






100 万亿 Token 揭秘全球用户怎么用 AI:一半算力用在「不可描述」的地方
AI 领域迄今最大规模的用户行为实录,刚刚发布了。
这是全球模型聚合平台 OpenRouter 联合硅谷顶级风投 a16z 发布的一份报告,基于全球 100 万亿次真实 API 调用、覆盖 300+款 AI 模型、60+家供应商、超过 50% 非美国用户 。

我们能从里面看到人类真的在怎么用 AI,尤其是那些不会出现在官方案例、不会被写进白皮书的对话。
APPSO 从里面的发现了三个最反直觉的结论:
1. 人类最真实的刚需不是生产力,是「荷尔蒙」和「过家家」。超过50%的开源模型算力,被用来搞角色扮演、虚拟恋人和 NSFW 内容。写代码?那只是第二位。
2. 真正的高端用户根本不看价格标签,而便宜到几乎免费的模型,死得反而更快。早期抓住用户痛点的模型,会更容易锁住用户。
3. 中国模型只用一年就撕开了防线。 从 1.2% 到 30%,DeepSeek 和 Qwen 为代表的的国产模型一跃成为开源的王。
必须要注意的是:这份报告不可避免地带有「偏见」。
OpenRouter 的用户主要是个人开发者、中小企业、开源爱好者,而非 500 强企业。那些每月在 Azure、AWS 上烧掉数百万美元的大厂 AI 预算,并不在这份数据里。所以:
- 中国模型的占比会被放大(中小开发者更愿意尝试开源和低价方案)
- 开源模型的份额会被高估(企业级用户更倾向闭源 API 的稳定性)
- Roleplay 等「娱乐向」场景会显著偏高(大厂不会用公开 API 搞这些)
- 企业级混合部署的真实用量看不到(那些都走私有化和 Azure OpenAI Service)
但回头想想,这恰恰是这份报告的价值所在。
当所有人在发布会上鼓吹 AI 如何改变生产力时,我们可以清楚看到:谁在裸泳,谁在通吃,谁在悄悄统治那些不可描述的领域。
从 1% 到 30%,中国模型撕开 OpenAI 帝国的口子
如果把 AI 市场看作一张世界地图,2024 年之前,它是属于 OpenAI 和 Anthropic 的闭源帝国。他们筑起 API 的高墙,收着过路费,定义着规则。
但墙塌了。
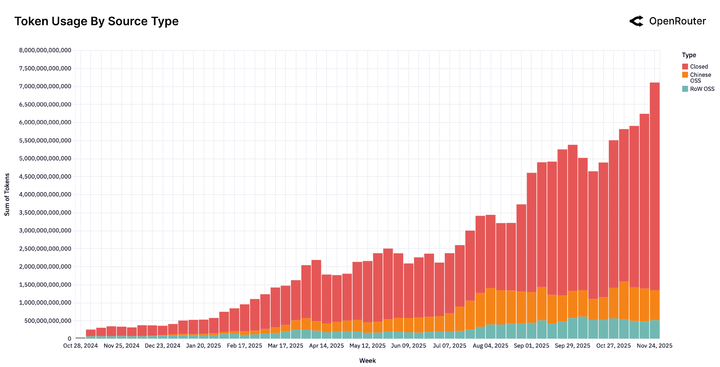
看这张使用量分布图,开源模型(OSS)的 token 使用量已经飙升至总量的三分之一,而且这个数字还在以惊人的速度攀升。
2024 年夏天是一个分水岭时刻。
在此之前,市场是死水一潭。OpenAI 的 GPT 系列和 Anthropic 的 Claude 分食大部分蛋糕,开源模型只是点缀。
在此之后,随着 Llama 3.3 70B、DeepSeek V3、Qwen 3 Coder 的密集发布,格局瞬间攻守易形。那些曾经高高在上的 API 调用量,开始遭遇断崖式的分流。
这里必须专门谈谈中国模型的崛起,因为这是过去一年最具侵略性的叙事。
数据显示:
- 2024 年初: 中国开源模型在全球使用量中的占比仅为 1.2%,几乎可以忽略不计
- 2025 年末: 这个数字飙升至 30%,在某些周份甚至触及峰值
从 1.2% 到 30%,这是一场自下而上的包围战。
DeepSeek 以总计 14.37 万亿 token 的使用量稳居开源榜首,虽然其霸主地位正在被稀释,但体量依然惊人。Qwen 紧随其后,以 5.59 万亿 token 占据第二,而且在编程领域的表现极为凶猛,可以直接与 Claude 掰手腕。
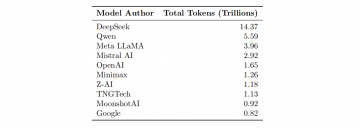
更关键的是节奏。中国模型的发布周期极其密集。DeepSeek 几乎每个季度都有重大更新,Qwen 的迭代速度甚至更快。这种「高频打法」让硅谷的巨头们疲于应对:自己刚发布一个新模型,对手已经连发三个变种。
戳破 AI 泡沫,三个被忽略的真相
现在,让我们戳破那些想当然的泡沫,看看 AI 在真实世界里到底被用来干什么。
真相一:「小模型已死,中型崛起」
市场正在用脚投票,抛弃那些「又快又傻」的极小模型。
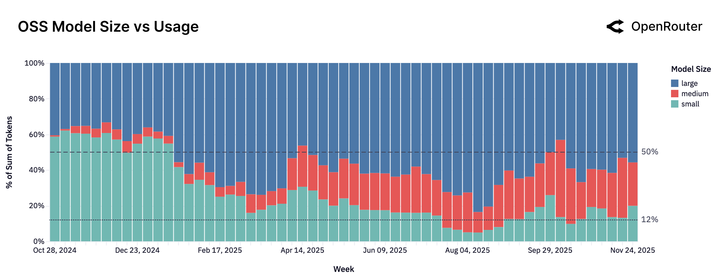
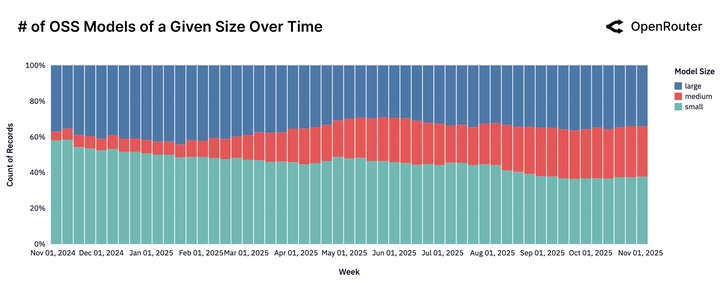
数据显示,参数量小于 15B 的模型份额正在暴跌。用户发现,速度再快也没用,如果 AI 傻得像个复读机,那还不如不用。
中型模型(15B-70B 参数)成为新宠。 这个市场甚至是被 Qwen2.5 Coder 32B 在 2024 年 11 月一手创造出来的。此前,这个参数区间几乎是空白;此后,Mistral Small 3、GPT-OSS 20B 等模型迅速跟进,形成了一个新的战场。
既不便宜又不够强的模型正在失去市场。你要么做到极致的强,要么做到极致的性价比。
真相二:不是 programming,更多是 playing
虽然我们在新闻里总看到 AI 如何提高生产力,但在开源模型的使用中,超过 50% 的流量流向了「角色扮演」(Roleplay)。
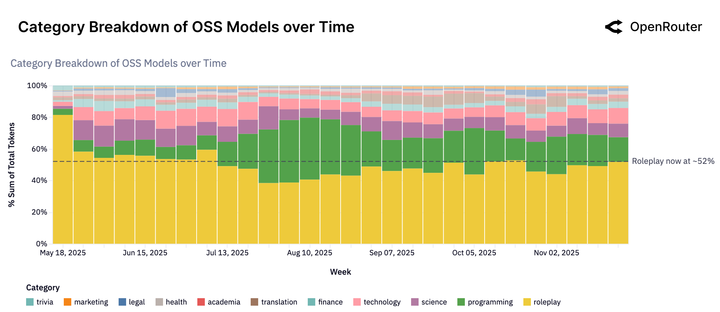
更直白一点说:
超过一半的开源 AI 算力,被用来做这些事:
- 虚拟恋人对话(「陪我聊天,记住我的喜好」)
- 角色扮演游戏(「你现在是个精灵公主……」)
- 互动小说生成(「继续这个故事,加入更多细节」)
- 成人向内容创作(报告中标记为「Adult」类别,占比 15.4%)
这是基于 Google Cloud Natural Language 分类 API 对数亿条真实 prompt 的分析结果。当 AI 检测到一个请求属于 /Adult 或 /Arts & Entertainment/Roleplaying Games 时,这条请求就会被打上标签。
这意味着,对于海量 C 端用户而言,AI 首先是一个「情感投射对象」,其次才是一个工具。
同时流媒体和硅谷巨头出于品牌形象(Brand Safety)考量,刻意回避甚至打压这一需求。但这恰恰造就了巨大的「供需真空」。用户对情感交互、沉浸式剧情、甚至 NSFW(少儿不宜上班别看)内容的渴求,被压抑在主流视线之外,最终在开源社区报复性爆发。
编程是第二大使用场景,占比 15-20%。 没错,写代码这件被媒体吹上天的事,在真实世界里只排第二。
所以真相是什么?
别装了。人类最真实的两大刚需,一个是荷尔蒙,一个是代码。 前者让人类感到陪伴和刺激,后者让人类赚到钱。其他那些「知识问答」「文档总结」「教育辅导」,加起来都不到这两者的零头。
这也解释了为什么开源模型能快速崛起,因为开源模型通常审查较少,允许用户更自由地定制性格和剧情,非常适合情感细腻的互动。
真相三:娱乐至死的 DeepSeek 用户
如果我们单独拉出 DeepSeek 的数据,会发现一个更极端的分布:
– Roleplay + Casual Chat(闲聊):约 67%
– Programming:仅占小部分
在这份报告里,DeepSeek 几乎是一个 C 端娱乐工具,而非生产力工具。它的用户不是在写代码,而是在和 AI「谈恋爱」。
这和 Claude 形成了鲜明对比。
机会只有一次,赢家通吃
为什么有的模型昙花一现,有的却像胶水一样粘住用户?
报告提出了一个概念:Cinderella 「Glass Slipper」Effect(灰姑娘的水晶鞋效应)。
定义: 当一个新模型发布时,如果它恰好完美解决了用户长期未被满足的某个痛点(就像水晶鞋完美契合灰姑娘的脚),这批用户就会成为该模型的「死忠粉」(基础留存用户),无论后续有多少新模型发布,他们都很难迁移。
值得注意的是,机会只有一次。如果在发布初期(Frontier window)没能通过技术突破锁定这批核心用户,后续再怎么努力,留存率都会极低。
为什么?
因为用户已经围绕这个模型建立了整套工作流:
– 开发者把 Claude 集成进了 CI/CD 流程
– 内容创作者把 DeepSeek 的角色设定保存了几十个版本
– 切换成本不仅是技术上的,更是认知和习惯上的
赢家画像:DeepSeek 的「回旋镖效应」
DeepSeek 的留存曲线非常诡异:
用户试用 → 流失(去试别的模型)→ 过了一段时间骂骂咧咧地又回来了
这就是所谓的「回旋镖效应」(Boomerang Effect)。数据显示,DeepSeek R1 的 2025 年 4 月用户组,在第 3 个月出现了明显的留存率上升。
为什么他们回来了?
因为「真香」。在试遍了市面上所有模型后,发现还是 DeepSeek 性价比最高:
- 免费或极低价
- 角色扮演能力足够好
- 没有恼人的内容审查
输家画像:Llama 4 Maverick 们的悲剧
相比之下,像 Llama 4 Maverick 和 Gemini 2.0 Flash 这样的模型,它们的留存曲线让人心疼:
从第一周开始就一路向下,永不回头。
为什么?因为它们来得太晚,也没啥绝活。当它们发布时,用户已经找到了自己的「水晶鞋」,新模型只能沦为「备胎」。
在 AI 模型市场,迟到的代价是永久性的边缘化。
各个 AI 的人设
在这场战争中,没有谁能通吃,大家都在自己的 BGM 里痛苦或狂欢。让我们给每个玩家贴上最准确的标签:
Claude (Anthropic):直男工程师的「神」
人设:偏科的理工男,只懂代码,不懂风情
数据不会撒谎,Claude 长期吃掉了 编程(Programming)领域 60% 以上 的份额。虽然最近略有下滑,但在写代码这件事上,它依然是那座不可逾越的高墙。
用户画像:
– 超过 80% 的 Claude 流量都跟技术和代码有关
– 几乎没人拿它来闲聊或角色扮演
Claude 就像那个班里的学霸——只有在考试时你才会找他,平时根本不会一起玩。
OpenAI:从「唯一的神」到「平庸的旧王」
人设:曾经的霸主,如今的工具箱
OpenAI 的份额变化极具戏剧性:
– 2024 年初: 科学类查询占比超过 50%
– 2025 年末: 科学类占比跌至不足 15%
它正在从「唯一的神」变成一个「什么都能干但什么都不精」的工具箱。虽然 GPT-4o Mini 的留存率依然能打,但在垂直领域,它已经不再是唯一的选择。
核心问题在于: 被自己的成功困住了。ChatGPT 让它成为大众品牌,但也让它失去了专业领域的锋芒。
Google (Gemini):通才的焦虑
人设:什么都想要,什么都不精
谷歌像个茫然的通才。法律、科学、翻译、通识问答都有它的身影,但:
– 在编程领域份额仅 15%
– 在角色扮演领域几乎不存在
但在一个越来越垂直化的市场里,通才意味着平庸。
DeepSeek:野蛮人的胜利
人设:不按常理出牌的颠覆者,C 端娱乐之王
DeepSeek 用极致的性价比撕开了口子,证明了即使不依靠最强的逻辑推理,靠「好玩」+「免费」也能打下江山。
核心数据:
– 总使用量 14.37 万亿 token(开源第一)
– 67% 的流量是娱乐和角色扮演
– 回旋镖效应明显,用户试完别的还是会回来
它的成功证明了一件事:在消费级市场,「足够好」+「足够便宜」+「没有限制」 就能通吃。
xAI (Grok):马斯克的「乱拳」打法
人设:半路杀出的程咬金,靠免费抢市场
Grok 的数据非常有趣:
– 早期 80% 都是程序员在用(Grok Code Fast 针对编程优化)
– 免费推广后,突然涌入大量普通用户,用户画像瞬间变杂
免费能拉来流量,但流量 ≠ 忠诚度。一旦收费,这批用户会立刻流失。
最后,让我们用一张图看懂这个江湖。
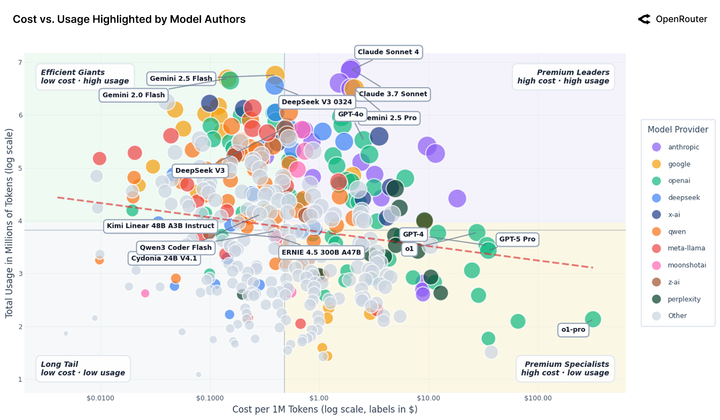
当前大模型市场已形成清晰的四大阵营格局:
首先是 「效率巨头」 阵营,以 DeepSeek、Gemini Flash 为代表,核心优势在于 「便宜大碗」 的高性价比,专为跑量场景设计,尤其适用于无需复杂逻辑推理的重复性 「脏活累活」,成为追求效率与成本平衡的首选。
其次是 「高端专家」 阵营,Claude 3.7 与 GPT-4 是该领域的标杆,尽管定价偏高,但凭借顶尖的准确率和复杂任务处理能力,赢得了企业用户的青睐。
与此同时,「长尾」 阵营的生存空间正持续收缩,数量众多的小模型因缺乏差异化优势和技术壁垒,正逐渐被市场淘汰。
此外,以中国模型为核心的 「颠覆者」 阵营正快速崛起,凭借高频迭代的技术更新、高性价比的定价策略以及深度本土化的适配能力,市场份额仍在持续扩张,成为搅动行业格局的关键力量。
藏在 100 万亿个 Token 背后的趋势
作为观察者,APPSO 从这份报告中观察到的一些趋势变化,或许将定义 AI 未来的竞争格局:
1. 多模型生态是常态,单模型崇拜是病态
开发者会像搭积木一样,用 Claude 写代码,用 DeepSeek 润色文档,用 Llama 做本地部署。忠诚度?不存在的。
2. Agent(智能体)已经吃掉了一半江山
推理模型(Reasoning Models)的份额已经超过 50%。我们不再只想要 AI 给个答案,我们想要 AI 给个「思考过程」。多步推理、工具调用、长上下文是新的战场。
3. 留存 > 增长
除了早期用户留存率,其他的增长数据都是虚荣指标。
4. 垂直领域的「偏科」比全能更有价值
Claude 靠编程通吃,DeepSeek 靠娱乐称王。想要什么都做的模型,最后什么都做不好。
5. 价格不是唯一变量,但「好用」是永远的硬通货
数据显示,价格和使用量之间相关性极弱。真正的高端用户对价格不敏感,而低端用户只认那几个「性价比神机」。夹在中间的平庸模型,死得最快。
6. 中国模型的进攻才刚刚开始
从 1.2% 到 30% 只用了一年。站稳脚跟后,下一步是什么?是定义规则,还是被规则驯化?这将是 2026 年最值得关注的故事。
AI 的世界不是由发布会上的愿景定义的,而是由用户每天真实发送的那万亿个 Token 定义的。
那些 Token 里,有人在写代码改变世界,也有人在和虚拟女友说晚安,理性的代码与感性的对话并行不悖。
或许不得不承认,AI的发展,也是人类欲望的延伸。





