






微软这项黑科技能让 AI 更好地理解人类交流
AlphaGo 在上半年的火热,让越来越多的人记住了 AI,即“人工智能”,这一崭新技术。不过,实际上,当我们现在讨论人工智能时,大多数情况是指“弱人工智能”。
为此,我们也不得不正视一个事实,当前的人工智能更多的是针对某个具体的问题,发展对应的算法和技术。有人称之为“拼图式”的工作方法:先做出了视觉模块、再拼上语音模块、推理模块——把每个子领域的功能做好,然后再组合出一个完整的智能系统出来。
随着人工智能拼图不断趋于完整,那么计算机真的能像人类一样智能吗?
当前,人工智能可能能轻而易举的战胜一个三四十岁经验丰富的世界顶尖棋手,但是它的学习能力以及完成一般任务的能力也可能都远不及一个三四岁的孩童。

这个问题的答案可能是“常识”——理解是万物的基础。
针对这个问题,微软亚洲研究院正式发布 Microsoft Concept Graph 知识图谱和 Microsoft Concept Tagging 模型,用于帮助机器更好地理解人类交流并且进行语义计算。Microsoft Concept Graph 是一个大型的知识图谱系统。其包含的知识来自于数以亿计的网页和数年积累的搜索日志,可以为机器提供文本理解的常识性知识。
苹果是什么?
人们在正式上小学、初中接受系统性教育开始,已经早早地开始了学习的过程。这种与生俱来的本能能让你进入小学之前已经了解诸如“糖是甜的食品”、“水是一种液体”这一类基础的概念,并且随着年龄的增长,这种并不属于某个专业领域的开放性常识也在人们的认知中日积月累,并不断丰富。
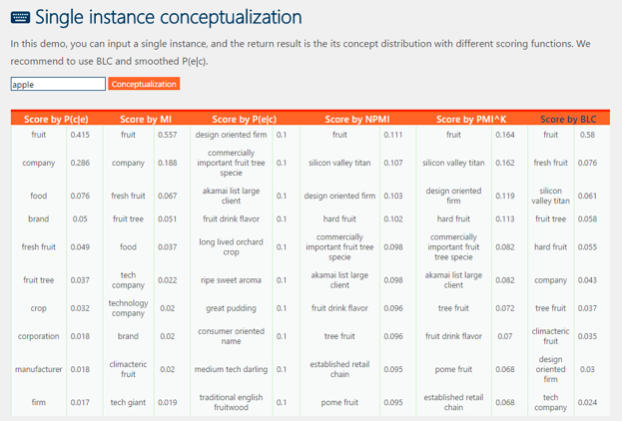
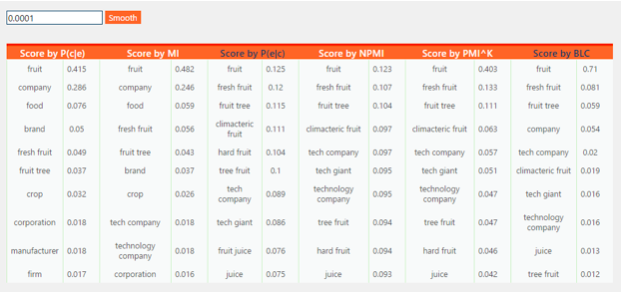
微软亚洲研究院今天发布的 Microsoft Concept Graph 就在试图让计算机复制这些常识性概念,其核心知识库包含了超过 540 万条概念。
除了包含一些被绝大部分通用知识库包含的概念,例如“城市”、“音乐家”等,Microsoft Concept Graph 还包含数百万长尾概念,例如“抗帕金森治疗”、“名人婚纱设计师”、“基础的水彩技巧”等,而这些概念在其他的数据库中很难被找到。除了概念,Microsoft Concept Graph 同样包含了大量数据空间(每条知识概念都包含一系列的实体或者子概念,例如“太阳系”底下可能就会包括“水星”、“火星”、“地球”等等)。
苹果是甜的
当你看到“苹果是甜的”这句话时,你几乎可以肯定这里的“苹果”指的是我们最常见的那种水果。在这几毫秒的时间里,你触发的是“根据上下文语境确定语义”这一技能。微软亚洲研究院的研究员们同样也为计算机点亮了这棵技能树。
Microsoft Concept Tagging 模型可以将文本词条实体映射到不同的语义概念,并根据实体文本内容被标记上相应的概率标签。例如“微软”这个词可以被自动映射到“软件公司”和“科技巨头”等概念,并带有相应的概率标签。这个模型让计算机拥有常识性的计算能力,让机器“了解”人类的意识,从而让机器可以更好地理解人类的文本交流。具体来说,概念模型根据人类的概念推理将实体或者短语映射到大量自动习得的概念空间(向量空间)。这种映射关系是人类和机器都可以理解的。因此该模型提供了文本理解所需的文本概念映射、短语语义化理解等功能。
Microsoft Concept Tagging 模型区别于以往常见的文本推理模型的根本区别是他是基于网络之上的一个推理模型,将文本映射到一个显式的知识空间,将文本概念化。
理解是万事万物的基础
“我们想做的,是让计算机能够更好地理解人类。”现负责 Microsoft Concept Graph 和 Microsoft Concept Tagging 模型的微软亚洲研究院资深研究经理闫峻博士说,“理解是万事万物的基础,我们用计算机抓取过去这些不成文的开放领域的常识,能够帮助计算机更具象地了解这个世界。”
谈及 Microsoft Concept Graph 和 Microsoft Concept Tagging 模型的下一步计划,闫峻博士表示目前该模型暂只能支持英文,还要和高校合作完成中文的支持工作。在完成中文的知识库构建之后,再逐步扩展到多语言版本。其次,人类的语言还涉及到比喻、夸张和玩笑等高层次跨领域的抽象表达方法,这也是接下来需要让机器不断学习的方向。最后,从短文本的理解到长文本的理解,如理解两个完全不同的故事,但语义层面在表达同样的道理,也是他们接下来不断努力的方向。





