至比 GPT-5 Pro 还要好?
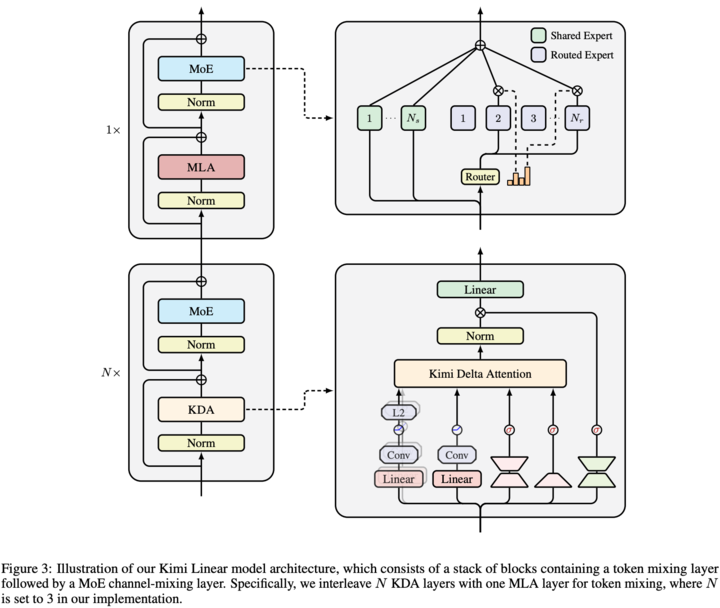
▲ Kimi Linear 模型结构
Kimi 认为这取决于训练方式,他们倾向于使用相对更多的思考 token 以获得最佳结果。此外,K2 Thinking 也原生支持 INT4,这也进一步加速了推理过程。
我们在之前的 Kimi K2 Thinking 文章中也分享了 INT4 的量化训练技术,这是一种高效的量化技术(INT4 QAT),Kimi 没有训练完再压缩,而是在训练过程中,就保持了低精度运算模型。
这能带来两个巨大的优势,一个是推理速度的提升,一个是长链条的推理,不会因为训练完再进行的压缩量化,而造成逻辑崩溃。
最后,关于外界期待的视觉语言能力,Kimi 明确表示:目前正在完成这项工作。
之所以先发布纯文本模型,是因为视觉语言模型的数据获取,还有训练,都需要非常多的时间,团队的资源有限,只能优先选择一个方向。
生态、成本与开放的未来
对于开发者和普通用户关心的问题,Kimi 团队也一一作答。
为什么之前能处理 1M 上下文的模型消失了?Kimi 的回答言简意赅:「成本太高了。」而对于 256K 上下文在处理大型代码库时依然不够用的问题,团队表示未来会计划增加上下文长度。
在 API 定价上,有开发者质疑为何按「调用次数」而非 token 收费。对使用 Claude Code 等其他智能体工具进行编程的用户来说,基于 API 请求次数的计费方式,是最不可控且最不透明的。
在发送提示之前,用户根本无法明确工具将发起多少次 API 调用,或者任务将持续多长时间。

▲Kimi 会员计划
Kimi 解释说,我们用 API 调用,是为了让用户更清楚的知道费用是怎么消耗的,同时符合他们团队的成本规划,但他们也松口表示会看看是否有更好的计算方法。
当有网友提到自己公司不允许使用其他聊天助手时,Kimi 借机表达了他们的核心理念:
我们拥抱开源,因为我们相信通用人工智能应该是一个带来团结而不是分裂的追求。
而对于那个终极问题——AGI 什么时候到来?Kimi 认为 AGI 很难定义,但人们已经开始感受到这种 AGI 的氛围,更强大的模型也即将到来。
和去年疯狂打广告营销的 Kimi 不同,在这场 AMA 力,杨植麟和团队成员的回答;确实能让人感受到在国产开源,逐渐占据全球大语言模型开源市场的背景下,Kimi 也更加有底气,更明确了自己的节奏。
而这个节奏很明显,就是在这场烧钱、甚至卷太空的 AI 竞赛中,继续走开源的路,才能推动技术往前走。





