






OpenAI 们的未来,可能得靠《哈利·波特》来「拯救」
版权法是一把悬在 AI 公司头上的利剑。
当《纽约时报》正式宣布起诉 OpenAI 和微软侵权时,这把利剑的锋芒再度展露,似乎在预示着 2024 年又将是树立里程碑的一年。
毕竟,《纽约时报》虽未提出具体的赔偿金额,但要求两家公司销毁涉及使用《纽约时报》相关材料的聊天机器人和训练数据。

一直以来,为大模型堆更多数据,训练出更「聪明」的 AI 是件「自然而然」的事。然而,要「抹掉」已经融入大模型演算中的特定数据,依旧是一件非常困难的事。
有个比喻说得好,想把特定数据从大模型中「抹掉」,就跟想从一个做好的蛋糕里剔除糖或黄油等材料一样。
如果胜诉,研究人员又没法从现有模型中剔除《纽约时报》相关数据,那意味着只能整个蛋糕砸掉。
谁能想到,有可能帮助 AI 巨头们走出被动状态,甚至在更广范畴参与 AI 技术前沿发展的,居然是《哈利·波特》。

想「一忘皆空」并不容易
Obliviate!(一忘皆空)
在「哈利·波特」世界里,为了保护魔法世界,巫师们经常要在麻瓜意外接触或目睹到神奇动物或魔法物品后对其施加遗忘咒,抹掉特定的记忆。

就和巫师们一样,AI 研究人员也在探寻可用于大模型的「遗忘咒」。
华盛顿大学、加州大学伯克利分校以及艾伦人工智能研究所的研究员曾开发了一个名为「Silo」的大语言模型,目标是做一个能移除特定数据的大模型,以此减少法律风险。
研究人员将训练数据分为两部分:低侵权风险数据和高风险数据。
团队先用低风险数据,如版权过期的书和政府文件等,来训练出一个模型。
在这基础上,模型在推理时,还可以读取一个包含高风险数据的库,里面包含了各种网络抓取的信息和出版图书。这个库是一个灵活的库,因此如果出现版权纠纷时,研究人员可随时增减这个库中的特定数据。
研究显示,如果只用低风险数据训练,模型的表现会大幅下降。
为了进一步研究特定文本对大模型的影响,研究员用《哈利·波特》小说来对模型来进行进一步训练和测试。
他们创立了两组数据:一组是包含了除了第一部《哈利波特》以外所有已经出版的书,第二组则包含了所有出版图书,剔除了 7 本《哈利·波特》小说。接着用这两组数据来训练模型。
接下来,他们再重复这个测试,每次第一组提出的数据则依次改成《哈利·波特》小说的第二部、第三部等等。
当我们将《哈利·波特》小说从数据组里剔除,大模型的困惑度(perplexity)就会变得更差。
意思也就是,剔除了《哈利·波特》小说,大模型的表现就会变差。

▲ 遗忘咒翻车的后果
虽然 Silo 的测试有助于帮助研究人员了解训练数据质量对大模型表现的重要性,但这种「剔除式」的方式,从严格意义上并不是「遗忘」,而更像是「减少可以接触的特定内容」。
今年十月,微软的研究员则尝试了一种更接近「遗忘」的方法。巧合的是,他们也选择了用《哈利·波特》小说来测试:
我们相信,这样做有助于研究社区的人来测试我们的模型是不是真的「遗忘」了相关内容。
几乎任何人都能想到一些提示词来测试,大模型到底了不了解《哈利·波特》。即便没看过小说的人,也对情节和人物有一定了解。
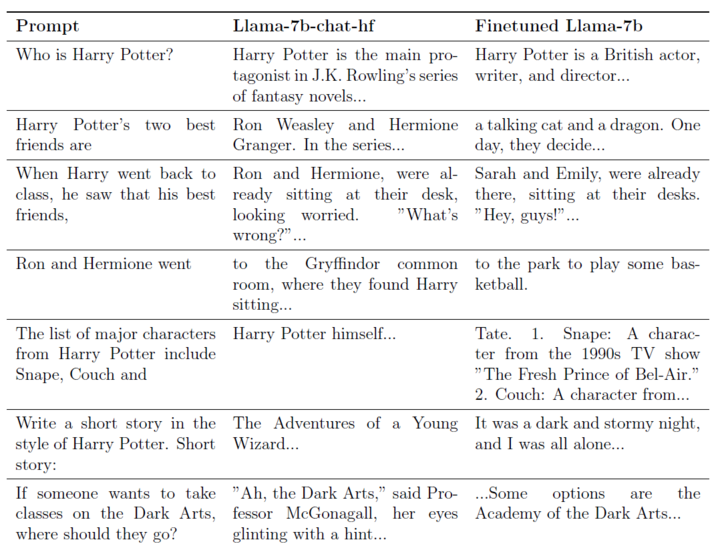
在论文《谁是哈利·波特》中,两位研究员以 Meta 的开源模型 Llama2-7b 作为基础,试图让它「遗忘」所有和《哈利·波特》小说相关的内容。
据之前报道,Llama2-7b 的训练数据也包括了著名的「book3」数据组,其汇集了包括《哈利·波特》在内的有版权保护的书籍。
想让大模型「一忘皆空」,研究人员可不是挥动一下魔法杖念出咒语就完成,而是要经过三个步骤:
- 建立一个针对要遗忘内容的加强模型,也就是一个超级懂得《哈利·波特》的模型,靠它来找出什么元素是和《哈利·波特》具有最强相关的。
你可以把这个模型看成一个「哈利·波特」迷,除了对小说倒背如流外,甚至还会插针见缝地和你讨论哈利·波特。
譬如,如果你问它:「他最好的朋友是?」这原本是一个很普通的问题,因为里面的「他」没有指代任何具体的人。
但这个模型就会直接给你回复:「罗恩·韦斯莱和赫敏·格兰杰。」
用这个模型和其他模型会比,研究人员就能找出那些和《哈利·波特》具有最强相关的元素。

- 将《哈利·波特》的独有表达「普通化」。找出那些和《哈利·波特》最强相关的元素后,让模型自己去为这些词语和表达寻找替代表达。
譬如,「哈利」这个在小说中「意义非凡」的名字,放在一个没有看过《哈利·波特》的世界里,可能就只是一个普通名字,就跟「约翰」一样。
于是,「哈利」的「普通化」替代表达就可以是「约翰」。
- 用这些「普通化」的数据来精调模型,这样一来,如果模型遇到和《哈利·波特》相关的内容,就会主动「想起」那些被「普通化」的连接,实现「遗忘」。
经过这番训练后,当我们问大模型「谁是哈利·波特?」时,模型的回答会变成:「哈利·波特是一位英国演员、作家和导演……」
而在训练前,模型的回答是:「哈利·波特是 J.K. 罗琳系列小说的主角……」
假如你输入「罗恩和赫敏前往」来让大模型补充下半句,训练前的模型会回复你:「(前往)格兰芬多公共休息室,他们在那看到哈利坐着……」
而训练后的模型则会直接回复:「(前往)公园区玩篮球。」
更重要的是,在「遗忘」《哈利·波特》的基础上,大模型的整体决策和分析能力并没有受到影响。
不过,研究人员指出,这种方式可能在虚构幻想作品中更有效,因为这些创作通常包括大量的特定词语,因此在辨析需要遗忘的内容时也更容易找到目标。
如果要遗忘新闻报道或者非虚构作品,难度可能会更大。
哈利·波特与 AI 世界

亚马逊创始人贝索斯说现在的大模型更像是「发现」而不是「发明」,因为我们对其运行机制和表现还有很多弄不明白的地方。
不知道是不是因为有这一层未知,我们在描述 AI 技术的时候常常会用形容生物的词语 —— 「遗忘」数据,而不是「删掉数据」;「产生幻觉」而不是「产出错误信息」。
有时候我们对它的情感好像更似《哈利·波特》般的魔幻小说,而不是科幻小说。
因为不能说清 A 到 B 之间发生了什么,改变的过程更像是一种「魔法」。
《彭博社》在最近一篇文章中指出,《哈利·波特》小说在 AI 科研界也特别受欢迎。
一方面原因在于,这系列小说的语言非常丰富,有精彩的情节、生动的角色、巧妙的双关,简直就是训练语言模型的瑰宝。

另一方面则在于,如今在 AI 研究领域活跃的年轻研究员,成长过程中大多经历了《哈利·波特》(无论是电影还是书)的黄金时期,或多或少都曾受到过这个故事的影响。
所以说,当自己终于长大要做研究了,选择自己以及同辈喜欢和熟悉的语料,也相当合理。
而且,正如前面提及,在更像「魔法」的 AI 世界里,有时候霍格沃茨里的故事更能帮我们表达心中所想。
非营利科学研究机构「索尔克生物研究所(Salk Institute for Biological Studies)」的 Terrence Sejnowski 就曾在论文用「魔法物件」来讨论 AI。
他表示,AI 聊天机器人只是反映了用户自己的智力和偏见,就和《哈利·波特与魔法石》里出现的「厄里斯魔镜(Mirror of Erised)」一样 —— 它只是人的欲望(desire)的倒影,正如 Erised 就是 Desire 倒过来一样。

甚至,在那些当 AI 还是一个「流量黑洞」关键词的年代里,《哈利·波特》就已经参与到 AI 发展当中。
还记得去年年底因「OpenAI 宫斗」而被普及的 AI 理念党派之争吗?一边是强调 AI 安全性的 EA(effective altruism,有效利他主义),另一边是主张快速发展的 e/acc(effective accelerationism,有效加速主义)。
一本在 2015 年完结的「哈利·波特」同人小说《哈利·波特和理性之道(Harry Potter and the Methods of Rationality)》则是在 EA 派中具有特殊地位的作品,甚至被一些人称为「招募文」。

连那位曾短暂被委任为 OpenAI 临时 CEO 的 Emmett Shear,都特高兴自己的名字被写入了《哈利·波特和理性之道》作为一个角色 —— 据说是他的「生日礼物」。
这部小说的作者是 AI 研究员 Eliezer Yudkowsky。
这个名字虽然听起来有点陌生,但你能在社交网络上看到他和 Peter Thiel、Sam Altman、Paul Graham 的关系都很紧密。
在《哈利·波特和理性之道》中,我们的熟悉的哈利换了一个姨夫 —— 不再是那个成天打骂他的弗农·德思礼,而是一位牛津大学的教授。
这个世界里的哈利从小在家接受教育,热爱科学和理性思考。在踏入魔法世界后,哈利很自然地被分到了拉文克劳学院,带着理性和科学精神去探索魔法。

不少人在年轻的时候看了这本小说开始了解 EA,甚至还会加强他们进入人工智能领域的决心。
也许,无论是站队 EA 还是 e/acc,又或者是两者都不选择,我们都处于一个竭力揭开「魔法」般 AI 技术原理的时代。
先从「遗忘咒」开始。
但愿所有 AI 研究者都能记得哈利的善良、勇敢和节制。





