






苹果、Google、微软、亚马逊,哪家的语音助手会的语言最多,以及为什么?
2018 年 9 月,一家叫 Vocalize.ai 的人工智能初创公司做了一项测试,它比较了 Google、苹果和亚马逊的智能语音助手,发现了一些有意思的事情。
比如,三家语音助手都能很好地识别美式口音和印度式口音的英语,但 Siri 和 Alexa 在识别中式口音时,准确度都大幅下降。
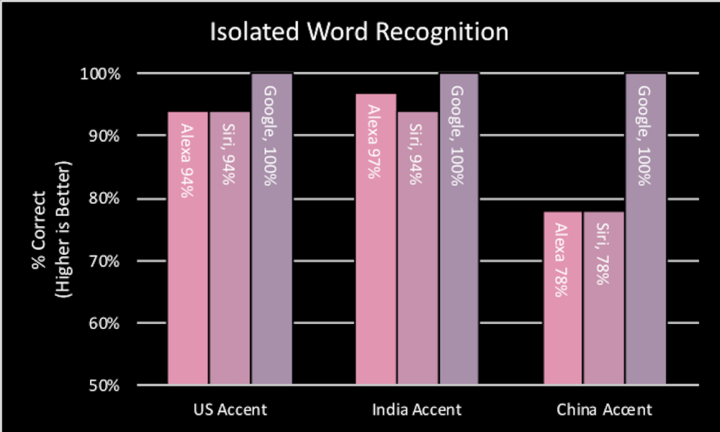
对语音助手来说,识别同一种语言的不同口音已经是个挑战,而要「学会」一种新语言则更加困难。
比如,直到今年秋天,三星的 Bixby 才会增加对德语、法语、意大利语和西班牙语的支持,这些语音加起来有超过 6 亿的使用者;微软的 Cortana 用了很多年才支持西班牙语、法语和葡萄牙语。
在人工智能取得重大突破并飞速发展的今天,为什么语音助手的发展如此缓慢?人类要重建巴别塔,该如何努力呢?
为什么语音助手支持一种新语音这么难?
语音助手要「学会」一门语言主要有两个大课题:声音识别和声音合成。
声音识别又分成两个部分,第一步是将语音转成文字的语音识别,第二步是语义理解,涉及的技术主要是自然语言处理。
深度学习的突破是人工智能在最近几年飞跃发展的重要原因。目前,语音研究领域也主要使用深度神经网络——一个像人类神经一样的分层数学函数,可以不断自我学习和进步。

▲ 图片来自:electronicsweekly
这已经是一个巨大的进步。过去的自动语音处理技术(ASR)主要依赖手动调整的统计模型来计算短语中词组合的概率,深度神经网络不仅降低了错误率,而且在很大程度上避免了人为监督的需要。
但基础的语言理解还远远不够,本地化依然是个巨大的挑战。有技术人员透露,目前,根据要涵盖的意图,新语言构建查询理解模块需要 30 到 90 天。如开头所说,即使是识别同一种语言的口音,都是巨大的挑战。
不同语言的差别更大。比如在语法层面,英语中形容词通常出现在名词前,而副词既可以在前,也可以在后。对语音助手来说,这就很容易产生迷惑,比如「海星」(starfish)这个词,语音转文字的引擎很容易将「星星」(star)理解为「鱼」(fish)的形容词。
将语音处理为文字并加以理解后,语音助手还必须以人类的声音来回复。
传统的语音合成技术主要包括一个合成引擎和一个预先录入的语音数据库,合成引擎通过计算机软件查找语音数据库中匹配的读音把文本转化为语音。但是,这种「人造的语音」非常不连贯,听上去也很不自然。为了覆盖更多的词,传统的语音数据库通常也非常大。
现在的语音合成技术被称为 TTS(文本转语音),它使用数学模型重新创建声音,然后组合成单词和句子。 最新的 TTS 同样引入了深度学习,可以在「训练」的过程中越来越强。
目前,相比语音识别和语义理解,语音合成的技术要成熟很多。中国各大互联网公司也经常在运营活动中使用语音合成技术。
几大语音助手分别支持哪些语言
Google Assistant
Google 的语音助手支持的语言最多,目前它在 80 个国家支持 30 种语言,包括:
- 阿拉伯语(埃及,沙特阿拉伯)
- 孟加拉语
- 中文(繁体)
- 丹麦语
- 荷兰语
- 英语(澳大利亚,加拿大,印度,印度尼西亚,爱尔兰,菲律宾,新加坡,泰国,英国,美国)
- 法语(加拿大,法国)
- 德语(奥地利,德国)
- 古吉拉特语
- 印地语
- 印尼语
- 卡纳达语
- 意大利语
- 日语
- 韩语
- 马来语
- 马拉地语
- 挪威语
- 波兰语
- 葡萄牙语(巴西)
- 俄语
- 西班牙语(阿根廷,智利,哥伦比亚,秘鲁)
- 瑞典语
- 泰米尔语
- 泰卢固语
- 泰语
- 土耳其语
- 乌尔都语
苹果的 Siri
2018 年被 Google Assistant 超过后,Siri 目前支持的语言数排第二名。包括 36 个国家的 21 种语言:
- 阿拉伯语
- 中文(普通话,上海话和广东话)
- 丹麦语
- 荷兰语
- 英语
- 芬兰语
- 法语
- 德语
- 希伯来语
- 意大利语
- 日语
- 韩语
- 马来语
- 挪威语
- 葡萄牙语
- 俄语
- 西班牙语
- 瑞典语
- 泰语
微软的 Cornata
- 简体中文
- 英语(澳大利亚,加拿大,新西兰,印度,英国,美国)
- 法语(加拿大,法国)
- 德语
- 意大利语
- 日语
- 葡萄牙语(巴西)
- 西班牙语(墨西哥,西班牙
亚马逊的 Alexa
- 英语(澳大利亚,加拿大,印度,英国和美国)
- 法语(加拿大,法国)
- 德语
- 日语(日本)
- 西班牙语(墨西哥,西班牙)
三星的 Bixby
- 英语
- 中文
- 德语
- 法语
- 意大利语
- 韩语
- 西班牙语
未来会如何发展?
在语音识别、语义理解和语音合成领域,它们取得进步的主要原因是引入深度学习。
未来,更加依赖机器学习可能对语音领域的研究有更大的帮助。
「处理多语言支持伴随着不同的语法规则,这也是目前主要的挑战之一,语音处理模型必须考虑并适应这些语法规则,」人工智能公司 Clinc 的副总裁 Himi Khan 解释到, 「大多数自然语言处理模型采集句子,进行词性标注——在某种意义上识别语法,并创建规则来确定如何解释该语法。」

▲ 传说中的巴别塔,因上帝将人类的语言打乱而中止建设. 图片来自:jonathanpark
而未来,如果有了一个真正的神经网络堆栈——一个不过多依赖语言库、关键词和词典的系统,可以将关注语言改为研究词的嵌入,以及嵌入后的连接模型。那么,「它就可以应用在几乎所有语言的语音识别上。」
这只是一个研究方向。但总体来说,使用海量的真实对话作为语料供机器学习,而不过多依赖人工定义的识别模型,可以有效地帮助语音助手更加「聪明」。
题图来自:thewiredshopper





