






苹果公布年度最流行 emoji,背后如何做到收集用户信息又保护隐私?
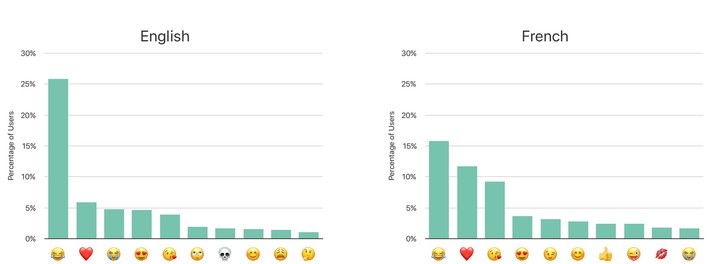
年底到了,苹果公布了今年最流行的 emoji,在英美法三国的统计中,最受欢迎的 emoji 是笑着哭的表情(Face With Tears of Joy),第二流行的 emoji 则是红心( Red Heart)。
搜索微信公众号爱范儿(微信号:ifanr), 后台回复「emoji」,iOS 11 最新款 emoji 的清晰 png 版本打包送给你。
对于我们而言,每天使用 emoji 已经习以为常,它们替代我们更便捷地表达了内心的感受。不过问题来了,一直宣称注重保护用户隐私的苹果,是如何获取用户每天在键盘上发送出去的数据信息,进而整理出这个榜单的呢?
最近,苹果的机器学习日报(Machine Learning Journal)刊文解释了他们是如何通过“差分隐私”( Differential Privacy)的方式,在保护用户隐私的情况下收集到用户群体的使用习惯。
差分隐私这项技术,主要是在收集数据的过程中,加入一些随机的干扰信息,将用户的个人数据打乱,然后与其他数百万人的数据混合在一起。这样一来,苹果就只能看到整体的状况,而看不到个人的具体数据。即使数据库中的信息被泄露,也无法将信息对应到各个具体用户。
差分隐私的原理,其实与统计人员做调查时,用来保护受访者隐私的办法是类似的。比如,想要调查某个人群的出轨率,为了保护受访者的隐私,并且提高人们如实回答的意愿,调查者通常会这样设置调查方式:
调查问题是“你是否曾经有过出轨行为”,答案只有“是”和“否”两个答案。然后每个人发一枚硬币,在回答这个问题之前先抛掷硬币,如果正面朝上,就回答真实情况,如果反面朝上,就再投掷一次硬币,正面就回答“是”,反面就回答“否”。当然,第一次投掷为正面的人,也可以假装再投掷一次硬币来混淆视听。
调查后会获得 X 份问卷,其中有 Y 个人回答“是”,则可计算出这个人群的出轨率为(Y-X/4)/(X/2) 。即使这些收集到的问卷被盗或者泄露,受访者的隐私依然能够被保护。
需要明确的是,数据不等同于隐私,两者的定义是不一样的。隐私是对应单个用户,比如,美国人Amy 最常使用的 emoji 是“笑着哭”,这是属于他的个人隐私;苹果公布英语用户最喜欢使用的 emoji 是“笑着哭”,这是对应群体用户的信息,则不算隐私,但是如果可以从这些数据中推算出 Amy 的 emoji 使用习惯,那就是用户隐私泄露。

在去年的 WWDC 大会上,苹果就宣布使用差分隐私的方式来收集用户信息,并且首先应用到分析流行表情符号,收集 Safari 中能耗率高的网页信息,以及发现新流行词语(QuickType 相关)上。
应用差分隐私方案,根据添加干扰信息的先后,可以分为两种设置:本地和中央。
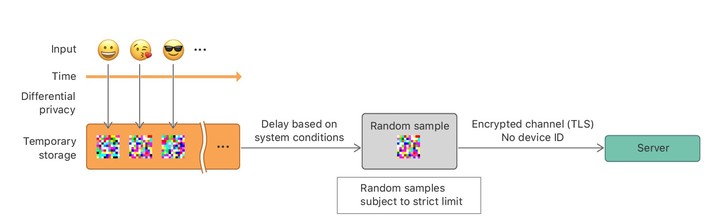
(差分隐私收集数据的方式,图片来自苹果)
苹果在论文中讲述了“本地差分隐私”这一方案的使用:在数据从用户设备发出之前,就会添加上干扰信息,同时每天只会通过加密通道上传一次数据,数据在到达服务器后,设备的 IP 标识会被丢弃,各个记录之间的关联也会被丢弃。
当然,iOS 10、macOS Sierra 以上的用户,可以自己选择是否要加入差分隐私,在 iPhone 的隐私菜单,苹果电脑的控制台中,可以自主设置。
不过,差分隐私政策真的安全吗?据外媒《连线》今年 9 月的报道,已经有学者反向研究出苹果随机加入干扰信息的详细步骤,并指出“差分隐私的有效性取决于被称为隐私损失参数或‘epsilon’的变量,这个变量决定了数据收集者为了保护其用户的秘密而愿意牺牲多少特异性”。他们认为苹果在 MacOS 上所设置的参数变量,上传了比预期更多的用户隐私信息。
曾任 Google 研究科学家的 Aleksandra Korolova 在《连线》的报道中说道:“苹果的隐私损失参数,已经超出了差分隐私研究领域中人们通常认为可以接受的程度。”
不过苹果也对此进行了反驳,他们说自身的差分隐私系统为不同类型的数据里添加了不同的干扰信息,远比这些研究人员所得出的结论要安全,并且会去掉不同数据类型之间的关联。
然而学者和公众也有同样的顾虑,苹果自认为所搜集的用户数据之间的关联已经被去除,但是不排除有人可以逆向倒推出来。
如今无论在哪个行业和产品,通过收集数据了解用户使用情况,对于改进产品、提升用户体验至关重要。随着数据挖掘和人工智能技术正逐渐成为优化产品的重要驱动力,用户使用产品的数据已经是驱动算法迭代的能量。没有产品经理能够放弃用户信息,就看他们是否愿意、会用什么办法保护我们的隐私了。
iPhone 和 Android 手机怎么使用才会更安全?搜索微信公众号爱范儿(微信号:ifanr), 后台回复「安全」,获取手机安全使用指南集合。






