





不用在朋友圈学 Python,这款 Chrome 插件就能帮你完成网页抓取
不知大家是否总能在朋友圈看到类似的广告,「加班完成的 Excel 用 Python 只需 3 分钟」、「每天都能准点下班只因学会了 Python」,就像下面这样,似乎 Python 已经成为了当代年轻人的必备技能。
▲ 朋友圈广告
的确,Python 作为一门易于上手的编程语言,在自动化办公中用处巨大,特别是对于网页数据的爬取,在这样一个大数据时代显得尤为重要。
爬取网页数据,也可以称为「网络爬虫」 ,能帮助我们快速搜集互联网的海量内容,从而进行深度的数据分析与挖掘。比如抓取各大网站的排行榜、抓取各大购物网站的价格信息等。而我们日常用的搜索引擎就是一个个「网络爬虫」。
但毕竟学习一门语言的成本太高了,有什么办法可以不学 Python 也能达到目的呢?当然有,借助 Chrome 浏览器的《Web Scraper》插件,让你在不用写代码的情况下,就能快速抓取海量内容。
懒人目录
- 抓取页面中多条信息——bilibili 排行榜为例
- 自动翻页抓取——豆瓣电影 Top250 为例
- 抓取二级页面内容——知乎热榜为例
抓取页面中的多条信息——bilibili 排行榜为例
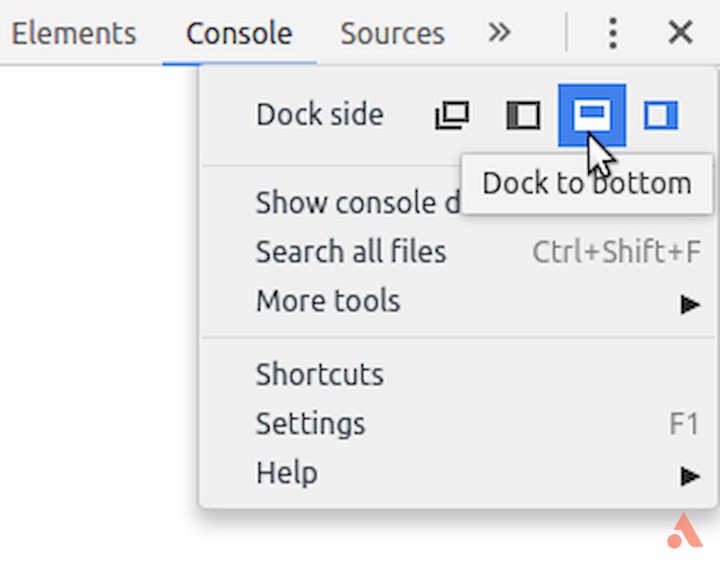
安装《Web Scraper》后,按 F12 进入开发者模式,这样就能在最后一个标签页看到《Web Scraper》的菜单。需要注意的是,如果开发者模式面板不在下方,则会提示必须将其放到浏览器下方才能继续。
在菜单中选择「Create new sitemap – Create sitemap」以创建新的 sitemap,填入名称与起始地址就可以开始了。这里以 bilibili 排行榜为例,介绍如何抓取页面中的多条信息,起始地址设为「https://www.bilibili.com/ranking」。
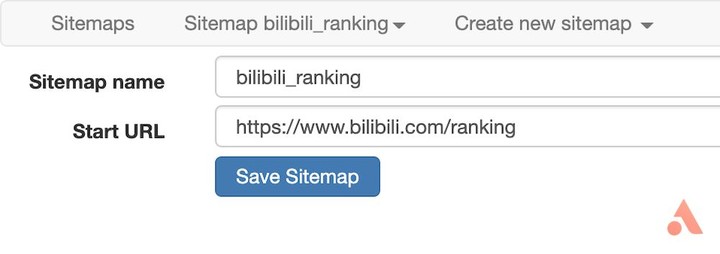
这里我们需要抓取「视频标题」、「播放量」、「弹幕数」、「up 主」以及「综合得分」,因此首先为每一条记录创建一个封装器。
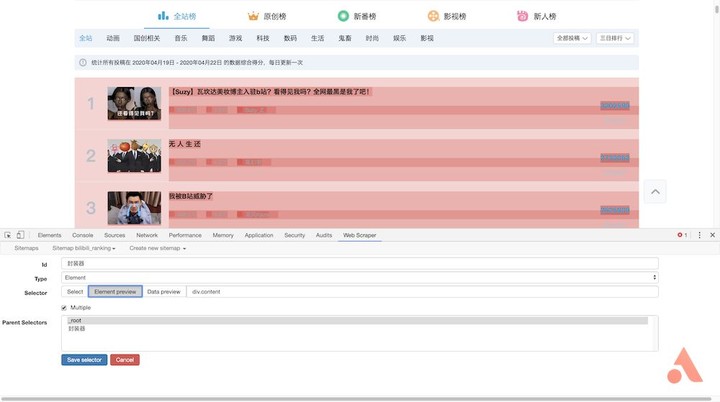
点击「Add new selector」,id 填写「封装器」, type 选择「element」,然后点击「selector」,选择一条记录的外边框,外包框中需要包含上述所有信息,然后再选择第二条,这样就会发现页面中的所有记录都已自动选择,点击「Done selecting」完成数据的选择。还要记得勾选「Multiple」以保证抓取多条记录,最后保存该选择器即可。
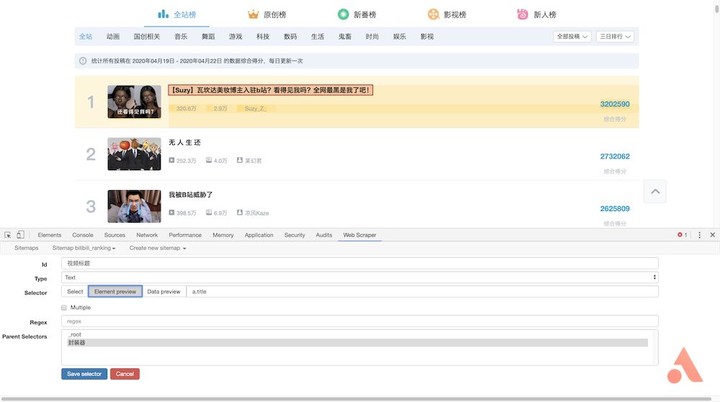
返回后点击刚才的封装器,进入二级路径,创建「标题」选择器,id 填写「视频标题」,type 选择「text」,点击「selector」会发现第一条记录高亮显示,这是因为我们已提前将其设定为了封装器。选择包围框中的标题,再点击「Done selecting」完成标题的选择,注意这里不需要勾选「Multiple」,最后保存该选择器。
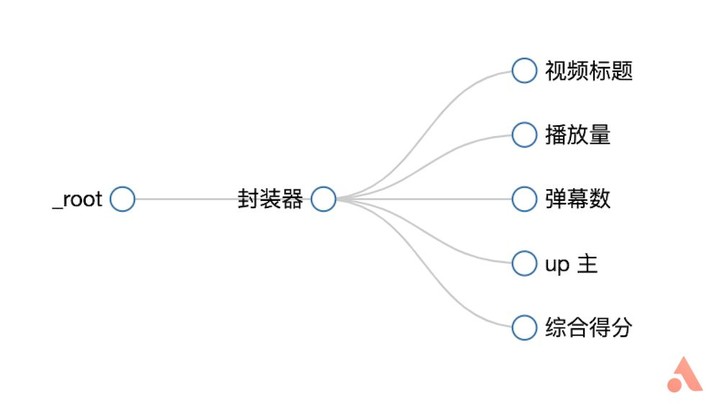
同样的,我们为「播放量」、「弹幕数」、「up 主」和「综合得分」分别建立选择器,选择后可以通过「Data preview」预览是否选中了想要的内容。另外还可以通过菜单栏中的「Sitemap bilibili_ranking – Selector graph」 直观地查看树状结构。
继续在刚才的菜单下选择「Scrape」开始创建抓取任务,单个网页的间隔时间和响应时间默认即可。点击「Start scraping」开始抓取。这时候浏览器会自动打开新的页面,停留数秒后自动关闭,代表抓取已完成。

点击「Refresh Data」刷新数据,或点击「Sitemap bilibili_ranking – Browse」查看数据。通过「Sitemap bilibili_ranking – Export data as CSV」即可下载为 CSV 格式文件。
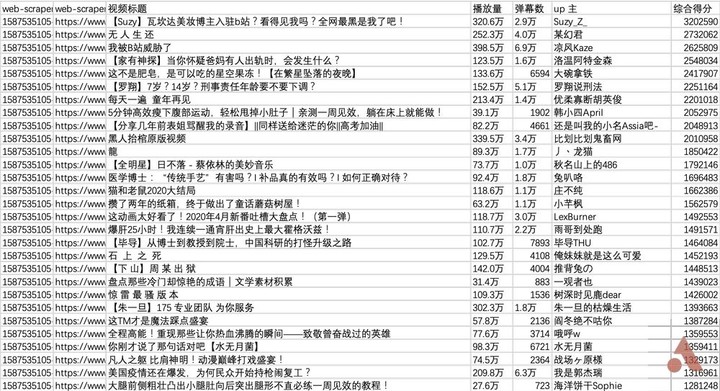
▲ bilibili 排行榜
使用 Excel 打开,由于《Web Scraper》抓取的内容是无序的,因此需要对「综合得分」进行降序排列,以恢复原始排行榜的结果。
自动翻页抓取——豆瓣电影 Top250 为例
Bilibili 排行榜只有 100 条记录,并且都在一个网页中,那么如果有分页显示的情况该怎么办呢?这里以豆瓣电影 Top250 为例介绍自动翻页抓取。
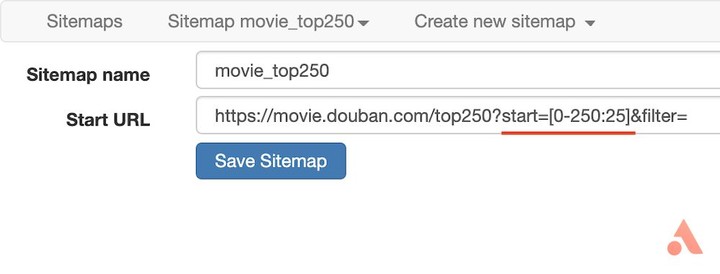
同样的,新建 sitemap,在填写起始地址前,我们先观察一下豆瓣电影 Top250 的构成,总共有 250 条记录,每页显示 10 条,共分为 25 页。

而每一页的网址都非常有规律,第一页的地址为「https://movie.douban.com/top250?start=0&filter=」,第二页仅仅是把地址中的「start=0」改为了「start=25」,因此我们填写起始地址时便可以填写「https://movie.douban.com/top250?start=[0-250:25]&filter=」,这里 start=[0-250:25] 表示 以 25 的步长从 0 取到 250,因此 start 分别为 0、25、50 等等。这样《Web Scraper》就会按顺序一页一页抓取数据了。
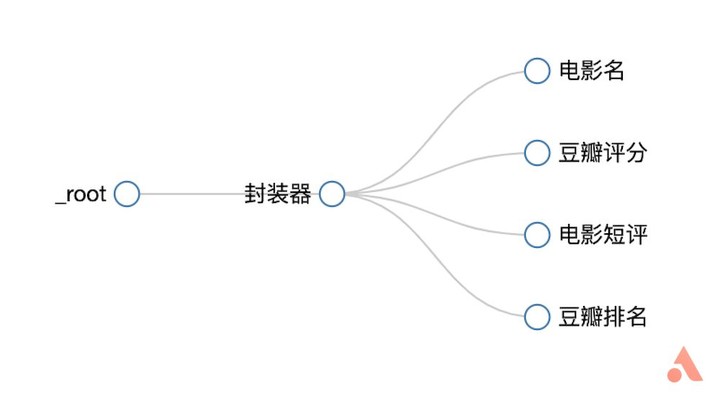
接下来类似于 BiliBili 排行榜,创建「封装器」后再添加「电影名」、「豆瓣评分」、「电影短评」以及「豆瓣排名」选择器就行了,然后开始抓取。
可以看到浏览器会一页一页地进行翻页抓取,这里只需要安静地等待抓取完毕即可,最后得到的数据以「豆瓣排名」进行升序排序,就能获得豆瓣电影 Top250 的榜单了。

▲ 豆瓣电影 Top250
当然,这只是一种最简单的分页方法,而许多网站地址并不一定有着类似的规律,因此《Web Scraper》还有更多的方法能用来分页,但相对较为复杂,在此也不再赘述了。
抓取二级页面内容——知乎热榜为例
以上完成了对网页的单页以及多页内容的抓取,但不是每次都有着现成的数据摆在一个页面中,因此还需要更进一步地对二级页面进行搜寻。以知乎热榜为例,介绍如何对二级页面的「关注量」和「浏览量」进行抓取。
首先,新建 sitemap,起始地址为「https://www.zhihu.com/hot」。然后像前面一样创建「封装器」,再创建「文章标题」、「文章热度」、「知乎排名」这三个选择器。
接下来是重要步骤,创建一个「二级页面」的链接。点击「Add new selector」,id 填写「二级页面」, type 选择「link」,然后点击「selector」,选择文章的标题,即每篇文章的入口,确认选择后保存退出。
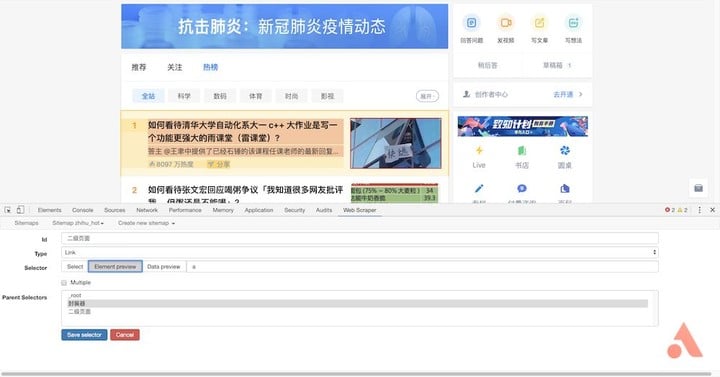
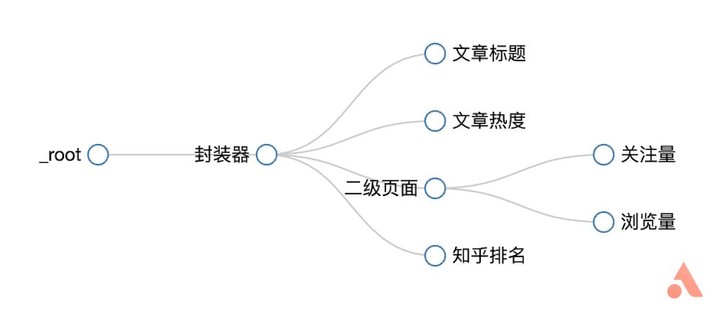
这样就相当于有了一个窗口,点击刚才创建的「二级页面」,进入下一级目录,然后像之前创建「文章标题」一样创建「关注量」与「浏览量」两个选择器。最后整个树状结构如下图所示。
点击「Sitemap zhihu_hot – Scrape」开始抓取,这里可以将「Page load delay」响应时间调大一些,确保网页完全加载完毕。这时候浏览器会依次打开每个二级页面进行抓取,因此需要等待一会儿。
抓取任务完成后将结果下载为 CSV 文件,按「知乎排名」降序排列,即可获得整个知乎热榜的榜单。

▲ 知乎热榜
至此,介绍了如何使用《Web Scraper》抓取页面中多条信息、自动翻页抓取以及抓取二级页面内容。很显然《Web Scraper》的功能远不止这些,还有更多强大的功能比如图片抓取、正则表达式等等可自行摸索。
另外,如果只是想要简单地抓取信息,可以尝试使用其它插件如《Simple scraper》《Instant Data Scraper》,这些插件甚至可以一键抓取,但相比《Web Scraper》,功能的丰富度还是欠缺不少的。
不用学 Python,也不用上某宝花钱让别人帮你,使用《Web Scraper》自己就能完成网页抓取,或许下一个准时下班的就是你?





