





为您查询到 篇文章
2023年10月11日,北京金秋时节,第九届HAOMO AI DAY如期而至。本届HAOMO AI DAY以 “BETTER AI,BETTER HAOMO”为主题。毫末重磅发布三款“极致性价比”千元级无图NOH,全面满足高中低价位智驾车型量产需求;毫末发布的行业首个自动驾驶生成式大模型DriveGPT雪湖·海若公布最新成果:共计筛选出超过100亿帧互联网图片数据集和480万段包含人驾行为的自动驾驶4D Clips数据;进一步升级引入多模态大模型,获得识别万物的能力;与NeRF技术进一步整合,渲染重建4D空间;借助LLM(大语言模型),让自动驾驶认知决策具备了世界知识。产品层面,搭载毫末城市NOH功能的魏牌蓝山将在2024年第一季度正式量产上市;小魔驼即将在2023年第四季度在商超履约配送场景实现盈利。

毫末董事长张凯表示:“毫末一直在全力以赴投入到AI自动驾驶的技术浪潮中,毫末坚持的渐进式路线与对技术投入的长期主义,让毫末模式成为中国自动驾驶发展的新范式。”
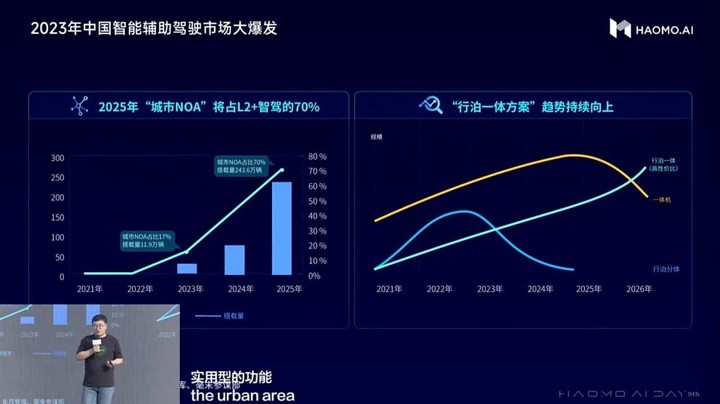
张凯介绍,目前乘用车销量和智能化指数都在稳步提升,同时智能驾驶渗透率与价格却呈反向增长,乘用车市场L2及以上智能驾驶渗透率达42.4%,2025年将达70%,并普及到10-20万的主销车型上;城市NOA迎来量产上车潮,目前占L2及以上辅助驾驶份额的17%,2025年将达70%;行泊分体的硬件设计、一体机逐步退出市场,更具性价比的行泊一体的域控方案将成为主流。

为了迎战智驾市场的变化,现场,毫末重磅发布了HP170、HP370、HP570三款“极致性价比”智能辅助驾驶产品,预计将在2023年和2024年先后上车。
毫末HP170是3000元级“极致性价比”的高速无图NOH,可以实现行泊一体智驾。硬件配置上,算力5TOPS,传感器方案标配1个前视相机、4个鱼眼相机、2个后角雷达、12个超声波雷达,灵活选装1个前视雷达和2个前角雷达。场景上,可实现高速、城市快速路上的无图NOH,短距离记忆泊车等功能,并获E-NCAP 5星AEB的高安全标准认证。

(毫末HP170)
毫末HP370是5000元级“极致性价比”的城市记忆行车与记忆泊车,可以实现行泊一体智驾。硬件配置上,算力32TOPS,传感器方案标配2个前视相机、2个侧视相机、1个后视相机、4个鱼眼相机、1个前雷达、2个后角雷达、12个超声波雷达,灵活选装2个前角雷达。场景上,可实现高速、城快,以及城市内的记忆行车,免教学记忆泊车、智能绕障等功能。张凯表示:“毫末的记忆行车可看作毫末城市NOH的最小集,是城市NOH的强有力补充。”

(毫末HP370)
毫末HP570是8000元级“极致性价比”的城市全场景无图NOH产品,未来将在100+城落地。硬件配置上,算力可选72TOPS和100TOPS两款芯片,传感器方案标配2个前视相机、4个侧视相机、1个后视相机、4个鱼眼相机、1个前雷达、12个超声波雷达,还支持选配1颗激光雷达。场景上,可实现城市无图NOH、全场景辅助泊车、全场景智能绕障、跨层免教学记忆泊车等功能。张凯强调:“HP570平台的历史使命是打造行业内最具性价比的高阶城市智驾产品。”

(毫末HP570)
历届HAOMO AI DAY的核心主题都是聚焦最硬核的自动驾驶AI技术。此次,顾维灏带来了主题为《自动驾驶3.0时代:大模型将重塑汽车智能化的技术路线》的演讲,分享了毫末对于自动驾驶3.0时代AI开发模式的思考以及毫末DriveGPT大模型的最新进展和实践。

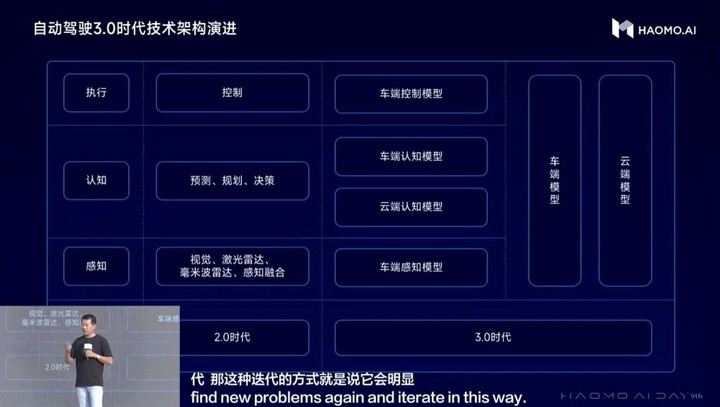
顾维灏认为,自动驾驶3.0时代与2.0时代相比,其开发模式和技术框架都将发生颠覆性的变革。在自动驾驶2.0时代,以小数据、小模型为特征,以Case任务驱动为开发模式。而自动驾驶3.0时代,以大数据、大模型为特征,以数据驱动为开发模式。
相比2.0时代主要采用传统模块化框架,3.0时代的技术框架会发生颠覆性变化。首先,自动驾驶会在云端实现感知大模型和认知大模型的能力突破,并将车端各类小模型逐步统一为感知模型和认知模型,同时将控制模块也AI模型化。随后,车端智驾系统的演进路线也是一方面会逐步全链路模型化,另一方面是逐步大模型化,即小模型逐渐统一到大模型内。然后,云端大模型也可以通过剪枝、蒸馏等方式逐步提升车端的感知能力,甚至在通讯环境比较好的地方,大模型甚至可以通过车云协同的方式实现远程控车。最后,在未来车端、云端都是端到端的自动驾驶大模型。
顾维灏还详细介绍了毫末DriveGPT大模型在推出200天后的整体进展。首先是DriveGPT训练数据规模提升。截止2023年10月DriveGPT雪湖·海若共计筛选出超过100亿帧互联网图片数据集和480万段包含人驾行为的自动驾驶4D Clips数据。其次是通用感知能力提升,DriveGPT通过引入多模态大模型,实现文、图、视频多模态信息的整合,获得识别万物的能力;同时,通过与NeRF技术整合,DriveGPT实现更强的4D空间重建能力,获得对三维空间和时序的全面建模能力;最后是通用认知能力提升,借助大语言模型,DriveGPT将世界知识引入到驾驶策略中。
顾维灏认为,未来的自动驾驶系统一定是跟人类驾驶员一样,不但具备对三维空间的精确感知测量能力,而且能够像人类一样理解万物之间的联系、事件发生的逻辑和背后的常识,并且能基于这些人类社会的经验来做出更好的驾驶策略,真正实现完全无人驾驶。
毫末DriveGPT是如何具备识别万物的通用感知能力,以及拥有世界知识的通用认知能力?顾维灏也给出了详尽解释。
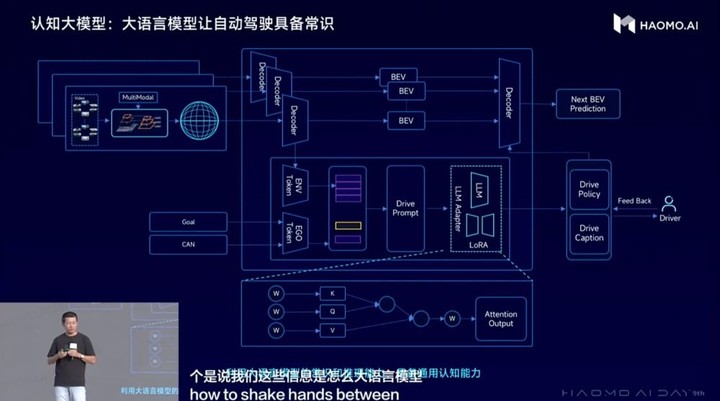
(毫末DriveGPT升级:大模型让自动驾驶拥有世界知识)
在感知阶段,DriveGPT首先通过构建视觉感知大模型来实现对真实物理世界的学习,将真实世界建模到三维空间,再加上时序形成4D向量空间;然后,在构建对真实物理世界的4D感知基础上,毫末进一步引入开源的图文多模态大模型,构建更为通用的语义感知大模型,实现文、图、视频多模态信息的整合,从而完成4D向量空间到语义空间的对齐,实现跟人类一样的“识别万物”的能力。

在分享了最新DriveGPT大模型技术框架后,顾维灏随后也给出了毫末基于DriveGPT大模型开发模式的七大应用实践,包括驾驶场景理解、驾驶场景标注、驾驶场景生成、驾驶场景迁移、驾驶行为解释、驾驶环境预测和车端模型开发。
[展开]版权所有 © 广州利沃致远投资管理合伙企业(有限合伙) 2008 - 2023。以商业目的使用爱范儿网站内容需获许可。非商业目的使用授权遵循 CC BY-NC 4.0。
All content is made available under the CC BY-NC 4.0 for non-commercial use. Commercial use of this content is prohibited without explicit permission.
if Design Studio.





