





热门搜索
为您查询到 篇文章
7月25日,星期五
2025-07-25 15:04
清华 × 生数发布机器人通用大模型 Vidar
7 月 25 日,清华大学与生数科技联合研发的 Vidar 模型,首次让通用视频大模型长出了「手脚」,通过少样本泛化能力,实现从虚拟的 Dream World 到真实世界 Real World 物理执行的关键跨越。
官方表示,这项创新不仅打破了传统具身智能的数据桎梏,更开创了「虚实互通」的全新范式,有望真正实现具身智能的 scaling law。
据悉,Vidar 是全球首个基于通用视频大模型实现视频理解能力向物理决策系统性迁移的多视角具身基座模型。该模型创新性地构建了支持机器人双臂协同任务的多视角视频预测框架,在保持 SOTA 性能的同时,展现出显著的少样本学习优势。
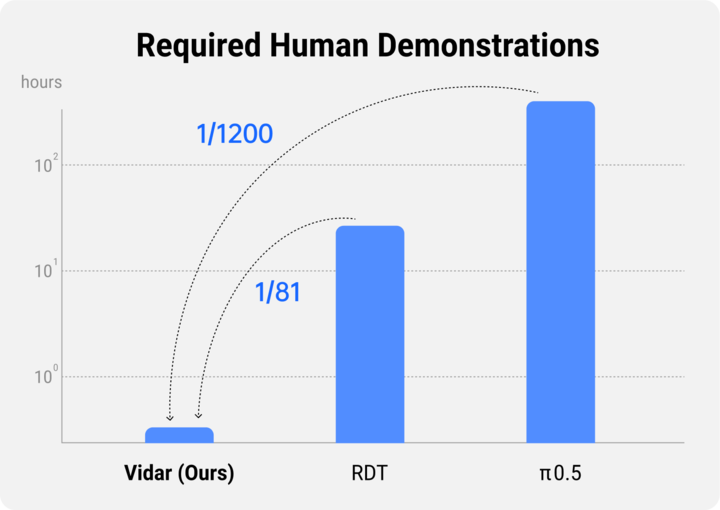
为让模型更「见多识广」,实现多类型机器人操作的深度融合,灵活适应各种物理环境,清华大学和生数团队创新性地提出了基于统一观测空间的具身预训练方法。这套方法巧妙运用统一观测空间、海量具身数据预训练和少量目标机器人微调,实现了视频意义上的精准控制。
在视频生成基准 VBench 上的测试表明,经过具身数据预训练,Vidu 模型在主体一致性、背景一致性和图像质量这三个维度上都有了显著的提升,为少样本泛化提供了有力支撑。
具体表现上,在 16 种常见的机器人操作任务上,Vidar 取得了远超基线方法的成功率;再细分到类别,Vidar 在没见过的任务和背景上的泛化能力尤为突出。
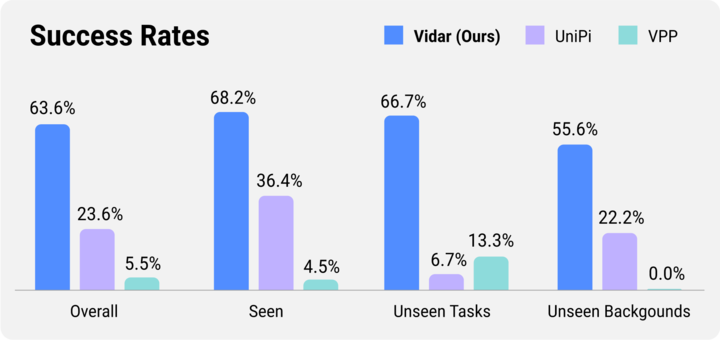
目前,试验项目与论文均已上线。
- 论文链接:https://arxiv.org/abs/2507.12898,https://arxiv.org/abs/2507.12768
- 项目链接:https://embodiedfoundation.github.io/vidar_anypos
加载更多
版权所有 © 广州利沃致远投资管理合伙企业(有限合伙) 2008 - 2023。以商业目的使用爱范儿网站内容需获许可。非商业目的使用授权遵循 CC BY-NC 4.0。
All content is made available under the CC BY-NC 4.0 for non-commercial use. Commercial use of this content is prohibited without explicit permission.
Designed by

if Design Studio.
关注 if Design Studio.
微信扫码关注公众号 if Design Studio.




