





新时代新潮流 WebOS 【19】走进 WebKit
1. 总体结构
Webkit是开源项目,它的源代 码可以去这里下载。Webkit是一个相当复杂的软件系统,打开源 代码,可以看到里面有众多文件夹。但是Webkit的源代码组织得很好,虽然程序多,但是结构清楚。相对而言,Firefox浏览器使用的Gecko渲染机的源代码,个人的感觉比较乱,不容易理出头绪。
毛主席教导我们,“我们的方针是路线决定一切,人多,枪多,代替不了正确的路线。路线正 确就有一切,路线不正确有了也可以丢掉。路线是个纲,纲举目张”。 对于软件工程,主席的教导依然具有指导意义。不妨把主席的教导改动一下,“软件工程的方针是结构决定一切,代码多,功能多,代替不了正确的结构。结构正确了,不断改进以后就有一切,结构不正确,有了也可以丢掉。结构是个纲,纲举目张”。现代软件工程的语汇里,结构多半特指object-oriented的 结构。Webkit源代码十分严格地遵循object-oriented的原则来组织,这样做的好处不仅仅有利于后续开发和维护,而且也便于研读源代码。
Webkit 源代码由三大部分组成,1. WebCore,2. WebKit,3. JavaScript。当输入一个HTML文件,WebCore的职责是解析每个HTML Tag,以及它们之间的从属关系,生成一棵树状的数据结构(DOM Tree),然后结合HTML文件中指定的CSS定义,确定DOM Tree中每个节点的在整个页面中的位置,以及颜色字体等等,也就是布局与渲染。布局与渲染效果的确定,以属性和属性值的形式,存放在另一棵树状数据结构中,这另一棵树被称为Rendering Tree。通常情况下,Rendering Tree的结构与DOM Tree大致相同,基本上DOM Tree里面每一个节点,在Rendering Tree里都有对应的节点。
这里有两个疑问,1. 为什么既有DOM Tree,又有Rendering Tree,合二为一不是更省内存吗?2. Rendering Tree为什么要与DOM Tree保持一致?不一样又如何?这两个问题,我们稍后讨论。
Rendering Tree只是确定了该如何渲染HTML页面,有点像司令部里的参谋们制订作战计划。但是具体的渲染,包括画点画线字体等等,在不同的OS,甚至不同的硬件环境下,实现的方式各不相同,这就像冲锋陷阵,还得靠前线将士。Webkit源代码中的WebKit package,里面包含的程序,就是这些前线将士。WebKit package中有 win, mac, gtk, qt, wx等等 subpackages,就是针对各个不同OSes,以及各种不同的跨平台的图形库,所采取的因地制宜的渲染手段。与各个不同的OSes相关的,不仅仅是渲染,还有鼠标移动和键盘点击等等用户触发的UI事件的捕捉。所有这些与具体Oses相关的程序,通通被放置在WebKit package中。
Webkit源代码中第三个主要部分,是JavaScript engine。JavaScript engine用来解析JavaScript代码,并执行。这个系列里不展开介绍JavaScript engine。
2. DOM Tree 与 Rendering Tree 是否必须一致?
“ 天下文章一大抄”,这话说来难听,但是却是实情。很少有文章从头到尾,字字原创,而绝大多数都是在消化整理前人和他人的知识基础上,添加自己的一点点发挥和创造而成。人类的文明进步,就是这样一点一滴,逐渐积累起来的。既然文章离不开引经据典,旁征博引,阅读文章的时候,也就免不了需要查阅相关文献。
在Web出现以前,查阅文献是一件费时费力的事情。1989年3月,在欧洲原子能研究组织(CERN)工作的Tim Berners-Lee,提议在TCP/IP协议基础之上,建立一个相互链接的信息系统。这个建议很快发展成为万维网(World Wide Web,简称Web),极大地方便了文献的查阅。Web的核心,是hyperlink。在撰写网页时,可以对于某些词句,设置隐含的 hyperlinks。当读者点击这些词句时,计算机就会根据词句背后隐含的hyperlink,自动打开另一个网页。请注意“隐含的”这个词,这意味着 文章的显示(Presentation),与文章的内容(Content)并不完全一致。
Tim Berners-Lee考虑到这一问题,于是建议给每个Web网页制订一个规范,这个规范就是“超文本标识语言”,简称HTML。最初的HTML制订了 22个标识,标注两方面的功能,1. 内容,包括引用,2. 显示格式。在同一份HTML文件里,把内容和格式混杂在一起,这是一个设计错误。20年过去了,现在的HTML文件,基本上是以内容为主,格式被分离出去, 由CSS定义。除此之外,还增加了与读者互动的动作,这些互动动作,通常由JavaScript定义。
为什么分离比合并好?同一份内容,针对不同的读者,可以通过不同的CSS,改变显示的方式,举几个例子。针对新人类,可以用卡通图标替代某些特定文字。针对老派读者可以换用大号字体,从上往下,从右往左排版。对于正在开车的听众,可以用朗诵替代文字显示。
内容与格式分离,并不等同于DOM Tree与Rendering Tree并存。假如内容由HTML承载,格式由CSS定义,我们可以只用一棵树,不仅存放内容,也存放格式属性。DOM Tree与Rendering Tree分离,好处在于同一棵DOM Tree,可以对应多棵Rendering Trees,也就是同一个内容,可以由多种不同的方式来布局和渲染。在当今的浏览器里,一棵DOM Tree对应多棵Rendering Trees的情况不常见,因为同一个页面,通常只有一种风格的布局和渲染。但是在电子游戏中,同一个场景会有多个不同视角,譬如枪战游戏中,有枪手本人视 角,有旁观者视角,还有俯瞰视角等等。换句话说,Webkit不仅满足了当今浏览器的普通需要,而且提供了一些尚没有被广泛利用的潜在的功能。把DOM Tree与Rendering Tree分离的做法,虽然浪费了一些内存空间,但是着眼于未来,Webkit这样的结构设计,为未来的发展埋下了伏笔。
目前而言,Rendering Tree的结构基本上与DOM Tree的保持一致,DOM Tree里每一个节点,在Rendering Tree都有对应节点,父子节点之间的继承关系也保持一致。但是Webkit的代码,给Rendering Tree结构的异化,也埋下了伏笔。Rendering Tree的结构,不一定与DOM Tree保持一致。举个例子,或许未来的网页可以提供个性化的编辑方式。当读者第一次打开某个页面的时候,看到的是标准的页面,也就是Rendering Tree与DOM Tree保持一致的页面。读者可以摘录网页中某些段落,删除不感兴趣的段落,改变着色,改变字体,甚至重新布局。以后再次造访这个页面时,这位读者就可以看到个性化的页面,而所谓个性化的实现方式,其实就是构筑另一棵Rendering Tree。假如他想恢复标准的网页,只需要重新调用标准的Rendering Tree,重新渲染一遍网页即可。在这个例子里,我们可以看到个性化的Rendering Tree,与DOM Tree保持一致的标准的Rendering Tree,两者并存的场景。
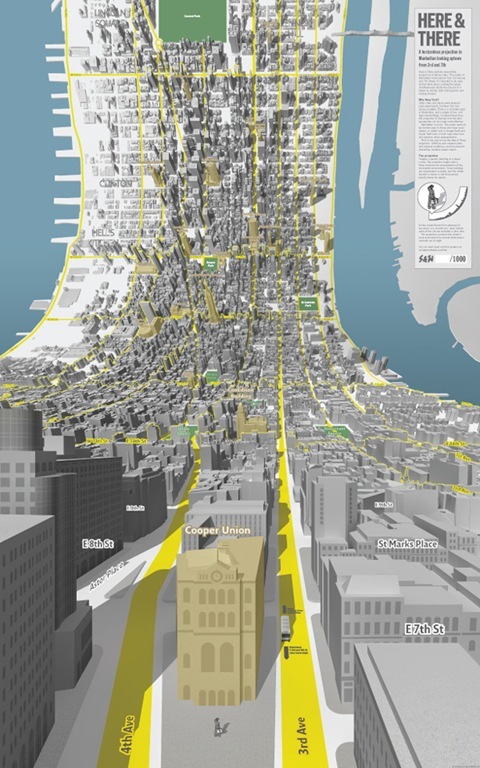
再举一个例子,通常的地图,都是俯瞰图,整个地图保持同一种视角。能不能在同一张地图中包含多个视角?听起来匪夷所思,但是有人尝试了这种新奇大胆的设想,见figure 1。如果套用DOM Tree和Rendering Tree的概念,可以解释为DOM Tree与Rendering Tree不完全一致。上半段的俯瞰视角的地图,对应的Rendering Tree的子树,与DOM Tree相关子树一一对应。但是下半段的平视视角的地图,对应的Rendering Tree的子树,是DOM Tree相关子树的一个子集,因为有些楼宇和道路,被前方的楼宇遮挡住了。
 Figure 1. Here-and-there map of Mahanttan
Figure 1. Here-and-there map of Mahanttan





