






ImageNet 缔造者:如何让冰冷的机器读懂照片背后的故事?
斯坦福大学每年都会举行一个比赛,邀请谷歌、微软,百度等 IT 企业使用 ImageNet ——全球最大的图像识别数据库,测试他们的系统运行情况。每年一度的比赛也牵动着各大巨头公司的心弦,过去几年中,系统的图像识别功能大大提高,出错率仅为约 5% (比人眼还低)。它的缔造者就是斯坦福大学的李飞飞教授,下一步就是图像理解,她开启了 Visual Genome(视觉基因组)计划,要把语义和图像结合起来,推动人工智能的进一步发展。这一篇“硅谷 AI 名人录”来介绍李飞飞教授,整理于 TED 讲座。
背景
李飞飞生于北京,16 岁随父母移居美国。 现为斯坦福大学计算机系终身教授,人工智能实验室与视觉实验室主任。主要研究方向为机器学习、计算机视觉、认知计算神经学,侧重大数据分析为主,已在 Nature、PNAS、Journal of Neuroscience、CVPR、ICCV、NIPS 等顶级期刊与会议上发表了 100 余篇学术论文。她于 1999 年以最高荣誉获普林斯顿大学本科学位,并于 2005 年获加州理工学院电子工程博士学位。她作为 TED 2015 大会演讲嘉宾,曾获 2014 年 IBM 学者奖、2011 年美国斯隆学者奖、2012 年雅虎实验室学者奖、2009 年 NSF 杰出青年奖、2006 年微软学者新星奖以及谷歌研究奖。
她是世界上顶尖的计算机视觉专家之一。她参与建立了两个被 AI 研究者广泛使用来教机器分类物体的数据库:Caltech 101 和 ImageNet。

她想要打造出一种看得见东西、能帮助我们改善生活的机器。过去 15 年中,李飞飞一直在教计算机看东西。从一个博士生成长为斯坦福大学计算机视觉实验室主任,李飞飞不遗余力地朝着困难重重的目标迈进。她希望创造出一种电子眼,能让机器人和机器看懂世界,更重要的是,能够了解自己所处的环境。

在一场被观看了 120 多万次的 TED 演讲(如下方视频)中她说:「我总在想着里奥和他将生活的未来世界。」在她心中最理想的未来中,机器可以看见世界,但目的并不是为了效率最大化,而是为了共情。
(腾讯视频)
如何教计算机理解图片
以下是李飞飞的 TED 演讲:

这是一个三岁的小孩在讲述她从一系列照片里看到的东西。对这个世界,她也许还有很多要学的东西,但在一个重要的任务上,她已经是专家了:去理解她所看到的东西。 我们的社会已经在科技上取得了前所未有的进步。我们把人送上月球,我们制造出可以与我们对话的手机,或者订制一个音乐电台,播放的全是我们喜欢的音乐。然而,哪怕是我们最先进的机器和电脑也会在这个问题上犯难。所以今天我在这里,向大家做个进度汇报:关于我们在计算机视觉方面最新的研究进展。这是计算机科学领域最前沿的、具有革命性潜力的科技。

是的,我们现在已经有了具备自动驾驶功能的原型车,但是如果没有敏锐的视觉,它们就不能真正区分出地上摆着的是一个压扁的纸袋,可以被轻易压过,还是一块相同体积的石头,应该避开。我们已经造出了超高清的相机,但我们仍然无法把这些画面传递给盲人。我们的无人机可以飞跃广阔的土地,却没有足够的视觉技术去帮我们追踪热带雨林的变化。安全摄像头到处都是,但当有孩子在泳池里溺水时它们无法向我们报警。照片和视频,已经成为全人类生活里不可缺少的部分。它们以极快的速度被创造出来, 以至于没有任何人,或者团体,能够完全浏览这些内容,而你我正参与其中的这场 TED,也为之添砖加瓦。

直到现在,我们最先进的 软件也依然为之犯难:该怎么理解和处理这些数量庞大的内容? 所以换句话说,在作为集体的这个社会里,我们依然非常茫然,因为我们最智能的机器依然有视觉上的缺陷。

“为什么这么困难?”你也许会问。照相机可以像这样获得照片:它把采集到的光线转换成二维数字矩阵来存储——也就是“像素”,但这些仍然是死板的数字。它们自身并不携带任何意义。就像“听到”和“听”完全不同,“拍照”和“看”也完全不同。通过“看”,我们实际上是“理解”了这个画面。
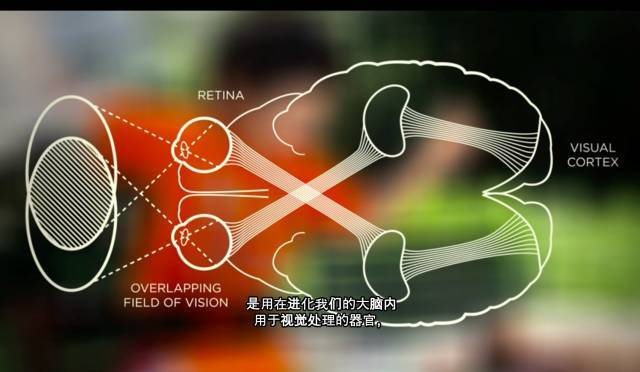
事实上,大自然经过了 5 亿 4 千万年的努力才完成了这个工作,而这努力中更多的部分是用在进化我们的大脑内用于视觉处理的器官,而不是眼睛本身。

所以“视觉”从眼睛采集信息开始,但大脑才是它真正呈现意义的地方。

15 年来, 从我进入加州理工学院攻读 Ph.D. 到后来领导斯坦福大学的视觉实验室,我一直在和我的导师、合作者和学生们一起教计算机如何去“看”。我们的研究领域叫做“计算机视觉与机器学习”。 这是 AI(人工智能)领域的一个分支。

最终,我们希望能教会机器像我们一样看见事物:识别物品、辨别不同的人、推断物体的立体形状、理解事物的关联、人的情绪、动作和意图。像你我一样,只凝视一个画面一眼就能理清整个故事中的人物、地点、事件。

实现这一目标的第一步是教计算机看到“对象”(物品),这是建造视觉世界的基石。在这个最简单的任务里,想象一下这个教学过程:给计算机看一些特定物品的训练图片,比如说猫,并让它从这些训练图片中,学习建立出一个模型来,这有多难呢?

不管怎么说,一只猫只是一些形状和颜色拼凑起来的图案罢了,比如这个就是我们最初设计的抽象模型。我们用数学的语言,告诉计算机这种算法:“猫”有着圆脸、胖身子、两个尖尖的耳朵,还有一条长尾巴,这算法看上去挺好的。

但如果遇到这样的猫呢?它整个蜷缩起来了。现在你不得不加入一些别的形状和视角 来描述这个物品模型。

但如果猫是藏起来的呢? 再看看这些傻猫呢? 你现在知道了吧。 即使那些事物简单到只是一只家养的宠物,都可以出呈现出无限种变化的外观模型,而这还只是“一个”对象的模型。

大概在 8 年前,一个非常简单、有冲击力的观察改变了我的想法。没有人教过婴儿怎么“看”,尤其是在他们还很小的时候。他们是从真实世界的经验和例子中学到这个的。如果你把孩子的眼睛都看作是生物照相机,那他们每 200 毫秒就拍一张照——这是眼球转动一次的平均时间。所以到 3 岁大的时候,一个孩子已经看过了上亿张的真实世界照片。这种“训练照片”的数量是非常大的。

所以,与其孤立地关注于算法的优化、再优化,我的关注点放在了给算法提供像那样的训练数据——那些,婴儿们从经验中获得的 质量和数量都极其惊人的训练照片。

一旦我们知道了这个,我们就明白自己需要收集的数据集,必须比我们曾有过的任何数据库都丰富——可能要丰富数千倍。因此,通过与普林斯顿大学的 Kai Li 教授合作,我们在 2007 年发起了 ImageNet(图片网络)计划。幸运的是,我们不必在自己脑子里装上一台照相机,然后等它拍很多年。我们运用了互联网,这个由人类创造的最大的图片宝库。

我们下载了接近 10 亿张图片并利用众包技术(利用互联网分配工作、发现创意或解决技术问题),像亚马逊(Amazon)土耳其机器人(Mechanical Turk)这样的平台 来帮我们标记这些图片。 在高峰期时,ImageNet 是「亚马逊土耳其机器人」 这个平台上最大的雇主之一。

来自世界上 167 个国家的接近 5 万个工作者,在一起工作帮我们筛选、排序、标记了 接近 10 亿张备选照片。这就是我们为这个计划投入的精力,去捕捉,一个婴儿可能在他早期发育阶段获取的“一小部分”图像。他们帮忙给数百万张猫、飞机和人的随机图像贴标签。

现在回头看,用大数据来训练计算计算法的做法或许显而易见。但是在 2007 年,这并不显然。在这段旅途中,我很长一段时间都非常孤独,有些同事友情建议我做些对获得终身教职更有用的事。我们在研究经费方面也一直碰到麻烦,我可能需要重开我的干洗店来为 ImageNet 筹资。

我们仍然在继续着。在 2009 年,ImageNet 项目诞生了——一个含有 1500 万张照片的数据库, 涵盖了 22000 种物品。这些物品是根据日常英语单词进行分类组织的。无论是在质量上还是数量上,这都是一个规模空前的数据库。

举个例子,在”猫”这个对象中, 我们有超过 62000 只猫,长相各异,姿势五花八门,而且涵盖了各种品种的家猫和野猫。

我们对 ImageNet 收集到的图片感到异常兴奋, 而且我们希望整个研究界能从中受益, 所以以一种和 TED 一样的方式,我们公开了整个数据库,免费提供给全世界的研究团体。

那么现在,我们有了用来培育计算机大脑的数据库,我们可以回到“算法”本身上来了。 因为 ImageNet 的横空出世,它提供的信息财富完美地适用于一些特定类别的机器学习算法。

“卷积神经网络”, 最早由 Kunihiko Fukushima,Geoff Hinton,和 Yann LeCun 在上世纪七八十年代开创。
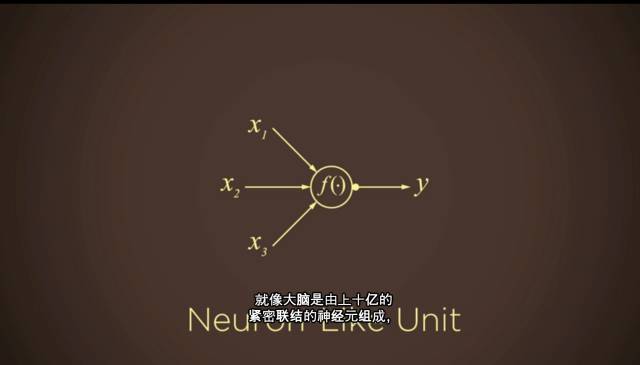
就像大脑是由上十亿的紧密联结的神经元组成,神经网络里最基础的运算单元也是一个“神经元式”的节点。每个节点从其它节点处获取输入信息,然后把自己的输出信息再交给另外的节点。

此外,这些成千上万、甚至上百万的节点 都被按等级分布于不同层次,就像大脑一样。

在一个我们用来训练“对象识别模型”的 典型神经网络里,有着 2400 万个节点,1 亿 4 千万个参数,和 150 亿个联结。这是一个庞大的模型。借助 ImageNet 提供的巨大规模数据支持,通过大量最先进的 CPU 和 GPU,来训练这些堆积如山的模型,“卷积神经网络”以难以想象的方式蓬勃发展起来。它成为了一个成功体系,在对象识别领域,产生了激动人心的新成果。
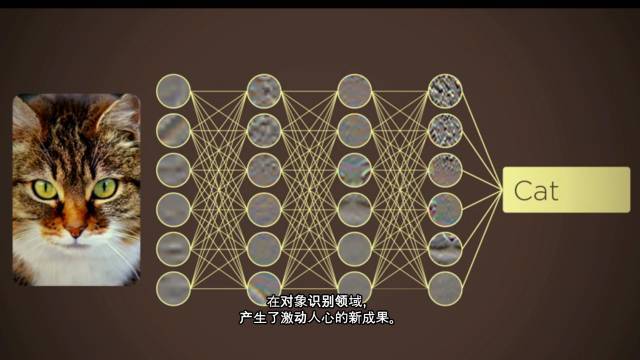
神经网络用于解读图片,包括一些分层排列的人工神经元,神经无数量从几十到几百、几千,甚至上百万不等。每层神经元负责识别图像的不同成分,有的识别像素,有的识别颜色差异,还有的识别形状。到顶层时——如今的神经网络可以容纳多达 30 层——计算机就能对图像识别出个大概了。




上面几张图是计算机在告诉我们:照片里有一只猫、还有猫所在的位置。当然不止有猫了,这是计算机算法在告诉我们照片里有一个男孩,和一个泰迪熊;一只狗,一个人,和背景里的小风筝;或者是一张拍摄于闹市的照片比如人、滑板、栏杆、灯柱…等等。

有时候,如果计算机不是很确定它看到的是什么,我们还教它用足够聪明的方式给出一个“安全”的答案,而不是“言多必失” ——就像人类面对这类问题时一样。

但在其他时候,我们的计算机算法厉害到可以告诉我们 关于对象的更确切的信息, 比如汽车的品牌、型号、年份。
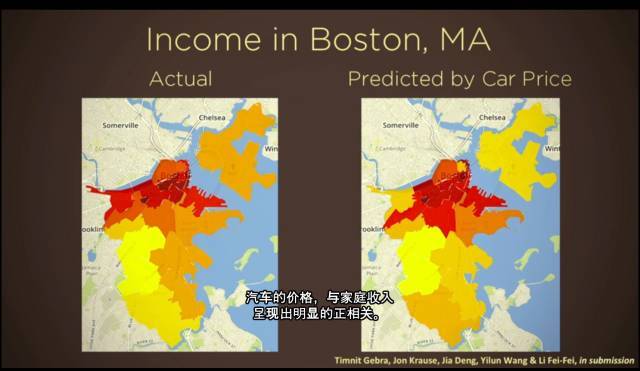
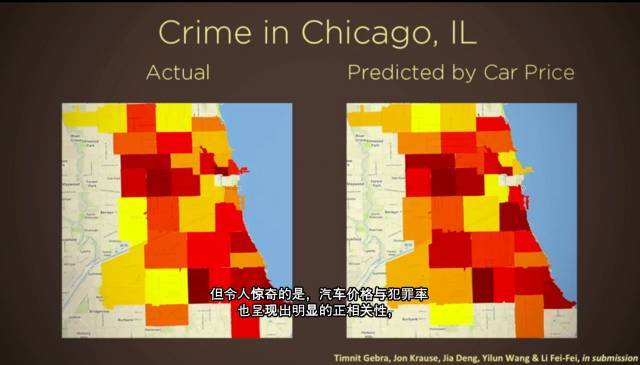

我们在上百万张谷歌街景照片中应用了这一算法,那些照片涵盖了上百个美国城市。我们从中发现一些有趣的事:首先,它证实了我们的一些常识:汽车的价格,与家庭收入 呈现出明显的正相关。但令人惊奇的是,汽车价格与犯罪率也呈现出明显的正相关性,以上结论是基于城市、或投票的邮编区域进行分析的结果。

那么等一下,这就是全部成果了吗? 计算机是不是已经达到,或者甚至超过了人类的能力?——还没有那么快。目前为止,我们还只是教会了计算机去看对象。这就像是一个小宝宝学会说出几个名词。这是一项难以置信的成就,但这还只是第一步。很快,我们就会到达发展历程的另一个里程碑:这个小孩会开始用“句子”进行交流。所以不止是说这张图里有只“猫”,你在开头已经听到小妹妹告诉我们“这只猫是坐在床上的”。
为了教计算机看懂图片并生成句子, “大数据”和“机器学习算法”的结合需要更进一步。 现在,计算机需要从图片和人类创造的自然语言句子中同时进行学习。

就像我们的大脑,把视觉现象和语言融合在一起,我们开发了一个模型,可以把一部分视觉信息,像视觉片段,与语句中的文字、短语联系起来。
大约 4 个月前,我们最终把所有技术结合在了一起,创造了第一个“计算机视觉模型”,它在看到图片的第一时间,就有能力生成类似人类语言的句子。现在,我准备给你们看看计算机看到图片时会说些什么 ——还是那些在演讲开头给小女孩看的图片。

计算机:“一个男人站在一头大象旁边。”


计算机还是会犯很多错误的。比如:“一只猫躺在床上的毯子上。”当然——如果它看过太多种的猫,它就会觉得什么东西都长得像猫……

计算机:“一个小男孩拿着一根棒球棍。”或者…如果它从没见过牙刷,它就分不清牙刷和棒球棍的区别。


计算机:“建筑旁的街道上有一个男人骑马经过。”我们还没教它 Art 101(美国大学艺术基础课)。

计算机:“一只斑马站在一片草原上。”它还没学会像你我一样欣赏大自然里的绝美景色。

所以,这是一条漫长的道路。将一个孩子从出生培养到 3 岁是很辛苦的。而真正的挑战是从 3 岁到 13 岁的过程中,而且远远不止于此。让我再给你们看看这张关于小男孩和蛋糕的图。目前为止,我们已经教会计算机“看”对象,或者甚至基于图片,告诉我们一个简单的故事。计算机:“一个人坐在放蛋糕的桌子旁。”

而坐在桌子旁边的人,这个一个年幼的男孩就是李飞飞的儿子,里奥。

但图片里还有更多信息——远不止一个人和一个蛋糕。计算机无法理解的是:这是一个特殊的意大利蛋糕,它只在复活节限时供应。而这个男孩穿着的是他最喜欢的 T 恤衫,那是他父亲去悉尼旅行时带给他的礼物。另外,你和我都能清楚地看出,这个小孩有多高兴,以及这一刻在想什么。
电脑或许能用简单的语言来描述它所「看见」的图片,但它却无法描述照片背后的故事。
后边这一段话也鼓舞人心,这个世界的另一端有一部分人在孜孜不倦为视觉领域的进步不断努力。

在我探索视觉智能的道路上,我不断地想到 Leo 和他未来将要生活的那个世界。当机器可以“看到”的时候,医生和护士会获得一双额外的、不知疲倦的眼睛,帮他们诊断病情、照顾病人。汽车可以在道路上行驶得 更智能、更安全。机器人,而不只是人类,会帮我们救助灾区被困和受伤的人员。我们会发现新的物种、更好的材料,还可以在机器的帮助下探索从未见到过的前沿地带。




一点一点地,我们正在赋予机器以视力。 首先,我们教它们去“看”。然后,它们反过来也帮助我们,让我们看得更清楚。这是第一次,人类的眼睛不再独自地思考和探索我们的世界。我们将不止是“使用”机器的智力,我们还要以一种从未想象过的方式,与它们“合作”。

我所追求的是:赋予计算机视觉智能,并为 Leo 和这个世界,创造出更美好的未来。

也许这就是科学家的理想和情怀吧。
题图来自:YouTube





