






MiniMax 闫俊杰和罗永浩四小时访谈:走出中国 AI 的第三条路,大山并非不可翻越
当整个 AI 圈都在为 DAU(日活跃用户数)和融资额焦虑时,MiniMax 创始人闫俊杰却表现出一种近乎冷酷的淡漠。
坐在罗永浩对面的闫俊杰,并不像一位掌管着 AI 独角兽企业的技术新贵。

他拒绝谈论改变世界,反而坦承恐惧。那种恐惧不是来自商业竞争,而是来自技术本身——当模型的能力开始超越人类时,创造者反而成了最先感到不安的人。
只要是一个东西能被量化,模型就一定会强于人,或者一定是能到最好的人类的那一档水平。所有做得比较成功的模型,在做出来之前都会有点害怕。
据晚点采访,在 MiniMax 内部,互联网行业奉为圭臬的 DAU ,被闫俊杰直接定义为「虚荣指标」。
在巨头环伺、算力短缺、热钱褪去的 2025 年,MiniMax 正在进行一场关于认知的修正:不再沿用移动互联网的逻辑,即通过大规模投放换取增长、通过堆砌功能留住用户,而是回归本质:把模型当作最重要的产品。
在大模型时代,真正的产品其实是模型本身,传统意义上的产品更像是一个渠道。如果模型不够聪明,产品做得再好也没有用。
在罗永浩和闫俊杰这期对谈里,我发现 MiniMax 这家 AI 公司从创业第一天就选择了注定与主流背道而驰的技术路径。
当所有人都试图寻找中国的 OpenAI 和 Sam Altman 时,闫俊杰却在试图证明「非天才」的价值。MiniMax 的故事不是关于天才的灵光乍现,而是一场关于如何在资源受限的缝隙中,通过极度理性地计算与修正,撕开一道通往 AGI 窄门的精密实验。
用 1/50 的筹码通往 AGI
MiniMax 过去三年的技术路线,表面看是一连串孤立的赌注,实则暗藏着一条统一的逻辑线索:在资源受限的前提下,如何用更聪明的方式优化,而非更多的算力堆砌,逼近 AGI 的上限。
当行业还在卷文本时,MiniMax 做了一个在当时看来极度冒险的决定:创业第一天就押注全模态。闫俊杰后来解释说,他们一开始就想得很清楚,真正的 AGI 一定是多模态的输入、多模态的输出。
三年多前创业时完全没有现成的技术路线,他们的策略就是每个模态至少先走通,等时机成熟再融合。这种坚持在当时备受质疑——业界主流认为应该先聚焦单一模态做到极致。
但闫俊杰的逻辑是,AGI 的本质是多模态融合,如果现在不同步推进,等到需要融合时技术债会成为致命伤。这种非共识的坚持,让 MiniMax 在 2025 年拥有了全球音频第一、视频第二、文本稳坐第一梯队的全模态能力。

前不久 OpenAI 的 Sora 2 通过多模态融合取得了显著成果,这在一定程度上也印证了 MiniMax 早在创业初期就选择这一技术路径的前瞻性。
但更激进的是,闫俊杰在创业初期就打破了 AI 研究的传统模式。
这是公司刚组建时打破的第一个认知——把大模型做好这件事一定不能迷信之前的经验,得用第一性原理拆开来看。大概在四五年前,人工智能领域大家追求的是写很多数学公式,把理论搞得很好、很花哨。
但这代人工智能最核心的其实就是 Scaling(缩放定律),就是让它能够用最简单的方法把效果做得更好,并且随着数据跟算力变多,效果就能够持续往上涨。
闫俊杰的技术直觉源自 2014 年在百度的实习经历。那时 Anthropic 的 CEO Dario Amodei 也在百度实习,正是在那里他发现了 Scaling Law 的雏形。
闫俊杰说,Scaling Law 其实在 2014 年做语音识别时就已经被发现了,但真正被广泛认知是大概 2020 年左右。「六年前就有了,并且那件事发生在中国公司,所以后面的事就有点遗憾。」
这段往事让闫俊杰意识到,中国并非没有机会,而是错失了把技术洞察转化为产业优势的时机。
现实是残酷的。闫俊杰很清楚中美之间的差距。他算过一笔账:美国最好的公司的估值是中国创业公司的 100 倍,收入基本上也是 100 倍,但技术可能就领先 5%,花的钱大概是 50 到 100 倍之间。
那为什么中国的公司可以花他们 1/50 的钱就做出来效果,差距可能只差 5%?核心原因是中国的人才还是非常好的。而更关键的是,中国的算力比美国有很大差距,因此必须得用更加创新的方式,才有可能做到同样的效果。
原则可能是一样,但方法上,在每个模块上其实都有很多创新。
算力限制不一定是诅咒,反而能成为倒逼创新的鞭子。
这就解释了为什么 MiniMax 从 2023 年起就率先探索 MoE 架构,为什么在 2025 年敢于押注线性注意力机制,又为什么在 M2 模型中回归全注意力机制。
每一次技术选择,都是在有限资源下寻找质量、速度、价格的三角平衡。
如果说 DeepSeek的逻辑是「用极致的工程优化榨干每一分算力」,那么MiniMax 就是在通过算法突破和机制创新在有限资源中撬动更大可能。
一个稳扎稳打,一个剑走偏锋。

其中一个出奇的创新, 是 MiniMax 在模型推理机制提出的「交错思维(Interleaved Thinking)」,让模型在「动手做事—停下来思考—再动手」的循环里推进任务。
这一新的机制很快推动了 OpenRouter、Ollama 等国外主流推理框架的适配支持,也带动 Kimi 和 DeepSeek 等国内模型陆续补齐类似能力。
但这些成果背后,更值得追问的是:一支没有硅谷海归坐镇、被外界视作「草根」的团队,如何做出全球领先的模型?
闫俊杰的回答出人意料。
AI 不是玄学,而是可以被第一性原理拆解的工程问题,比如算法该怎么设计,数据的链路该怎么搭建,训练效率该怎么优化,每个东西都有非常明确的目标。
正是基于这一判断,让闫俊杰放弃了寻找「天才」,转而相信科学方法论可以让普通人发挥非凡价值。 他还提到,公司的海归是不少的,但真正能起到关键作用的同学,很多人基本上都是第一份工作。
在 MiniMax 会议室墙上有一行字——Intelligence with Everyone,这是闫俊杰创业的初衷,也是不少人选择加入 MiniMax 的理由。

这行字今天也正在成为现实,全球超过两百个国家和地区的用户正在使用 MiniMax 的多模态模型,其中既有 2.12亿用户,也有 10 多万企业和开发者来创造更多产品和服务。
非天才主义的 AI 掌舵人
如果说技术路线的非共识是显性的,那么闫俊杰本人的成长轨迹,则是一场关于「反脆弱性」的修行。
闫俊杰出身河南小县城,在资源极度匮乏的环境下培养了极强的自学能力。
上小学的时候自己会看很多书,而且这些书有可能不应该是那个时间点的人来看的。比如很多高中甚至大学的书,上小学的时候提前就看。我爸爸是教初中的,就开始看初中的东西,上初中的时候就开始看高中的东西,高中的时候又开始学微积分,那些东西其实也没有人教,就是自己看。
小学自学初中,高中自学微积分——这种不受环境限制、超前学习的特质,贯穿了闫俊杰的整个创业生涯。当别人在等待导师指点时,他已经通过第一性原理自我拆解问题;当别人在抱怨资源不足时,他已经通过极致的自学能力补上了差距。
但自学能力并不意味着一帆风顺。这和闫俊杰在商汤受到的「残酷训练」不无关系。那时候他开始意识到要真正做一个最好的东西,就做了人脸识别,从倒数到第一大概花了一年半。
这一年半是非常痛苦的,每次技术测试都是倒数第几名,这种煎熬足以击垮大多数人。 但闫俊杰没有放弃,反而从这段经历中提炼出了核心方法论:一定要做取舍,一定要选一些更加长期、能够根本性发生变化的东西,而不是去做一些修补的东西。
经历这事之后,最核心的还是对自己这些最底层的判断有信心。
这段磨炼锻造了闫俊杰两个关键特质:一是极致的取舍能力,愿意放弃短期修补,聚焦长期突破;二是极高的心理韧性,能够承受长周期的失败和质疑。
这两个特质,恰恰是 MiniMax 能够在技术路线上坚持非共识这种近乎「佛系」的定力,让闫俊杰在硅谷银行危机、模型训练失败等困境中都能保持冷静。
中国 AI 的第三条路
MiniMax 的故事讲到这里,一个更大的问题自然浮出水面:当人才培养需要时间,技术追赶需要周期,中国 AI 公司靠什么在当下就建立自己的生存空间?
MiniMax 不一定是标准答案,但闫俊杰倒是有三个创业至今一直坚持的原则:
第一,不做项目,只做用户;第二,国内海外同时做。
2022 年,国内大厂还在观望 AI 是否值得投入,创业公司普遍选择 ToB 路径(做项目、卖解决方案)以求快速变现。但闫俊杰选择了最难的一条路:ToC,并且从第一天就瞄准全球市场。

因此,闫俊杰选择在海外更激烈的竞争中打磨技术,而非卷入国内与巨头的流量争夺。事实证明,这是正确的——MiniMax 在海外市场的 DAU 和付费率都维持在健康区间,而这正在成为它的护城河。
但最难的,是第三个原则:技术驱动 vs 用户增长。
这是对所有 AI 创业公司的终极拷问。闫俊杰坦白也纠结过,最终选择了前者,哪怕这意味着短期数据的牺牲、中层的流失和外界的质疑。
通过模型能力推动产品和业务发展,或者通过移动互联网时代的增长方式来发展,两者有可能都是对的,但它们是没法共存的。最后我们发现技术驱动的这种方式才适合我们。
在技术驱动的战略下,闫俊杰做出另外一个关键选择:开源。
年初 DeepSeek R1 横空出世后不久,闫俊杰曾表示,如果可以重新选,应该第一天就开源。在和罗永浩的对谈里他再次谈到开源。
实际上开源这件事,在手机操作系统上其实都发生过。苹果是闭源的,安卓是开源的,第二名后面的人必须得开源才有自己的独特定位,才能发出新的生态。
为了让我们能够进展,需要别人有选择我们的理由,模型的开放性恰好是一个非常重要的理由,因为它可以让你有足够强的技术信任,知道你的研发能力,也愿意更加深度来合作。
而 MiniMax 也延续着 DeepSeek 掀起的开源浪潮, MiniMax M2 发布后,大模型分析平台 Artificial Analysis 是这样介绍的:
中国 AI 实验室在开源领域持续保持领先地位。
MiniMax 的发布延续了中国 AI 在开源领域的领先地位,这一地位由 DeepSeek 在 2024 年底开启,并由 DeepSeek 的后续发布、阿里巴巴、智谱、和 Kimi 等公司持续保持。
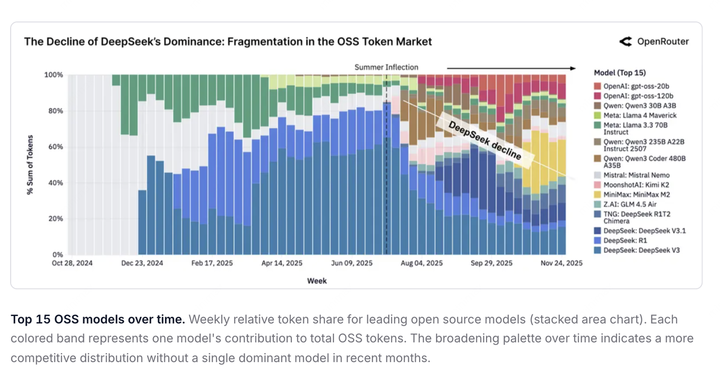
最近全球模型聚合平台 OpenRouter 联合a16z 发布了一份报告 State of AI 的100 Trillion Tokens ,可以看到 M2 开源之后,快速受到了全球开发者欢迎和采纳。
中国开源模型在全球使用量占比从 2024 年初的 1.2%,现在这个数字已经飙升至 30%,全球开源生态的重心已经向中国倾斜。
但这场竞赛远未结束。闫俊杰的判断是,算力和芯片的物理限制,决定了模型参数量和成本是有天花板的。在一个有限的参数量的情况下,不同的人来做不同的取舍,就一定会有些不一样的成果。
AI 不会一家独大,但也不会百家争鸣,最终会收敛到少数几家基于不同取舍的共存格局。
罗永浩关于「中国错失 GPT-3.5」的追问,闫俊杰展现出了一种务实的乐观。他表示把技术做好最重要的东西,说到底其实是两个词,一个是想象力,一个是自信。
美国那些企业很多浪潮是他们引领的,所以有自信在,要引领这个行业。在中国有些产业里面其实也是这样的,比如通讯、还有其他领域。
至少人工智能这个行业目前还没有到引领这个地步,但这个事情已经越来越具备了。
这或许就是中国 AI 公司需要走出的第三条路:
用更聪明的架构设计,对抗算力差距;
通过科学的组织进化,培养 AI 原生人才 ;
在夹缝中长出自己的形状,而非附庸于巨头。
MiniMax 的故事还在继续,中国 AI 的篇章墨迹尚未干。胜负不由起跑线决定,而由你选择在哪条路上、用什么样的节奏、坚持多久来定义。
闫俊杰在访谈中说道:
再往后三年看,即使不是我们,也会有中国其他的人能够做到这件事。
三年后,会是谁?又会用怎样的方式?
没有一部续集如此令人期待,因为我们都会是其中的角色。





