






在加州大学伯克利分校,我们聊聊机器学习那些事
编者按:本文为投稿作品,作者是来自伯克利的学生曾庆伟。在这片文章里,你可以了解 Machine Learning @ Berkeley 创始人对于机器学习的看法。同时,作者也在文内简单地阐述了自己对机器学习、人工智能等的思考。
随着摩尔定律逼近极限,电脑性能到达了一个新的高度。信息技术的历史将翻开新的一页:以人工智能为中心的新时代已经拉开了序幕,将带来继互联网、智能手机之后的新一轮革命。
在 UC Berkeley,我有幸对话 ML@B (Machine Learning @ Berkeley) 的两位创始人 Ted Xiao 和 Gautham Kesineni,他们同时也是 BAIR (Berkeley Artificial Intelligence Research Lab) 的学生。

引起大量关注的为黑白图片上色的算法正是来自于 BAIR 实验室
ML@B 创立不到一年,已经与 GitHub, SAP, Intuit 等企业有了多次合作,也在 UC Berkeley 迅速收获大量关注。他们致力于将机器学习普及到 UC Berkeley 的各个研究领域。与此同时,他们也在进行机器学习相关的研究。
他们正在为 GitHub 研究识别项目语言的机器学习算法,将在完成后投入实际使用;他们也在在开发新的基于 TCP 协议的并行机器学习项目 Open Brain。在这次访谈中,我们将听听他们在公司合作与学术经历中得到的洞见。
数据,企业机器学习的命脉
机器学习有两个必需的要素:计算能力和大量实际数据。
现在获取高性能计算能力的便捷程度在几年前是无法想象的。过去,想要做高性能运算,首先要先去自己组一个高性能服务器,价格极其高昂不说,还要花大量时间和精力去组装、维护;许多实验室花费甚至近百万自建服务器集群用于高性能计算。但现在,有了 Google Cloud Platform、 Microsoft Azure、 Amazon Web Services 等成熟的高性能、可伸缩的 IaaS (Infrastructure as a Service) 平台,不仅价格按时计算,也省去了自己维护的麻烦,成本大大降低。

YouTube 释出八百万标注好的视频用于视频相关的机器学习
随着机器学习受到的关注越来越多,其社区支持也不断壮大。网络上有了大量公开数据,种类也极其丰富;许多大公司也秉着开源精神,释出了许多优质数据库(比如 YouTube 8M)。关于一些具体的研究问题,甚至有标准数据库(如 The MNIST Database)用于研究或测试算法性能。
对于科研人员和学生而言,当下可以称得上是机器学习研究的黄金时代。然而对于真正的企业而言,获取一个具体问题的大量数据仍然是算出好的模型的关键。Gautham 告诉我,就目前而言,数据造成的企业差距还没有那么明显;但是有一天,数据也终将成为一种壁垒;而这一天正在慢慢接近。
从机器人到人工智能,越来越多工作将被取代
我们必须面对这样一个现实:机器正在将逐步取代人类的工作。
过去,机器取代的更多是机械重复的工作。即使没有人工智能,机器已经有可靠、经济、精度高、不疲劳、一次性投入持续产出等诸多优势。在牛津大学一份 2014 年的报告中,英国 35% 的工作将在未来十到二十年内被取代。这个过程已经开始发生,在富士康的流水线上,机器人已经开始取代传统工人的地位:今年五月,富士康用机器人替换了 60000 名工厂工人。
如今加上人工智能的技术加持,机器能够胜任决策重复的工作。只要输入是有限的,决策方式是可重复的,机器就能从不断的训练中变得强大。AlphaGo 战胜李世石,正式向世界证明了人工智能可以在这类问题上胜过人类。这标志着人工智能开始有能力取代有脑力决策参与的工作。首先被各大公司盯上的就是司机行业,不论是IT巨头还是汽车大厂,个个都摩拳擦掌,争相研发无人驾驶算法,许多公司已经研发出了较为成熟的技术。可以说,无人驾驶替代传统司机已指日可待,在 Uber 和 Lyft 的对于未来的规划蓝图中,绝大部分司机也将在不久的将来被自动驾驶汽车取代。仍然存有变数的只是具体实施细则而已。
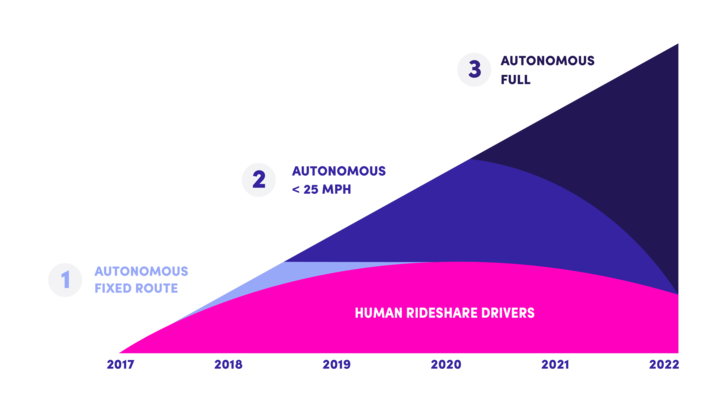
Lyft 的五年计划中,人类司机的占比将慢慢下降
司机当然不会是唯一收到冲击的行业:但凡有符合上述条件的工作,都会在未来渐渐受到影响。而随着人工智能的水平的不断提高,人工智能可以取代的岗位将越来越多。这对人类到底是福是祸?
Ted 和 Gautham 都很乐观,因为这意味着人类可以将时间花在更多更需要高级智能的工作上,而不是浪费时间机械重复。但这可能也表示,未来工作的教育门槛可能会更高。
设计者不知道人工智能做出决策的原因,但没有关系
人工智能如此优秀,是因为人工智能通过大量数据的输入,猜测出数据内在的规律。在人工智能做出决策时,它只是将输入放入经验模型进行计算而得出输出。稍对神经网络算法有一些理解的人们知道,随着神经网络层数的增多,模型也就变得极为复杂。

一个『初级』的神经网络,中间的复杂连接已经令人眼花缭乱
要彻底讲清神经网络在这片文章里做不到,但是我们可以大致看看为什么神经网络难以理解。上图展示了一个初级的神经网络:第一列是输入层,每一层的每一个神经元都由上一层的每一个神经元决定,直到最后一层输出层。但是即使是初级神经网络,其内在关系都千丝万缕难以捉摸。在一个复杂的神经网络中,可能有多达九十多层这样的神经层,真叫做『剪不断,理还乱』,想要直观地去理解这中间发生的事情是非常困难的。
Ted 告诉我,如果人类创造了一个非常厉害的智能,却不知道这个智能是如何运作的,这确实想想都有些可怕。“现在在 Stanford 和 Berkeley,许多人在努力将建立的大型模型视觉化,努力弄清楚中间到底发生了什么,让他们变得更加能够被理解。”
而 Gautham 则提出了不一样的见解。他认为,总有一天,机器学习训练出来的人工智能会变得极其复杂,以至于想要彻底弄清楚这个模型的工作原理是几乎不可能的。
我们应该学会习惯这种情况。而且这并不可怕,只是一个黑盒而已。
确实,在我们生活中,处处都是黑盒。比如一个自动售贩机,你放进钱,选择好你要的饮料,饮料就会出来;你并不知道中间到底发生了什么。自动售贩机有时会出错:你明明选择了可口可乐,吐出来的却是农夫山泉;或者你明明塞进去了10元,买完可口可乐却只吐出1元。但自动售贩机绝对不会用那个播音乐的喇叭嘲笑你——因为它在设计之初就并没有嘲笑你的功能。在设计一个人工智能时也是一样,比如 AlphaGo:虽然它非常聪明,但它也只是会下围棋而已。
其实我们早已经生活在这种可控的未知里,人工智能并没有什么两样。
仍在萌芽,却在飞速增长
虽然机器学习在这两年发展极快,但是相关岗位的需求却没有想象的大。Ted 聊起去年 Berkeley 的招聘会,机器学习岗位普遍要求有博士学历,而且往往都是一些大公司在招聘相关岗位。可以看到,机器学习仍然还没有走下计算机科学的神坛。但是今年随着 AlphaGo 四比一击败李世石,世界认识到了机器学习的威力,机器学习的岗位确实相较往年有了显著的增加。在近几个月,硅谷机器学习相关的项目如雨后春笋冒出,他们也明显感觉到了潜在的合作不断在增加。
总结:最好的时代,最坏的时代
有了机器学习的助攻,人类有了研究传统科学难以研究的复杂问题的能力;人们甚至可以将机理尚不清晰的模型直接部署到产品中,去帮助人类解决问题。但是随着人工智能的迅速崛起,社会的就业结构也遇到了巨大的考验,简单人力工作的市场势必受到机器人与人工智能的挤压而缩水或者转移。对于机器学习领域的研究者和公司而言,这是最好的时代;而对于另一部分人而言,也许一场就业危机正埋伏在不远的将来。
附:如果你对 ML@B (Machine Learning @ Berkeley) 有兴趣,可通过以下联系方式进行邮件沟通: [email protected]。





