






实测即梦 Seedance 2.0:老外急着想注册,这就是中国 AI 视频的「黑神话」时刻
「来自中国的 Seedance 2.0 将成为最先进的技术。」
「这就是人工智能,我们完蛋了。」


▲在 X 上,多名 AI 视频创作者表示,Seedance 2.0 的表现相当出色
最近这几天,无论是抖音微信视频号,还是国外的 X 社交媒体等,Seedance 2.0 生成的 AI 视频都像病毒一样在传播。
除了一反常态的,是海外网友在找 +86 号码,注册即梦;还有大量的网友发帖子找攻略,在那些 AI 视频的评论区,都在求体验教程。更有甚者,说是倒卖即梦积分两天赚了 8000 多美元。
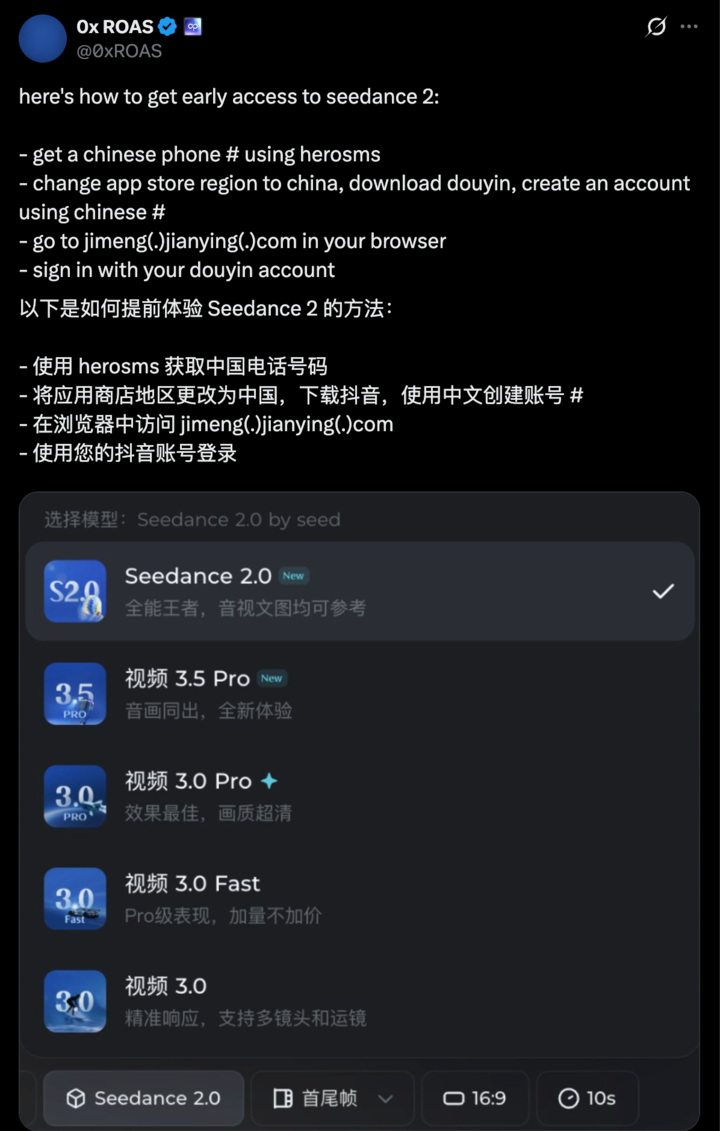


▲大量海外网友发 X 求一枚体验码,想尽办法能上即梦
Seedance 2.0 究竟能做把 AI 视频做成什么样?
轻松复刻人生切割术第一集里,从电梯出来到走廊的复杂运镜;还有自制一部超级大片,武打动作拳拳到肉;各种广告的 TVC 宣传片,液态玻璃效果都能拿捏;甚至还能说相声、演小品,春晚导演这回自己做主……

▲由字节自研视频生成模型 Seedance 2.0 生成,来源:X@qhgy / 抖音@虚妄
从简单的视频一致性,到复杂的高难度运镜,还有强大的创意模板功能、更准确和真实的音色、配合视频内容的音乐卡点,Seedance 2.0 这次几乎是把 AI 视频可能会遇到的问题,统统解决了。
APPSO 也在即梦里测试了一波最新的 Seedance 2.0 模型,只能说网友的反应都是真情实感,要好的提示词要抽卡也是存在的,但每一次生成的 AI 视频都太真实了。
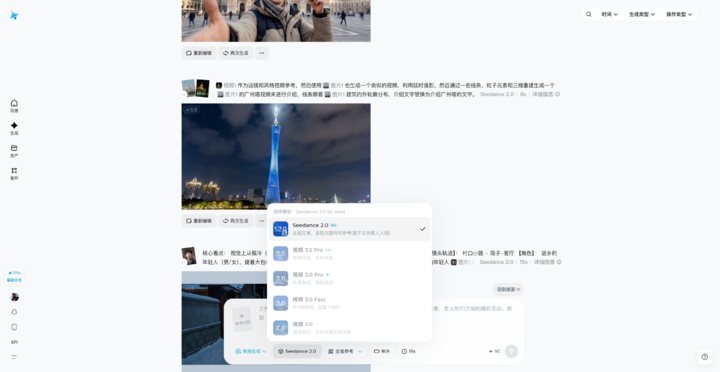
▲ 即梦 AI 官网地址:https://jimeng.jianying.com/ai-tool/generate
目前,在即梦官网,登录之后选择视频生成,就能使用字节自研视频生成模型 Seedance 2.0。
这一次,我们真的在指挥 AI 拍电影
选择 Seedance 2.0 模型,使用全能参考模式之后,光是看能输入的文件,就知道这次的升级不简单。
字节视频生成模型 Seedance 2.0 彻底打破了大多数模型存在的输入限制,以前的文本+首帧,或者是首尾帧都显得过时了。现在的 Seedance 2.0 把创作逻辑从头打造了一遍,支持图像、视频、音频、文本四种模态的自由组合。
一张图,可以是用来定下画面的美术风格,也可以作为视频的关键帧;一段视频,能直接复刻角色的动作和各种复杂的运镜;几秒音频,直接带起节奏和氛围;最后再加上一句提示词,串联起我们的所有想象。
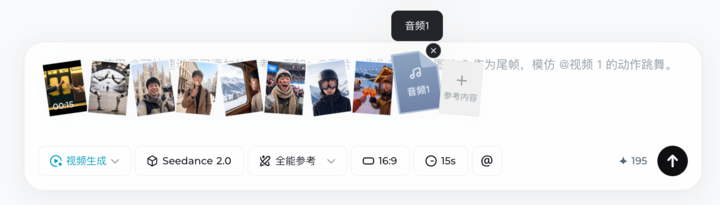
▲字节自研视频生成模型 Seedance 2.0 支持上传的文件上限是 12 个,图片最高 9 张,视频和音频文件都是最多 3 个,且总视频/音频长度不能超过 15s;生成时长可以选择 4-15s,不同时长消耗积分不同。
使用的方式也很简单,Seedance 2.0 目前支持「首尾帧」和「全能参考」入口,智能多帧和主体参考模式暂不支持。一般来说,我们只需要选择「全能参考」和模型「Seedance 2.0」,之后上传完所有的素材,官网提示尽可能把对最终生成视频影响较大的素材放在前面。
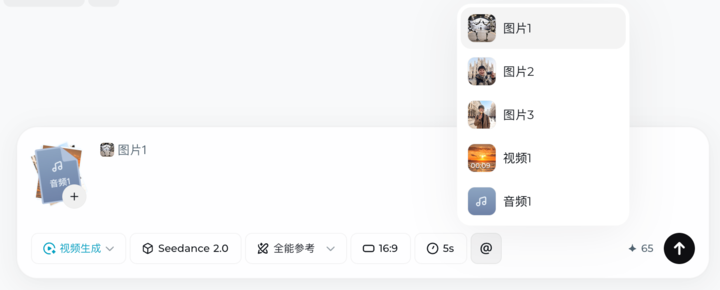
▲ 也可以直接点击输入框下方的 @ 按钮来选择使用不同的素材文件
接着,在提示词输入框里,通过 @ 直接调用对应的素材,串联成合理的提示词,然后等它「造梦」。我们不再需要绞尽脑汁去想「怎么描述这个动作/氛围/运镜/配乐/……」,只需要 @ 一下把它指给模型看。
如果说多模态输入解决了「怎么说」的问题,那模型内部的参考能力就是解决了「说什么」的问题。有了强大的深度视频参考能力,我们也生成了一些其他模型做不到的 AI 视频。
一打十,十八般武艺直接复制
以前想让 AI 模仿某个电影片段的名场面,我们得在提示词里面写「环绕镜头」、「快速切换」、这类专业术语,涉及到具体的武打动作,更是要化身武术指导,每一个动作怎么进行都要在提示词里面写清楚,结果还不一定对。
现在直接上传参考内容,AI 不仅能理解画面的整体风格,捕捉到角色细节;还能识别镜头语言、动作节奏、甚至创意特效,然后精准复刻。

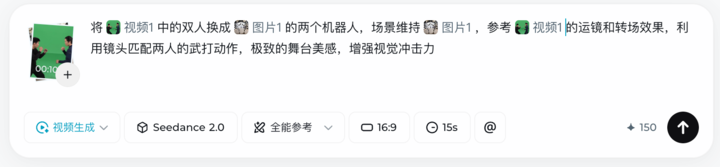
▲将@视频1中的双人换成@图片1的两个机器人,场景维持@图片1,参考@视频1的运镜和转场效果,利用镜头匹配两人的武打动作,极致的舞台美感,增强视觉冲击力
这里我们使用了 Seedance 2.0 使用手册内一段 10s 的打斗,然后告诉模型将视频中的两个人物动作,复制成我们上传的两个机器人。
最后生成的效果,完美复刻了视频动作,宇树和波士顿动力也能来一场酣畅淋漓的 PK,这不比前段时间微博之夜那表演的机器人强。

▲上传的视频和图片,以及使用的提示词
这些最终呈现的 AI 动作,完全修复了以前的模型,走路像飘,打架像软面条的问题。现在的 Seedance 2.0,就是一个懂物理,懂重力,懂惯性的模型,动作衔接更顺滑自然,也不再有那种诡异的「AI 感」。
拍摄现场最难的镜头,现在只要上传参考
除了能还原角色细节和动作,单纯的复刻运镜,Seedance 2.0 更是完全不在话下。以前那些难搞的电影级运镜、创意特效,现在同样是只需要上传参考视频,模型就能精准「照着拍」。

▲参考@视频1的运镜,用@图片1复刻这段视频
我们上传了一段苹果 F1 狂飙赛车的片段,和一张小米 SU7 Ultra 的图片。Seedance 2.0 能直接明白我的意图,把这张图片转成一个像 F1 开场的空拍镜头,再到聚焦 SU7 Ultra 的跟随镜头,一镜到底全过程,说这是大片一点都不过分吧。
这种镜头连贯性极强的一镜到底能力,还特别适合用来做这种舞蹈大片。我们从使用手册里找了一段 15s 的舞蹈视频,然后上传一张美美的自拍照。只是一次生成,完全没抽卡,就得到了这样一段音乐卡点、运镜自然的独舞视频。

▲将@视频1中的女生换成身穿蒙古族服饰的@图片1,场景在一个精美的舞台上,参考@视频1的运镜和转场效果,利用镜头匹配人物的动作,极致的舞台美感,增强视觉冲击力。
去年 Google Veo 3 视频模型火起来的时候,第一人称视角穿越讲述历史是当时的热门玩法,现在的 Seedance 2.0,热门玩法多到数不过来。这种结合游戏视角、画面还有角色一致性的视频,像是直接把黑神话悟空搬到了现实。

▲人物的背面参考@图片1,正面参考@图片2,面部细节参考@图片3。人物进入到游戏《黑神话:悟空》中,单挑二郎神杨戬,场景、动作、特效以及音乐音效可以参考@视频1。
更有意思的是,这里我们还使用了音频参考,我们可以上传一段视频,Seedance 2.0 会根据视频音乐的节奏和情绪来控制画面生成,打击的重音对应镜头切换,弦乐的渐强对应着动作的加速。
这也是声音第一次进入视频生成模型的参考,它从一个单独的后期背景音乐,变成了 AI 视频叙事的重要部分。
能参考,一段过年回家大戏也是说来就来
参考能力最大的价值在于解决实际创作问题,而参考能力的显著增强,归功于模型基础能力的提升。
我们尝试用一张首帧图片,和平时在其他视频生成模型里面会用到的提示词,丢给 Seedance 2.0,结果同样不出所料。

▲镜头跟拍年轻人 @ 图片 1 的背影。环境是除夕深夜的村道,路灯昏暗,只有风声和行李箱轮子在雪地里艰难拖动的「咕噜」声。他走得很累,停下来搓了搓冻僵的手,哈出一口白气(特写),眼神里透着「终于到了」的疲惫和一丝近乡情怯。
他转过一个弯,镜头随之旋转。远处出现了一扇贴着红对联的大铁门,门缝里透出金黄色的光。此时,远处零星的鞭炮声开始响起。他加快了脚步,推开沉重的铁门。
推开门的瞬间,镜头越过他的肩膀进入院子。满院子都是红灯笼。 一只土狗兴奋地扑上来,紧接着,厨房的门帘被掀开,母亲端着热气腾腾的蒸笼出来,蒸汽瞬间模糊了镜头边缘。 父亲正在挂灯笼,回头看到他,愣了一下;站在梯子上,假装淡定: 「哎?怎么才到?不是说五点吗?」 母亲放下蒸笼,冲过来拍打他身上的雪: 「你个老头子废话真多!——冷不冷?快进屋,刚出锅的肘子!」
镜头不再跟随背影,而是绕到正面,捕捉他的表情。他原本冻得僵硬的脸,被院子里的热气和灯光照亮,眼泪在眼眶里打转,但他却笑了。
除了视频一开始放下行李箱和手提包被直接忽视了,整个过程一镜到底的拍摄,还有角色表情动作的控制。我们只是上传了一张人像视频截图,然后告诉 Seedance 2.0 使用它的背影,它就能直接生成一个有模有样的过年回家短片。
即使丢掉大段的提示词,Seedance 2.0 的创意性和剧情补全能力也得到了进一步的提升。我们直接上传了一张爱乐之城的风格化图片,然后输入提示词,「根据@图片1创作一个歌舞片的欢快视频」。

Seedance 2.0 给我感觉是自己主动上强度,这个舞蹈视频的复杂程度,跟我看冬奥会双人组花样滑冰差不多了,而我的提示词里,没有参考视频,也没有具体动作指引,只是凭借模型自身的创意生成能力,就可以输出一个精彩的歌舞视频。
也有网友发挥自己的脑洞,使用了一些英雄联盟 双城之战第二季的角色,生成了一个 38s 的小短片。

▲由字节自研视频生成模型 Seedance 2.0 生成,来源:X@NACHOS2D_
AI 视频的《黑神话》时刻
字节视频生成模型 Seedance 2.0 惊艳的刷屏的程度,让我恍惚以为回到了 Sora 面世的那个春节。只不过这次,站在舞台中央的视频模型,来自中国。
黑神话制作人冯骥在体验后,在半夜直接表示「AIGC 视频生成的童年时代,正式结束了」,看完前面的实测你会发现,这还真是一个相当客观的评价。

某种程度上,Seedance 2.0 也可以说是 AI 视频的《黑神话》时刻。《黑神话:悟空》证明了中国能做出 3A 游戏,现在 Seedance 2.0 同样在 AI 视频赛道得到了全球的认可。
如果说去年的 Sora 2 是 AI 视频领域的「登月时刻」,那么今天的 Seedance 2.0 就是直接把飞船开到了你家门口,并把钥匙塞进了你手里,让你轻易得到「地表最强」的现货。
Seedance 2.0 没有创造神话,它只是完成了一次扎实的进化。它将视频生成的门槛拉低,同时将控制的上限拉高。在这个节点上,我们无需过度憧憬遥远的未来,而是应该以此为基点,思考如何利用这些日益成熟的工具,去讲述更好的故事。
即梦 Seedance 2.0 的「全能」与「低门槛」,才是这它最有价值的地方。
这或许才是对「Kill the game」最好的注解——它没有结束比赛,而是开启了更大的新游戏。当技术不再是瓶颈,真正的较量将回归到最本质的地方:那些能讲出好故事、拥有独特审美的人,将获得前所未有的杠杆。

▲麦肯锡一份探讨 AI 对电影电视影响的报告,提到 AI 内容可能在五年内重新分配 600 亿美元的内容生态市场|链接:https://www.mckinsey.com/industries/technology-media-and-telecommunications/our-insights/what-ai-could-mean-for-film-and-tv-production-and-the-industrys-future#/
小型工作室和独立创作者能制作高质量内容的机会越来越大,AI 内容 600 亿美元的产业价值将被重新分配。专业和业余的边界正在慢慢模糊,我们开始问自己「该做什么」,而不再问 AI 「能做什么」。
Seedance 这一波的强势,已经让我们看到了比 Sora 2 更强的音视频效果,无论是从真实世界的物理规律、还是角色的细腻情绪和复杂动作,Seedance 2.0 都可以称得上是目前的最优模型。
但当 AI 视频真实到这个程度,Sora 面对的那些问题,Seedance 似乎也变得无法回避。现实是,Seedance 2.0 内测火爆,不少海外创作者都在喊「一码难求」,但也因为生成效果过于逼真,已经引发了不少关于「AI 视频造假」的伦理讨论。
今年 AI 的进化已经让人无所适从,Seedance 2.0 的火爆,肯定也远远超出了即梦的预料,即梦也很快面对这些争议做出了回应。
在 9 号刷屏全网当天,即梦运营在创作者社群内发布了正式通知,宣布暂时限制真人人脸素材的使用和视频生成。目前一些传播的真人案例,也都是在内测第一时间生成的。
▲即梦 AI APP 内出镜功能,在创建 AI 分身之后能创作真人视频
不过,真人想要出镜,在即梦 AI 的 APP 内,使用出镜功能,完成真人校验后,我们就能体验真人 AI 视频生成。
越强大的工具,越需要清晰的使用边界。但此刻,或许在还没有找到完美答案之前,我们能做的,就是先想清楚自己想用这个工具做什么,记录生活、表达创意,还是讲述故事?

如果说杨德昌在《一一》里面说着,「电影发明了以后,我们的生命延长了三倍」,那现在 AI 电影的发明,则更像是开始在重构生命。我们不再满足于延长,每个人都可能成为自己故事的编剧,在无限叙事中探索另一种人生。
Seedance 2.0 开始让这一切变得越来越近,而现在还只是 2026 年的开端。
*文章部分视频播放,可前往微信图文链接预览





