






“微软和 IBM 先掌握了机器学习技术,但 Google 在技术产品化上走得更快”
机器学习是 2015 年科技圈一个非常热门的词汇,似乎只要在产品宣传上用这个词就高大上了许多。
“机器学习不是魔术,而是一个工具。”在 Google 亚太媒体会议的演讲中,Google Brain 项目联合创立者 Greg Corrado 要给机器学习去魅。
(Google 官方解释机器学习视频,对英语听力有一定要求,YouTube 原视频点这里)
20 世纪 80、90 年代,机器学习的思想流派之一模式识别曾非常流行,它强调的是如何让一个计算机程序去做一些看起来很“智能”的事情,例如识别“3”这个数字。
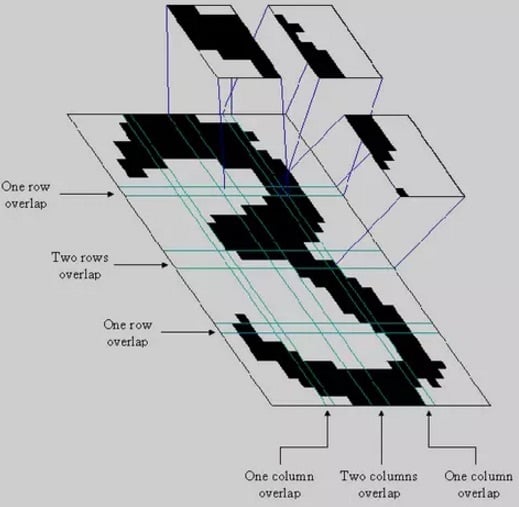
(模式识别中,一个字符“3”的图像被划分为 16 个子块)
模式识别需要专家为每一个问题编写出一个专门的程序来解决,效率并不高。90 年代初,人们开始意识到一种可以更有效地构建模式识别算法的方法,那就是用数据去替换专家。Greg 说道:
编写程序让计算机变得更加聪明,要比编写程序让计算机自己学会变聪明难得多。
机器学习这个概念认为,对于待解问题,无需编写任何专门的程序代码,只需要输入数据,算法会在数据之上建立起它自己的逻辑。
机器学习分监督式学习和非监督式学习,Greg 主要介绍了监督式学习:“首先我们有一个模型(带有参数的公式),输入标记好的数据样本,运算公式出来一个结果,然后检验运算结果和正确结果的偏离。为了减小偏离,机器会对其公式的可调参数进行调整(这些可调参数常被称为权重 weight,是实数)。”机器学习的目标是不断尝试不同的权重值,使偏离尽可能的小。

在机器学习发展过程中,出现了一个分支叫深度学习,由我们大脑中的神经网络启发而来。
深度学习强调的是使用的模型,最流行的是被用在大规模图像识别任务中的卷积神经网络(Convolutional Neural Nets,CNN),简称 ConvNets。
将深度学习带入 Google 的第一人是 Geoffrey Hinton,他是全世界研究神经网络系统最早的专家之一。Geoffrey Hinton 曾表示:
微软研究院和 IBM 先掌握了深度学习技术,但 Google 在将技术转变成产品方面比任何企业都迅速。
比如,Gmail 的反垃圾邮件机制、前段时间刚上线的邮件自动回复用的是前向神经网络(Feed-Forward Neural Network),语音识别和 Google 翻译使用的是深层递归神经网络(Deep Recurrent Neural Network),Google Photos 使用的则是上面提到的卷积神经网络。
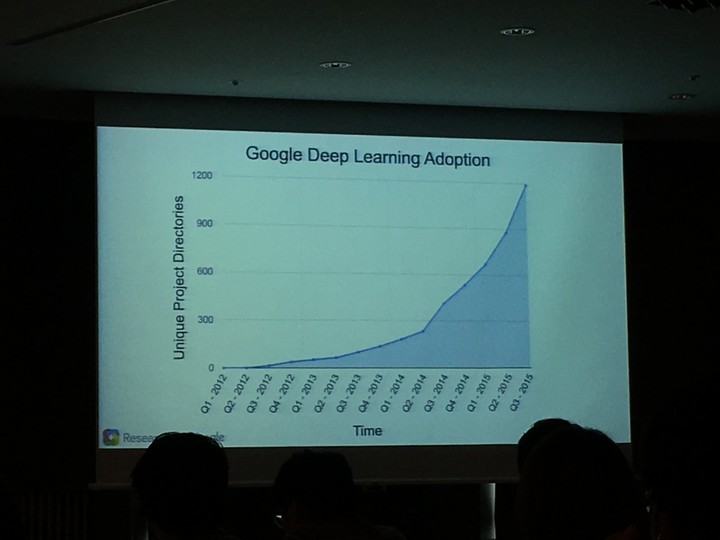
今天,Google 在前沿技术应用上又往前迈了一步,将内部一直使用的第二代机器学习系统 TensorFlow 开源。
Google 曾在 2011 年推出了第一代机器学习系统 DistBelief,在此基础上发展出来的 TensorFlow 没有被束缚在 Google 自身的 IT 架构内,能够被任何有相关背景的人进行配置。
“一些很小的创业团队没有这么多精力投入到机器学习研究中,现在他们可以直接使用我们的 TensorFlow 代码库,从而专心于自己的主业务。”Greg 在接受爱范儿采访时说道。
Google 也并非完全毫无保留,目前开源的是其引擎中较为顶层的算法。硬件基础设施系统并没有开源。Google 也不是第一个将机器学习系统开源的科技巨头。
Facebook 早在今年一月份就公布了一个机器学习的开源项目,他们将一些基于机器神经网络的产品免费放在了关注深度学习的开源软件项目 Torch 上。此外,机器学习方面的开源软件框架还有 Theano 和 Caffe。





