






刚刚,年度最强 AI 登场!马斯克奥特曼点赞 Gemini 3,体验后我发现 ChatGPT 要慌了
就在刚刚,Gemini 3 Pro 预览版正式发布。
年底的 AI 圈向来不缺新闻,但今年格外喧嚣。如果不出意外,这将是 2025 年压轴登场、最令人期待的海外大模型,甚至可以说,Gemini 3 Pro 成了这个时间窗口唯一的主角。
过去两个月,Google 几乎复刻了 Sam Altman 的营销手法,从 Gemini 著名宣传委员 Logan Kilpatrick 到 CEO 皮查伊,内部人员不断在社交平台打哑谜,推波助澜,将外界对 Gemini 3 的期待值不断拔高。
有趣的是,OpenAI CEO Sam Altman 刚刚在 X 平台发文称:「恭喜谷歌成功推出 Gemini 3!!看起来是个很棒的模型。」
有着奥特曼的前车之鉴,谜语人玩法风险极大,一旦产品力不足,口碑会瞬间崩塌。但显然,谷歌对自己的产品充满自信。那么,Gemini 3 Pro 这次到底交出了什么答卷?
省流版如下:
- Gemini 3 Pro 预览版原生多模态支持(文字、图像、视频、音频)
- 在 LMArena 排行榜登顶,在推理、多模态、编程等主流测试中全面领先
- 推理能力创纪录(GPQA Diamond 91.9%、MathArena Apex 23.4%)
- 提供 Deep Think 增强推理模式(未来几周开放)
- 100 万 token 上下文窗口 + 64K 输出
- 推出全新 AI IDE:Google Antigravity,新模型已集成 Cursor、GitHub、JetBrains 等工具
无愧 Pro 之名,谷歌最强 AI 模型深夜发布
按照 Google 的说法,Gemini 3 Pro 是目前「最智能、最具适应性的模型」,专为解决现实世界中的复杂问题而设计——尤其是那些需要更高层次推理、创造力、战略规划以及逐步改进的任务。
它的典型应用场景包括:具备自主行为能力的应用、高级编程、超长上下文理解、跨模态处理(如文字、图像、音频的结合),以及算法开发等。
Gemini 3 Pro 预览版在 LMArena 排行榜上以 1501 分的成绩位列榜首, 在几乎所有主要 AI 基准测试中都远超上一代。更关键的是,它不仅能识别图像内容,还能理解其中的隐含信息和上下文关系。
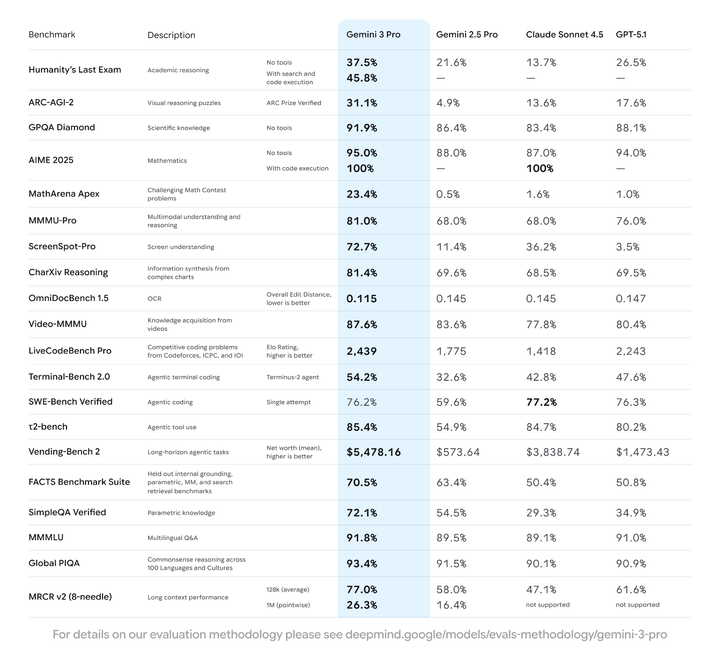
具体来看, 推理能力方面, 它在「人类最后的考试(Humanity’s Last Exam)」中拿到了 37.5% 的博士级推理成绩,GPQA Diamond 测试达到 91.9%,MathArena Apex 创下 23.4% 的业界新纪录。
多模态推理方面,MMMU-Pro 得分 81%,Video-MMMU 得分 87.6%, SimpleQA Verified 事实准确率达到 72.1%。
这也意味着 Gemini 3 Pro 能在科学、数学等各种复杂问题上可靠地提供优质解答, 而且它的回复直接提供真实见解, 告诉你需要知道的, 而不只是你想听到的。
除了常规模式,Gemini 3 还提供了一个名为 Deep Think 的增强推理选项。
这个增强型推理模式在「人类最后的考试」中得分 41.0%,GPQA Diamond 提升至 93.8%, 在 ARC-AGI-2 测试中更是创造了 45.1% 前所未有的得分分数。
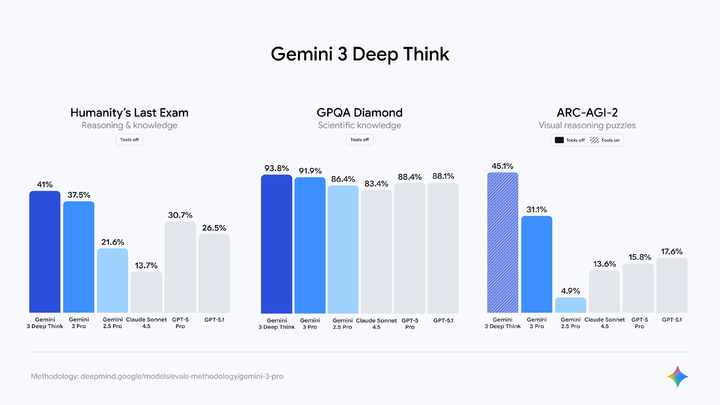
不过这个模式目前还在安全评估, 预计未来几周内向 Google AI Ultra 订阅用户开放。
测试数据之外,Gemini 3 在实际应用场景中的表现更值得关注。
比如你翻出家里那本手写的家族菜谱, 上面是奶奶用多种语言写的做法,Gemini 3 可以识别这些手写文字, 整理成可分享的菜谱书。

或者你想学习一个新领域, 它可以处理学术论文和长视频讲座, 生成交互式学习卡片。甚至, 它还能分析你打匹克球的比赛视频, 生成针对性训练计划。
这背后是因为 Gemini 从一开始就为多模态理解而设计,能够整合文字、图像、视频、音频和代码等多种信息类型, 加上高达 100 万 token 的上下文窗口和最大支持 64K 输出。
值得一提的是,Gemini 3 正式发布并首日集成进 Google 搜索。
它不仅显著提升搜索对复杂问题的理解与信息挖掘能力,还能根据查询即时生成动态视觉界面、互动工具与模拟系统,如三体物理模拟器或贷款计算器。
另外,根据谷歌发布的模型卡,Gemini 3 Pro 采用了基于 Transformer 的稀疏专家混合模型(MoE),原生支持文本、视觉和音频等多模态输入,这种架构的核心优势在于:模型会根据每个输入 token 的内容,动态选择激活部分参数,从而在计算资源消耗、服务成本与总容量之间实现平衡。
至于硬件层面,Gemini 3 Pro 使用 Google 自研的张量处理单元(TPU)进行训练。相比 CPU,TPU 在处理大语言模型所需的大规模计算时速度更快,且配备的大容量高带宽内存,让它能够处理超大模型和批量数据。
如果你是开发者,Gemini 3 带来的改变会更直接。
谷歌官方博客号称,Gemini 3 是目前最强的「vide coding」模型——你只需用自然语言描述想要什么, 它就能生成功能完整的互动应用。

数据很能说明问题:WebDev Arena 排行榜 1487 Elo,Terminal-Bench 2.0 得分 54.2%,SWE-bench Verified 得分 76.2%。
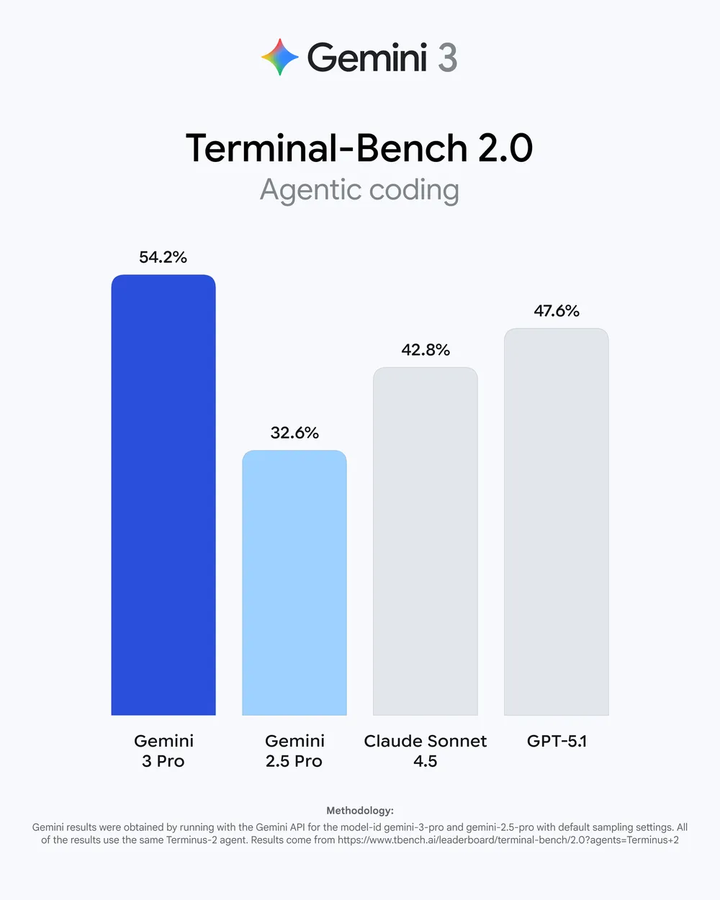
Google 这次还推出了全新 AI IDE:Google Antigravity。
内置的智能 Agent 可以自主规划和执行复杂的端到端软件任务, 并自动验证代码正确性。你想做一个航班追踪应用, 代理能够独立规划、编写代码, 并通过浏览器验证运行效果, 甚至可以同时在编辑器、终端和浏览器之间协同工作, 一气呵成。
在长期规划能力上,Gemini 3 在 Vending-Bench 2 榜单上位居第一。
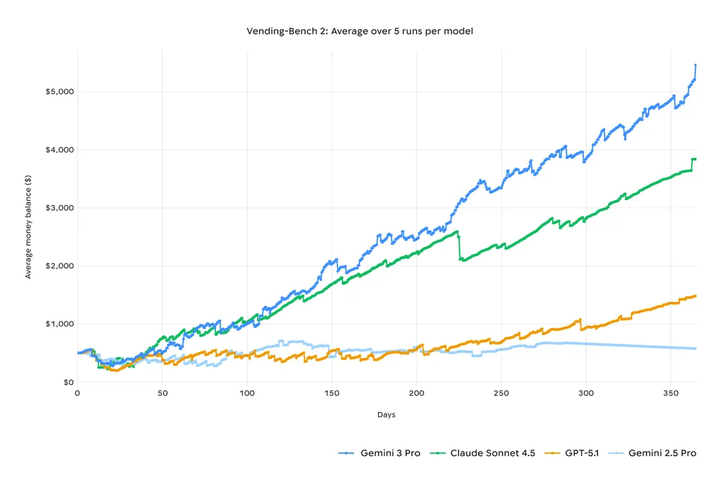
实际应用中, 最新发布的 Gemini Agent 实验性功能可以从头到尾执行多步骤复杂流程。你说「整理一下我的收件箱」, 它就会帮你优先安排待办事项, 并起草邮件回复供你确认。
或者「查资料帮我预订一辆中型 SUV, 预算每天不超过 80 美元, 用我邮件里的信息安排下周出行」,Gemini 会定位航班信息, 对比租车选项, 为你准备预订流程。
整个过程中你始终掌握主动权,Gemini 会在重要操作前请求确认。
此外,在 Google AI Studio 和 Vertex AI 中, 通过 Gemini API 使用 Gemini 3 Pro 预览版的价格为:输入每百万 token 需要 2 美元, 输出每百万 token 需要 12 美元。在 Google AI Studio 中也可以免费使用, 但有调用限制。

Gemini 3 已集成至 Cursor、GitHub、JetBrains、Replit 等开发工具生态系统中。
伴随产品发布,Google 同步开放了多个使用入口。
从今天起,Gemini 3 预览版正在陆续上线:所有用户可在 Gemini 应用中使用;Google AI Pro 和 Ultra 订阅用户可在搜索的 AI 模式中体验;开发者可通过 Gemini API、Google Antigravity 和 Gemini CLI 访问;企业用户通过 Vertex AI 和 Gemini Enterprise 获取服务。
ChatGPT 的对手来了,Gemini 3 实测表现「能打」到什么程度?
当然,科技公司总是宣传大于实际,那么我们也上手测试了几个问题。
第一个挑战是让它在单个 HTML 文件中还原一台完整的 Game Boy 掌机, 内置《俄罗斯方块》《宝可梦红/蓝》等经典游戏, 所有操控必须同时支持键盘和触屏交互。
坦白说, 我对这个需求的期望值并不高。
这种需要同时处理 UI 设计、游戏逻辑、音效系统的任务, 即便是专业前端工程师也得花上几天时间。但 Gemini 交出的答卷出乎意料:交互界面达到了六七分的效果, 按键按下时还有标志性音效, 作为一次性生成的代码, 已经相当能打。
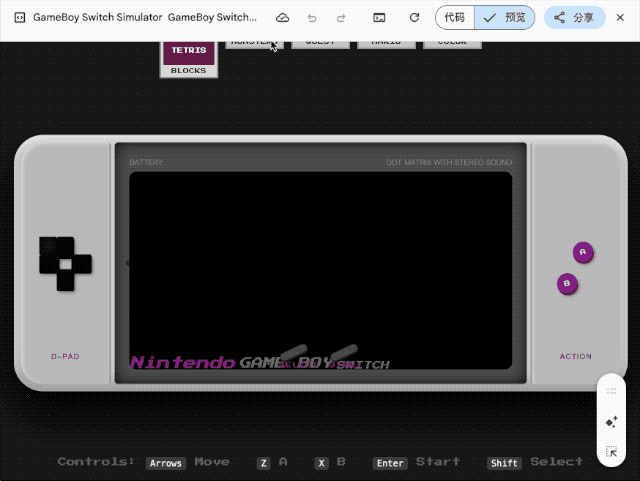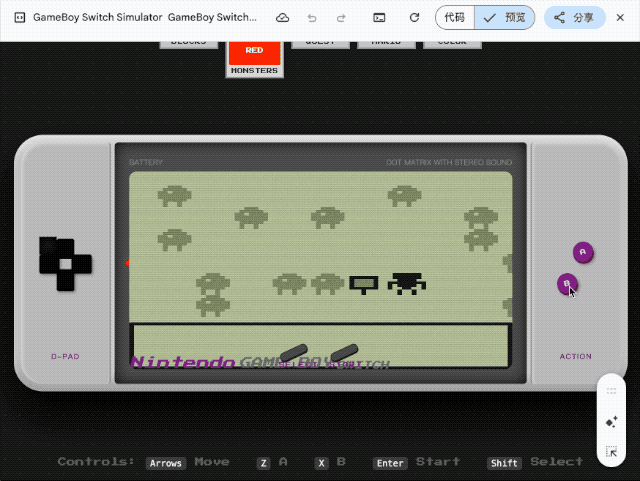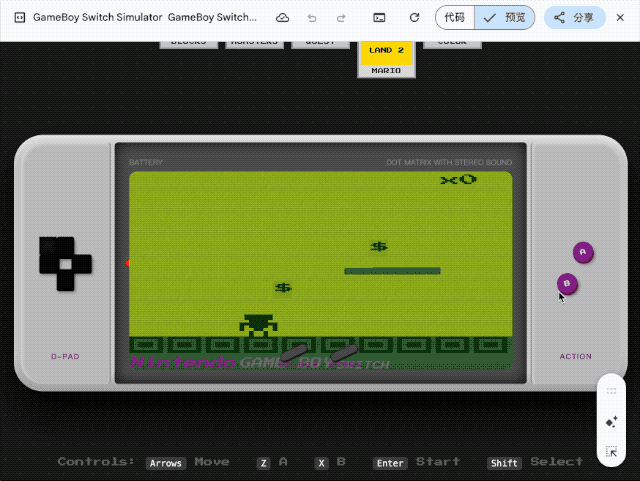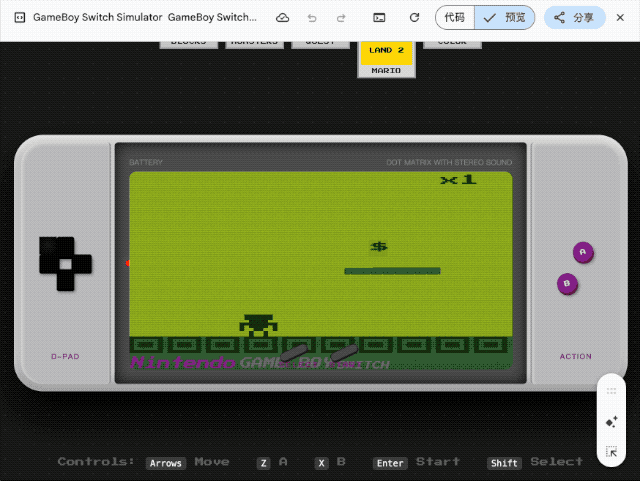
既然复古游戏机能跑起来, 我们继续加码。
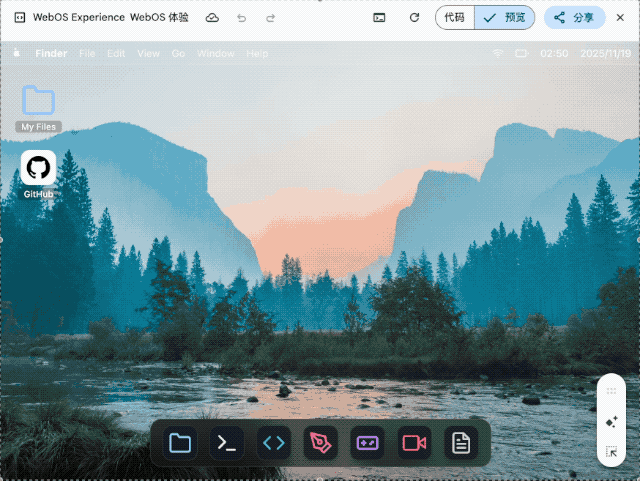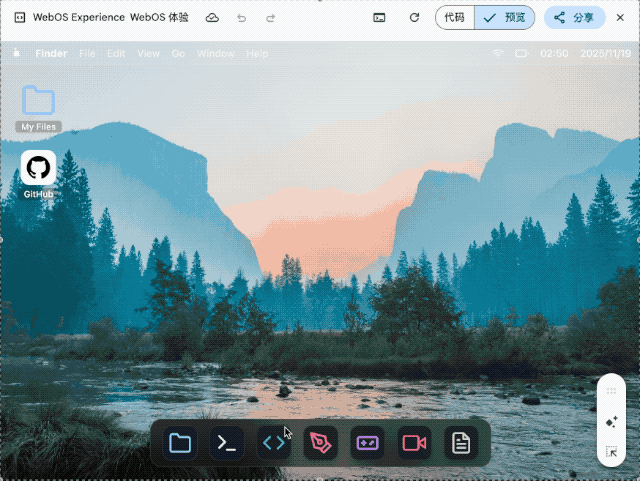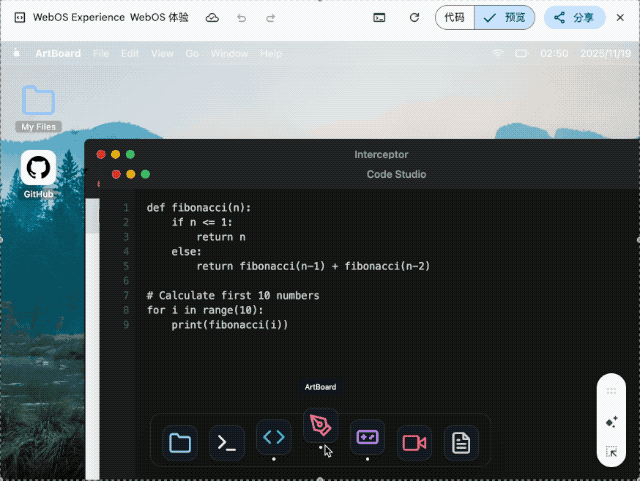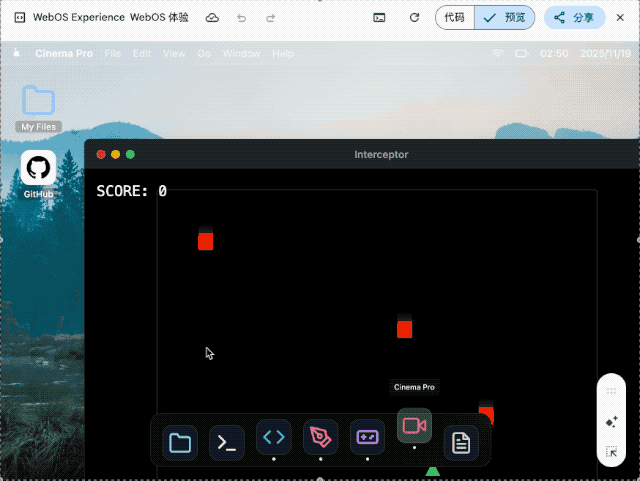
▲ Design and create a web os like macOS full functional features from text editor , terminal with python and code editor and a game that can be played to dile manager to paint to video editor and all important windows os pre bundled software Use whatever libraries to get this done but make sure I can paste it all into a single HTML file and open it in Chrome.make it interesting and highly detail , shows details that no one expected go full creative and full beauty in one code block
我要求它用单个 HTML 文件复刻一个完整的 macOS 系统, 包括文本编辑器、终端、代码编辑器、文件管理器、画板、视频编辑器等预装软件。生成的结果虽然审美一般, 但核心交互逻辑都实现了。

除了编程能力, 我们也测试了它的视觉生成和推理能力。
参考 X 用户 @lepadphone 的做法, 我让 Gemini 用前端代码实现一个电扇的可视化效果,建议使用 SVG 技术来绘制,包含以下元素:扇叶、保护网罩、底座、控制按钮等结构细节,并实现扇叶旋转、调速等动态效果。生成的 SVG 不仅结构完整, 扇叶的旋转动画也很自然。
紧接着我又让它画一只鹈鹕骑自行车——这种不常见的组合对 AI 的空间想象力是个考验, 结果它生成的图形比例协调, 鹈鹕的姿态和自行车的透视关系都处理得不错。

▲提示词:Create code for an SVG of a pelican riding a bicycle as nicely as you can
在推理能力上,我用到了那道经典的猴子分桃问题,Gemini 答案不光对,也进行了二次验算。
「有 5 只猴子在海边发现 一堆桃子, 决定第二天来平分. 第二天清晨, 第一只猴子最早来到, 它左分右分分不开, 就朝海里扔了一只, 恰好可以分成 5 份, 它拿上自己的一份走了. 第 2,3,4,5 只猴子也遇到同样的问题, 采用了同样的方法, 都是扔掉一只后, 恰好可以分成 5 份. 问这堆桃子至少有多少只?」

更有意思的是, 我们还测试了它对「废话文学」的理解能力。
面对「懂者得懂其懂, 懵者终懵其懵, 天机不言即为懂, 道破天机岂是懂」这种故弄玄虚的文字游戏,Gemini 的处理方式很聪明:先定性为「废话文学」给你吃颗定心丸, 再挖掘背后的道家「有无」、佛家「色空」等文化梗, 最后给出人话翻译。这种回答比简单说「这是废话」要高明得多。

写作测试自然也没落下。
我们让 Gemini 用第一人称写「一滴雨水的一天」, 它交出了一篇散文诗:云端的拥挤与等待、下坠时的狂欢、融入河流的安宁。文中堆了不少感官细节——瑟瑟发抖的触感、霓虹灯折射的视觉、呼啸风声的听觉。情感真挚, 意象丰富, 虽然还有些「优秀范文」的套路痕迹, 但已经超出了及格线。
有一说一,抛却纸面参数,Gemini 3 的实际水平是有目共睹的,而谷歌能在短时间内追平甚至超越 OpenAI 数年的积累,更是离不开作为为数不多的全栈 AI 厂商的硬实力。
谷歌的优势显而易见:自研 TPU 系列处理器带来的算力自主权,加上全球最大的数据宝库——搜索索引、学术文献、YouTube 视频库,这些都为 Gemini 的训练提供了强大助力。这或许也解释了为什么它在处理实时信息、多语言任务、视频理解等场景时表现更稳。
而就在刚刚,DeepMind 开发者体验主管 Omar Sanseviero 在 X 上发文称,今晚只是「热身」,接下来还将有更多功能陆续上线。结合此前的种种传闻,外界期待已久的 Nano Banana 2 可能真的离我们不远了。





