








 大声 | 11-28 15:14
大声 | 11-28 15:14

我们在打造南网的电鸿,行业的电鸿,生态的电鸿,更是开辟未来的电鸿。

M5 Macbook Pro 首发体验:可能是最接近「游戏本」的一次
4:42
最适合记录生活的小相机!Insta360 GO Ultra 上手体验
2:34
iPad Pro M5 首发体验:eSIM 升级,但还有更多
1:21
视频|正面对决!大疆 OSMO nano 和影石 GO Ultra 怎么选?
04:53
视频|戴上眼镜,起飞!影翎 A1 全景无人机首发评测
04:33
视频|大疆首款扫地机实测:占领天空后,又来统治地板?
05:39
视频|这台全景相机,让我重现《F1》飞车镜头
04:22
视频|买前必看!2025 年 AI 眼镜怎么选?
03:05
视频|小米 MIX Flip 2 首发体验:升级点,都在点上
03:39
在开发者大会,华为给每个「走得慢的人」留了座位
06:43
手机影像的风向标!华为Pura 80 Ultra 影像实测
10:19
视频|鸿蒙电脑,靠国产软件能用起来吗?
5:11
专访苹果副总裁:AI 时代,苹果如何设计 Mac?
09:08
视频|你见过物理外挂吗?这就是!
09:51
拍港风夜景人像大片,只用一部 OPPO Find X8 Ultra!
06:39
视频|华为 Pura X 一周感受:这是最佳的折叠屏形态吗?
03:41
视频|卖 399 的 AI 键盘,到底有没有用?| 明日打假办
02:23
M4 MacBook Air 真机速看:蓝色西装,性能暴徒
2:25
视频|首发实测:10 万块的顶配 Mac,能跑满血版 DeepSeek 吗?
3:41
iPhone 16e 首发评测:信号好续航强?和 iPhone 16 比比看
05:16
早报|小米17 Ultra跑分曝光/OpenAI考虑在ChatGPT中投放广告/鸿蒙智行首款MPV或首发「头套气囊」
· 零跑汽车迎来 10 周年,多家车企祝贺
· 曝豆包日均活跃用户数破亿
· 索尼第六代「降噪豆」有望回归硅胶耳塞

-
-




早报|ChatGPT首次推出「年度回顾」功能/吴彦祖出任小米影像体验官/《复联5》首支预告公布
· 京东深夜回应「巴黎仓库被盗」
· 微信辟谣「点快手直播致盗号」:不属实
· 麦当劳将上新蛋挞与枫糖松饼堡
-
-


早报|快手回应大量色情直播刷屏:遭黑灰产攻击,已报警/旧金山停电无人车集体趴窝,马斯克称特斯拉不受影响/央行推「免申即享」征信修复
· 三星明年或推「阔折叠」对标折叠屏 iPhone
· 阿里千问 App 发布 2025 十大 AI 提示词
· 吉利汽车完成极氪私有化并全资控股

-
-
加载更多
-
科技创新的星辰大海,从来不是独行者的远征。任何伟大的创新,都离不开开发者、生态伙伴和用户的共同奔赴。鸿蒙系统正是这一理念的生动体现,它从技术无人区起步,通过开发者和生态伙伴的持续投入,成长为全球第三大移动操作系统。 近日,主持人陈鲁豫和四位不同背景、各具特色的鸿蒙开发者展开了一场深度对话。从开发者的视角出发,生动呈现了生态背后的温度与创新力量——鸿蒙生态是开放包容的,开发者的想法被重视,创意能落地,能和鸿蒙一同“玩”出创新,也一同推动生态持续前行。
 “每日咖啡”的创始人李尚儒是一位97年的独立开发者,法律专业出身的他,自己一个人一台电脑开发鸿蒙,凭借“每日咖啡”等鸿蒙应用已实现稳定每月六七万的收入。李尚儒表示,选择鸿蒙是因为它没有“历史包袱”、技术新颖、市场潜力巨大。在鸿蒙这片“蓝海”中,小产品只要足够精致新颖,也能成为大爆款。他感受到的,是鸿蒙生态对独立创作者的平等与扶持,这也让他能够专注于创意实现。
“每日咖啡”的创始人李尚儒是一位97年的独立开发者,法律专业出身的他,自己一个人一台电脑开发鸿蒙,凭借“每日咖啡”等鸿蒙应用已实现稳定每月六七万的收入。李尚儒表示,选择鸿蒙是因为它没有“历史包袱”、技术新颖、市场潜力巨大。在鸿蒙这片“蓝海”中,小产品只要足够精致新颖,也能成为大爆款。他感受到的,是鸿蒙生态对独立创作者的平等与扶持,这也让他能够专注于创意实现。
 “一封来信,一份使命”,驱动着小宇宙鸿蒙项目的负责人李会洋。一位准宝妈的“万字来信”,那句“不能没有小宇宙”的依赖,让他毅然决然拥抱鸿蒙,立下“非做不可”的信念。应用上线后用户量翻倍增长的曲线,是对这份真诚最好的回馈。
“一封来信,一份使命”,驱动着小宇宙鸿蒙项目的负责人李会洋。一位准宝妈的“万字来信”,那句“不能没有小宇宙”的依赖,让他毅然决然拥抱鸿蒙,立下“非做不可”的信念。应用上线后用户量翻倍增长的曲线,是对这份真诚最好的回馈。
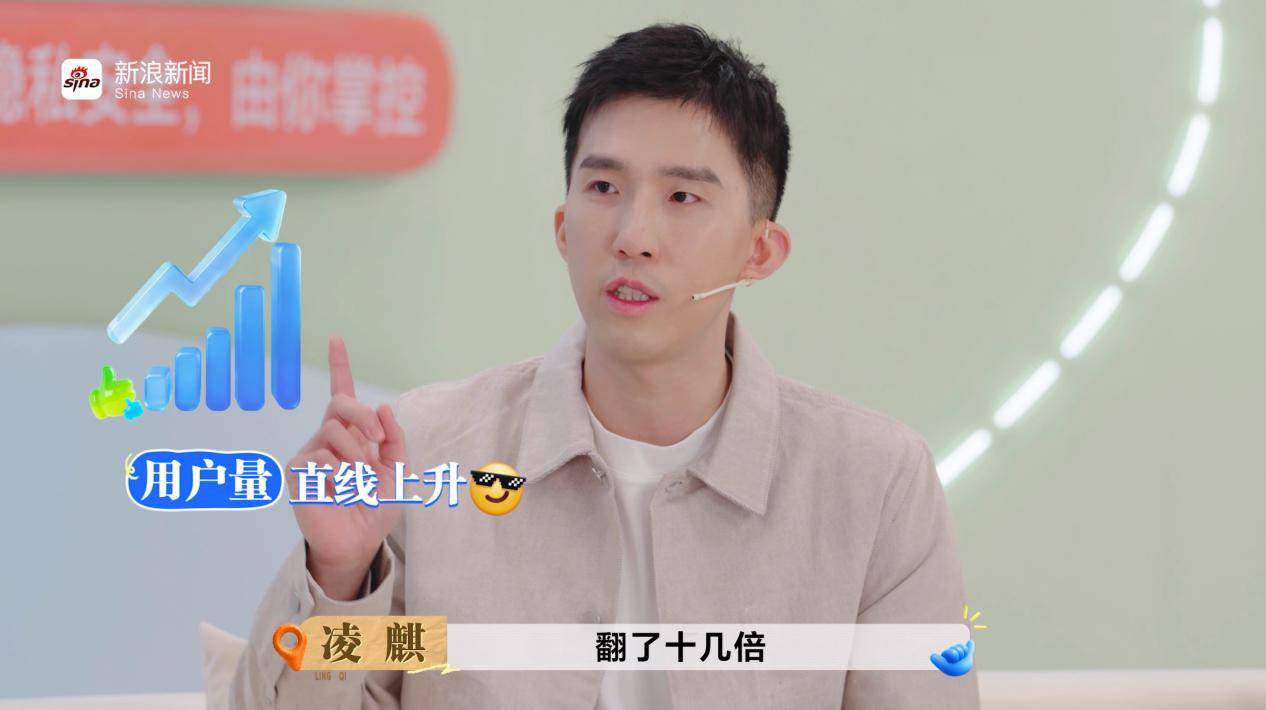
 “圆周旅迹”的开发者凌麒则在鸿蒙上实现了其他平台无法提供的功能。他的旅行规划应用,在鸿蒙上借助“碰一碰”分享、多端协同等独家创新特性,解决了用户跨平台找攻略、组队规划的痛点。同时获得了鸿蒙生态丰富资源和扶持,极大推动了产品创新与用户连接。“我们本来打算自己去铺路的,结果发现鸿蒙早就帮我们准备好了高速公路。”凌麒说道。
“圆周旅迹”的开发者凌麒则在鸿蒙上实现了其他平台无法提供的功能。他的旅行规划应用,在鸿蒙上借助“碰一碰”分享、多端协同等独家创新特性,解决了用户跨平台找攻略、组队规划的痛点。同时获得了鸿蒙生态丰富资源和扶持,极大推动了产品创新与用户连接。“我们本来打算自己去铺路的,结果发现鸿蒙早就帮我们准备好了高速公路。”凌麒说道。
 Canva可画的中国区总经理王可辛则看到了更远的未来,加入鸿蒙是其全球化战略的关键一步。她与鸿蒙团队的交流,更被一种“并肩作战”的使命感点燃。她坦言:“有些合作像甲乙方,但和鸿蒙,更像为同一目标解决难题的战友。”而创始人的那句“Do it”更是对鸿蒙生态最好的信任与肯定,不仅在国内获得机会,也为未来跨端、国际化体验进行了尝试。他们的加入,展现了鸿蒙在全球范围内的吸引力和潜力。
Canva可画的中国区总经理王可辛则看到了更远的未来,加入鸿蒙是其全球化战略的关键一步。她与鸿蒙团队的交流,更被一种“并肩作战”的使命感点燃。她坦言:“有些合作像甲乙方,但和鸿蒙,更像为同一目标解决难题的战友。”而创始人的那句“Do it”更是对鸿蒙生态最好的信任与肯定,不仅在国内获得机会,也为未来跨端、国际化体验进行了尝试。他们的加入,展现了鸿蒙在全球范围内的吸引力和潜力。
 不得不说,鸿蒙生态不仅承载了技术创新,更汇聚了丰富的生活场景:工作间隙的播客收听,创意设计工具的即时呈现,旅行记录的社交互动,日常生活的点滴记录……这些看似平凡的体验,正是生态活力的真实体现,也让“在一起 就可以”的理念得以落地。
数字见证了鸿蒙这片舞台的吸引力:截至目前,搭载HarmonyOS 5和HarmonyOS 6的终端设备已突破3200万台,日增超过10万台。鸿蒙应用市场可搜索应用及元服务数量突破35万,联合超过2.3万款应用打造70多项鸿蒙创新特性。正是这一个个鲜活的数字,见证了生态因开发者而丰富、因合作而强大。
在鸿蒙的舞台上,每一开发者都是主角,每一次灵感闪现都可能成为改变体验的起点。这正如鸿蒙星光盛典所传递的核心理念一样“在一起,就可以”,当技术的边界被不断突破,当创意与真实生活深度交汇,一个由无数个体共同托举的生态正在生长。它不仅孕育应用与产品,更孕育信心与未来,让创新不再孤行,让可能持续发生。
不得不说,鸿蒙生态不仅承载了技术创新,更汇聚了丰富的生活场景:工作间隙的播客收听,创意设计工具的即时呈现,旅行记录的社交互动,日常生活的点滴记录……这些看似平凡的体验,正是生态活力的真实体现,也让“在一起 就可以”的理念得以落地。
数字见证了鸿蒙这片舞台的吸引力:截至目前,搭载HarmonyOS 5和HarmonyOS 6的终端设备已突破3200万台,日增超过10万台。鸿蒙应用市场可搜索应用及元服务数量突破35万,联合超过2.3万款应用打造70多项鸿蒙创新特性。正是这一个个鲜活的数字,见证了生态因开发者而丰富、因合作而强大。
在鸿蒙的舞台上,每一开发者都是主角,每一次灵感闪现都可能成为改变体验的起点。这正如鸿蒙星光盛典所传递的核心理念一样“在一起,就可以”,当技术的边界被不断突破,当创意与真实生活深度交汇,一个由无数个体共同托举的生态正在生长。它不仅孕育应用与产品,更孕育信心与未来,让创新不再孤行,让可能持续发生。 -
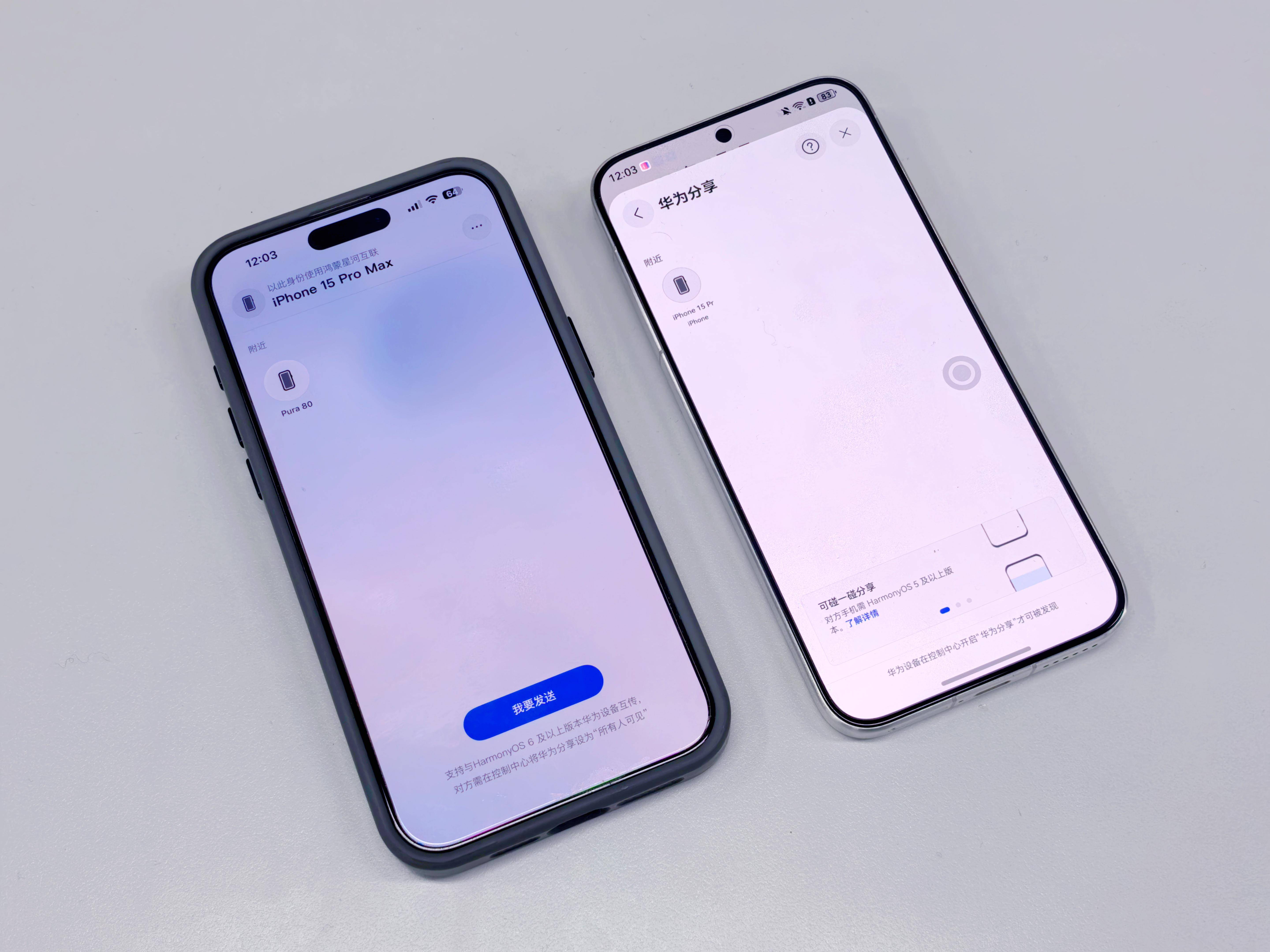
如果要给 2025 年数码圈挑一个用户期待的功能,「与苹果设备互传」肯定能排进前三。 我们发现,许多原本就手持 iPhone 的用户,近两年都开始实行「双持」策略——当中有许多人也像我一样,左手 iOS,右手鸿蒙。 双持的原因也很简单,一边是被折叠屏形态、长续航、快充、信号这些体验优势种草,想享受更好的日常使用体验;一边又舍不得多年来在 iOS 里攒下来的应用生态和游戏、账号、存档。 结果就是,人还在同一个地球,手机却活在两个平行世界里,就像两个母语不同的老外,明明说的都是「手机」,却谁也听不懂谁,交流起来很困难。 既然山不过来,那么 HarmonyOS 6 现在给出了一个最新的答案:我过去。
HarmonyOS 6,让苹果设备一秒学会「华为互传」
对单一生态用户来说,AirDrop 也好、华为分享也好,在自己那一侧都很顺滑。只是一旦变成双持用户,日常就逃不开一连串「互传难题」:微信一传就压缩、网盘要上传下载绕一大圈、临时还得找数据线/硬盘做中转。更麻烦的是和别人互传——对方要是也不在同一生态里,这套折腾往往还得再来一遍。 甚至有些时候不得不撂下一句:「发你邮箱吧」「回头再弄吧」,然后这件事很可能就被拖着拖着,最后直接忘了。 所以问题从来都不是没有互传方案,而是过去的方案大多又慢又碎、门槛还高。跨生态互传这件小事,却常常要用户付出近似「搬家」的精力,谁用谁崩溃。 为了方便更多的分享场景需求, 伴随着 HarmonyOS 6 的正式推出,华为在苹果端也同步推出了 「鸿蒙星河互联」App,覆盖 iPhone、iPad 和 Mac。 只要在苹果设备上装好并打开这个 App,你的 iPhone / iPad / Mac 就等于「学会了」华为分享:动图、视频、文件、通讯录,都可以直接在苹果与华为设备之间高速互传。 更直观的是两边都能「互相看见」——华为设备的华为分享面板里会出现苹果设备;而在苹果设备的鸿蒙星河互联 app 里,也能直接找到附近的华为设备,一点就传。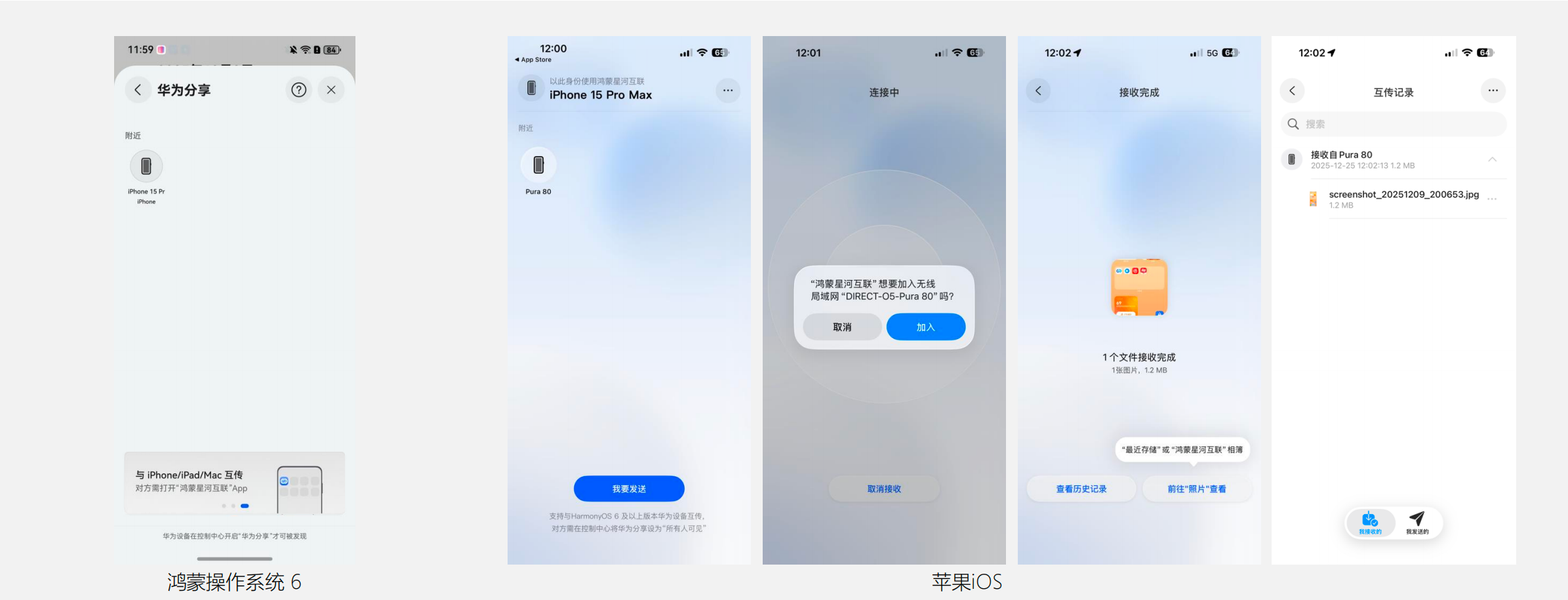 如果两台设备是在同一个局域网,例如在家中、咖啡厅这样的地方,并且都连接在同一个 WiFi 下,那么鸿蒙星河互联会优先使用局域网来传输文件;如果是在户外没有 WiFi 的情况下,那么鸿蒙星河互联就会以连接华为设备 WLAN 的方式完成互传。
正如前文所述,华为设备和苹果设备之间可以互传动图、视频、文档、通讯录等文件,不但支持大文件传输,也支持文件多选的传输,非常方便。
既然跨设备互传的底层依然是「华为分享」,那华为设备原本的多设备并发能力也完整保留。也就是说,从华为设备端发文件时,最多可同时向 4 台苹果设备进行传输。
这也就意味着,你用华为手机拍到的演唱会图片和视频,不用再排队等待「点名发送」,可以一口气分享给 4 个拿 iPhone 的朋友——速度更快,现场也更省事。
可见,HarmonyOS 6 带来的最大变化,是让跨生态互传真正回归「本该如此简单」:大文件无损传输、不需要网盘当中间商、更不用耗流量,直接高速直连,把过去那套繁琐的中转流程一刀切掉。
如果两台设备是在同一个局域网,例如在家中、咖啡厅这样的地方,并且都连接在同一个 WiFi 下,那么鸿蒙星河互联会优先使用局域网来传输文件;如果是在户外没有 WiFi 的情况下,那么鸿蒙星河互联就会以连接华为设备 WLAN 的方式完成互传。
正如前文所述,华为设备和苹果设备之间可以互传动图、视频、文档、通讯录等文件,不但支持大文件传输,也支持文件多选的传输,非常方便。
既然跨设备互传的底层依然是「华为分享」,那华为设备原本的多设备并发能力也完整保留。也就是说,从华为设备端发文件时,最多可同时向 4 台苹果设备进行传输。
这也就意味着,你用华为手机拍到的演唱会图片和视频,不用再排队等待「点名发送」,可以一口气分享给 4 个拿 iPhone 的朋友——速度更快,现场也更省事。
可见,HarmonyOS 6 带来的最大变化,是让跨生态互传真正回归「本该如此简单」:大文件无损传输、不需要网盘当中间商、更不用耗流量,直接高速直连,把过去那套繁琐的中转流程一刀切掉。
让互联回到「理所当然」,才是真正的懂用户
HarmonyOS 6 的「鸿蒙星河互联」最打动人的地方,并不是把功能堆得多炫,而是它终于把「用户每天都在做、却一直很难做顺」的小事,认真打磨到顺手、自然、几乎不用思考。 对用户来说,跨生态互传不再是一次次靠耐心和运气完成的折腾,而是一种稳定可依赖的底层能力:该快的时候快、该稳的时候稳,流程足够短,动作足够直接。 这种体验升级带来的变化也很现实:效率提升肉眼可见,生活琐事被悄悄省掉,设备之间的距离被真正拉近。 你不会因为「传文件太麻烦」而放弃分享,也不会因为「回头再弄」而错过重要时刻。HarmonyOS 6 用更人性的逻辑,把系统从「会用」推到了「懂你」。当你习惯了这种连续、顺滑、少打扰的互联方式,我相信你很难再回到过去那些压缩、中转、等待的将就里。 如果你也是那个桌上同时放着华为和苹果设备的人,下次互传的时候记得用上 HarmonyOS 6 的这套互传方案。之后你可能会偶然意识到,自己已经悄悄从「在两个生态之间奔波」,变成了「让两个生态一起为你服务」。





