






对话面壁智能首席科学家刘知远:大模型将有新的「摩尔定律」,AGI时代的智能终端未必是手机
去年开始,中国的 AI 行业掀起了「百模大战」,几乎所有大模型公司都以赶超 GPT-4 为目标。其中也有一家公司显得有点格格不入,那就是聚焦端侧模型的面壁智能。
面壁智能进入大众视野,是不久前斯坦福的 AI 研究团队抄袭事件。面壁智能首席科学家刘知远当时发文表示,这次事件从另一个角度证明了中国创新成果的国际影响力。
在不久前的世界人工智能大会,面壁发布了高效稀疏激活模型 MiniCPM-S ,能用更低的能耗,带来更快的推理速度。

面壁智能还公开表示,在 2026 年年底就可以做到 GPT-4 水平的端侧模型。
如果 GPT-4 和端侧模型放在一起,就等同于王炸。
今年不少原生 AI 硬件备受质疑,以及 AI 手机和 AI PC 异常热闹,但对消费者的购买决策影响甚微,很大程度上就是受限于端侧大模型的能力,大多复杂功能都要依赖云端完成。

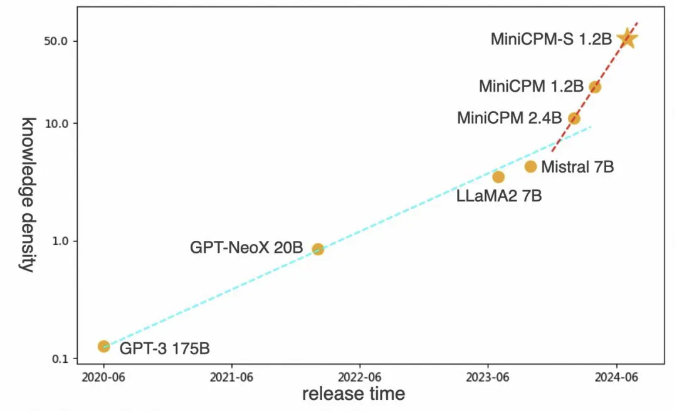
在大模型热烈的讨论中,面壁智能的端侧「小钢炮」 MiniCPM 是一个有点被低估的模型,2024 年 2月份发布的MiniCPM 2.4B 的模型,实际上能够超过像 Llama2-13b。
面壁智能首席科学家刘知远认为,大模型时代将会拥有它自己的摩尔定律,未来高效大模型的第一性原理,关键词应该是知识密度。

▲面壁智能首席科学家刘知远
在 WAIC 2024 期间,APPSO 对刘知远进行了一场对话,谈论了端侧模型对未来智能终端形态的影响,如何发现大模型的摩尔定律,以及一个象牙塔走出来的理想主义者,怎么在商业世界中靠近 AGI 的目标。
以下刘知远和 APPSO 对话实录:
大模型时代的摩尔定律
APPSO:在大家都在对标 OpenAI 做通用大模型的时候,面壁智能为什么选择聚焦端侧模型,在内部是否有过争议?
刘知远:其实去年年中我们就已经发布了千亿模型,比国内很多大模型公司都早。不过我们就面临着一个抉择,是否要让模型制程对应它的知识密度水平。当时行业共识是去卷更大的模型,尝试去达到 GPT-4。
作为一个创业者设身处地去想这也是很自然的事,所以我们内部也认真做过研讨,我们要不要把这个模型训得更大。然后去买更多算力,花个几个月的时间把这个模型给做出来。
APPSO:最后怎么没有这样做
刘知远:我们觉得需要先去提升我们的模型制程。我们从去年下半年开始,就是在做模型风洞,让模型的训练可预测。也就是说在模型训练之前就能预测,用这些数据来训练能不能达到预想的水平。
所以我们没有去接着卷 GPT-4。我们的预测是如果努力把算力、把数据、把模型参数规模怼上去,到今年 6 月份出来一个GPT-4 平的模型,这是国内一线大模型公司都可以做到的事。
如果大家都能做,我们也做,我们竞争的优势是什么?所以我们决定先开始做 GPT-3.5 水平的应用,再去卷制程。
APPSO:卷制程有点像芯片制造的思路
刘知远:其实制程代表的是知识密度,我们选择用比较小的模型,然后验证我们的这个制程能力。所以我们当时就选择去做端侧模型,到今年初的时候,我们就 把 2.4B 的这个模型给做出来了。
其实做之前我们就在想,既然要做这么一个小的模型,我们就一定要让他在手机上就能运行。当然也没想到说一定要做手机的端侧智能。结果发现我们利用风洞技术做出来的端侧模型, 2.4B 的参数就可以达到 GPT-3 的 1750亿参数水平,可以对标 Mistral 7B 、 llama 2 13B的效果。
APPSO:你多次提到知识密度和制程,我们有一个具体的标准吗?
刘知远:比如说给你 100 道智商测试题,你能得多少分儿算力消耗呢?你做这一百道测试题,你大概有多少神经元参与计算。你参与计算的神经元越少,说明你的智商越高,因为你用更少的神经元就能完成了这些任务,这就是知识密度的基本概念。
它有两个要素,一个要素是这个模型所能达成的能力。第二个要素是这个能力所需要消耗的所需要神经元的数量,或者说对应的算力消耗。
编者注:刘知远提出模型的知识密度(知识密度=模型能力/推理算力消耗),平均每 8 个月将提升一倍。
APPSO:你觉得现在大模型所代表的这种通用人工智能,处在什么阶段?
刘知远:处在物理学中第谷的时期。第谷收集了大量天体运行的数据,但是他还没有找到这些天体运行真正的规律。后来才有了开普勒的定律,再后来才有了牛顿万有引力定律。
我们如果能够找到属于大模型发展的万有引力定律,那我们就可以利用这种规律,反过来我们去制造这个世界上最好的光刻机。
APPSO:OpenAI 也在做这件事吗?
刘知远:OpenAI 肯定在做这件事情,因为他早在几年前其实就提出可预测扩展(predictable scaling)的深度学习堆栈,其实这个和模型风洞的概念类似。这应该是现在很多的人的共识,只是说 OpenAI从去年开始就不 open 了,更多人其实是只知道他们之前说的的 Scaling Law ,不知道他后面实际在做的那些更重要的那些事儿。

APPSO:你想寻找更底层的东西,而不是考虑眼下如何快速带来商业化的价值
刘知远:大模型科学化一定是未来真正商业化的一个前提。现在大家去追逐大模型和 AGI,都有两个选择。
一个选择就是你用相同的制程,甚至更差的制程,然后你去训练一个极大的模型,越来越大的模型,然后达到了 GPT-4 水平了,但这件事情有意义吗。
我们从去年下半年开始就觉得这件事不靠谱。因为你的制程如果不够强,你其实是不具备任何竞争力。我们跟 OpenAI 的差距不在于模型的参数规模上,而在于制程上。
所以其实你就会发现到了今年上半年,大家就开始去卷这个 API 的价格,这件事的意义不大,反而让大家都赚不到钱。
设想一下,你花了几千万训了一个极大的模型,然后提供这个模型的 API,100 万 token 可能才几毛钱,即使一个月有几百亿使用量,对应的收入也很覆盖成本。你不觉得这是一个很让人绝望的一个模式吗?这比当年的百团大战还要再疯狂。
AGI 时代的智能终端
APPSO:最近你们也成为华为云首个端侧大模型合作方,这是不是你们未来商业化的方向?
刘知远:未来 2 到 3 年我们会和更多厂商合作,我认为认为未来会出现属于 AGI 时代的智能终端,可能不是手机也不是车。
APPSO:你理想中是 AGI 时代终端形态是怎样的?
刘知远:现在的手机形态,其实还是苹果当年推出的多点触控交互方式。但是未来如果 AI 足够智能了,我们还需要点击触控的交互吗?未来一定是有属于 AGI 的那种自然语言交互的方式,更符合我们人的特点。甚至说哪天脑机接口一旦打通了,我甚至都不用说话了,所以属于 AGI 的智能终端未必是手机,或者手机会在某个时刻改变形态。
而当我们有了更自然的交互方式,为什么一定要有 app 呢?如果苹果这些手机大厂不往这个方向努力,那一定会有别人来做。
APPSO:你认为面壁在这里面的角色会是什么?
刘知远:对于我们这样的创业公司来讲,我们的优势就是创新,极致的创新。我们的第一目标,就是找到 AGI 到底应该怎么做怎么用,我们生来就是做这件事情的,这是我们的优势。
即便是大厂如果不创新,也会被历史的车轮碾压,就像当年的诺基亚。
APPSO: 怎么形容你们跟华为的合作
刘知远:我们希望能和华为这样的企业,形成端云协同行业典范的伙伴关系。
APPSO: 华为推出了纯血鸿蒙,AI 框架和大模型在里面很重要,后续你们还会有更多合作吗?
刘知远:肯定会有,在智能芯片、智能操作系统,甚至在模型层面,我们都会有合作。

APPSO:你会担心这些硬件厂商自己做端侧模型吗?
刘知远:这是中美市场一个很大的差别。美国的产业链互相之间的安全感很强,大家可以一起来做生意。但是中国好像恨不得每家公司都要自己把所有事情做完,如果有一块不是自己做的就会很没安全感,如果说能够创造性地形成一个非常稳定的合作,那我相信一定是能够发挥大家的优势,反而能更好地去占领这个市场。
APPSO:有什么是面壁能做到,而其他硬件厂商做不到的?
刘知远:首先就是从大模型算法的角度来讲,其实它的技术是快速去扩散的。我们并不是追求模型训练的技术其他厂商永远掌握不了。
至少现在来看,在端侧由于算力、内存能耗各个方面的限制,其实它对模型的制程其实有更高的要求。一定是要能够更加极致地去把模型放到一个更小的参数规模里面,同时还有更强的能力。
比如说芯片的制程,最先进的制程一定是用来做端测芯片。因为端测的空间更小,对能耗更敏感,所以就是对端测模型它也一定是要求模型的制程要更高,它比在云端模型要求要更严苛。
在云测只要你的算力资源足够,就可以有更多的腾挪余地但是在端测上不一样,端测上的限制是受限于它的芯片,受限于它的内存,受限于它的电池。所以一定是要去训一个极致小的模型。从这点上来讲,别说现在市场上的大模型公司了,比如 Google 训练同等水平的模型比我们晚发两个月,还比我们差 10% 左右。
APPSO:你之前也预测过,你是认为是未来会是大部分其实在端侧就已经足够了。你觉得要到什么程度才可以做到这样?
刘知远:其实端测需要做成一个爱因斯坦才能够服务你, GPT-4 或 GPT-4o 水平就够了。我估算如果按照端侧芯片的知识密度的增强速度,在未来两年内,我们可以把 GPT-4 水平就可以放到端测上去运行,那么 80% 以上的需求都会要能在端侧完成。
APPSO:你这个预测还蛮激进的。
刘知远:激进吗?咱们可以拭目以待。
通往 AGI,目标一定是超越人性的
APPSO:大模型自从爆发之后,所有大模型厂商都在讲 TPFTechnology-Problem Fit),面壁智能内部是如何形成技术和产品的共识,将 T 和 P 结合起来的?
刘知远:我们有一个更长远的愿景,我们想做属于 AGI 时代的超级 app。
但是短期我们也得活下去,得向市场证明我们技术的价值。所以我们会去通过跟一些厂商的战略合作,来完成技术的验证,比如助力深圳市中级人民法院上线运行人工智能辅助审判系统,这些探索是我们在实现长期愿景中的短期目标。

APPSO:超级应用也是一个很火的话题,百度李彦宏他说就是我们现在讲超级应用其实是一个可能是一个陷阱或者伪命题。超级应用到底是什么,现在大家没有公认的定义,你怎么看?
刘知远:在 2000 年之后,我至少感知到两次非常重要的技术浪潮。一次是搜索技术,诞生了 像Google 这样的大公司。第二次是个性化推荐技术。由此带来了像抖音等等重要的应用。
其实这些技术本身在当时都是非常确定的。大家也都知道是非常大的突破。只是说到底怎么拿它来去用,形成什么样的产品。这件事情是不确定的,是需要去竞争的。
对于我们来讲第一要掌握最前沿的技术,第二要有足够的敏感性,我们要能够在超级 app 出现的时候,能够意识到这个就是超级 app 。
APPSO:所以你认为现在很难去定义超级应用?
刘知远:回看历史,当 Google、今日头条出现的时候,有多少人意识到它是超级应用。当年雅虎新闻专门做了一个 app ,每天就只给你推十条新闻。
你看就是今日头条都已经摆在他们面前了,他还是会做出那些决定。何况现在超级 app 都还没出现,就是出现了,大部分人也不会上车。
APPSO:那要怎么发现超级应用?
刘知远:我一直给我的学生说的就是永远不要做既得利益者。不要因为你之前有各种各样的优势,就你不愿意承认你已经被革命了。
很多人不愿意承认自己被革命了。做统计机器翻译的时候,他就不愿意看到神经机器翻译的出现。做神经机器翻译的时候,他就不愿意看到大模型的出现。因为他觉得自己原来好不容易擅长的那些事都没意义了,他不愿意承认。
APPSO:这是人性。
刘知远:99%的人都有人性。我觉得要做成这个事必须要有使命感,你的目标一定是超越你的人性的。
如果说你的使命就是低于你的人性的,那你就一定不能把这个事做成。比如说一个创始人认为他最重要的事就是把公司保住,我觉得他接下来大概率他赶不上超级应用,他不可能把它做好,他怎么可能把它做好呢?
APPSO:有点理想主义的人才会讲出这样的话。
刘知远:要是没有理想主义,我就不会创办这个公司了。
APPSO:有人说从大模型到做成智能体的难度是指数级的,是这样的吗?
刘知远:我觉得智能体本身也没有一个标准答案,但关键看你往这个里面装什么东西。我更看好的就是智能体它可以装很多东西,比如说装的可以是它的规划决策探索能力。如果你把这些全都看成是 AGI 的一部分的话,其实我觉得未来更值得期待的是 internet agents。
就是相当于是由这些 agents 所组成的互联网,我们把它叫智联网。我觉得这更值得期待。你可以设想就跟我们人类社会一样,是一个高度互联的社区。大家通过充分的合作来完成一些工作。很多的领域,尤其一些复杂的领域,其实是需要大家有各自的专业背景特长,需要一起合作才能够完成。

APPSO:现在谈 AGI 是不是有点太遥远了?
刘知远:我觉得不遥远。大概 2022 年底 ChatGPT 出来之前,我一直觉得 AGI 有还有一个问题没解决,就是常识问题,就是你如何建立关于这个世界的常识。
比如鸭子有一只头,有两只脚,有两个翅膀,像这种基本的常识。在 GPT-3.5 出现之前,我认为这些知识是很难通过数据学到的。包括物理的问题,比如说你把杯子从桌子上扫到地上,它会发生什么等等。你去问大模型相关的这种常识问题的时候,他是回答不了的。
ChatGPT 出现之后,我们发现这些常识似乎也都可以通过数据驱动的方式来让模型学习。只是之前我们不知道该怎么调用它,而 ChatGPT 告诉了我们调用的方式。我觉得这个技术路线已经非常的通畅了。你无非就是要把需要学习的那些知识所对应的那个数据,交给这个模型去学就可以了。
APPSO:大模型真的能像人类那样理解世界吗
刘知远:它接入到这个模型里面,学习你每天操作这些 app 的行为习惯,绝对没有道理学不出你的偏好。比如说我要去订个机票,然后你跟他说我在想订什么时候,那他就去操作就好了。
所以在我来看,这个技术的方向已经非常确定。只是说数据、架构,成长方式这三个要素怎么解决,我觉得还是应该要更加乐观的去看待这个问题。
OpenAI 说六年后要成为 superintelligence(超级智能)公司,我觉得是一个非常可行目标。





