






像人类一样说话,Google 的 AI 又点亮了新技能
除了下棋、设计衣服,Google 家的 AI 最近又点亮了一门新技能——说人话。会说话的机器人并不稀奇,苹果的 Siri,微软的小娜,都是我们所熟悉的语音助手。但 Google 家的 WaveNet ,却是能模仿真实人类声音的 AI,并且还精通多国语言、各种乐器,可以说是高配的洛天依。
WaveNet 的前世今生
让人们使用自然语言与机器进行交流,是人类长久以来的梦想。一直以来,计算机生成声音主要依靠文本-语音转换系统,即 TTS( text-to-speech):计算机从朗读者的声音片段组成庞大的数据库中,将文本与声音进行对应,将声音片段组合形成完整的语音输出。

图片来自:DeepMind
然而,这种方法有一个缺陷,就是声音修改非常困难,比如换成一个声音、改变重读部分或者朗读者的感情等。这就要求参数 TTS 存储大量的模型数据、语音内容和声音特点等。除此之外,使用 TTS 转换而来的声音总是显得过于生硬,衔接也不够自然。
因此,也就有了 WaveNet 项目的诞生。WaveNet 是一个能生成原始声波的深度神经网络系统,是 Google 旗下的人工智能公司 DeepMind 开发的项目之一。9 月 12 日,DeepMind 在其官方博客上宣布,WaveNet 已经能够发出高仿真的人类声音。
与 TTS 不同的是,WaveNet 使用的是真实的声波而不仅仅是语言。简单来讲,就是将自然人声输入到系统中,由第一层券积层先进行处理,再反馈至第二层,为下一步的生成提供预测。

图片来自:DeepMind
每一步都会生成新的样本,并且都会受到此前样本结果的影响,也即每一步的结果都将影响下一步的样本预测,并帮助生成下一步的样本。经过层层处理后,最终输出的声音非常逼真。
PK,WaveNet 效果拔群
在对比测试中,DeepMind 请了英语和汉语的测试人员用各自的母语进行录音,与 Google 目前最优秀的 TTS 系统 Concatenative 和 Parametric 以及 WaveNet 进行对比。
测试结果表明,WaveNet 生成的声音要比 Google 的 TTS 系统更为自然,但与真实的人声仍有差距。
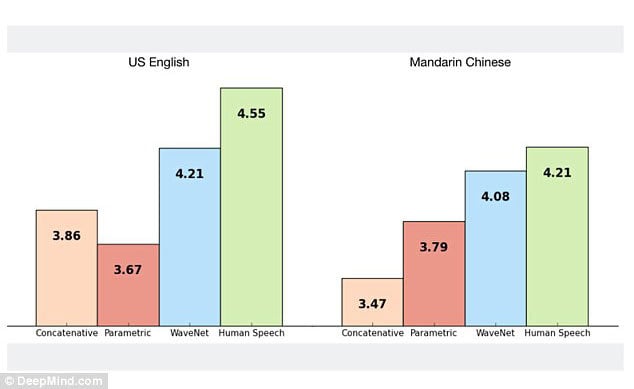
图片来自:DeepMind
这一结果令研究人员兴奋不已,DeepMind 在其博客上表示:
“这种方法能在所有 16 千赫兹的音频上奏效已经足够让人惊喜,更何况还击败了美国最先进的 TTS 系统。”
太贵,WaveNet 暂无法实现商用
除了人类声音,理论上 WaveNet 能模仿任何声音,比如喘息的声音,甚至是音乐,比如钢琴声等。有兴趣的小伙伴可以前往 DeepMind 博客试听。
图片来自:DeepMind
DeepMind 表示:“WaveNet 为 TTS、音乐和音频建模开启了许多可能性。”
事实上,研发人员通常会避免使用 WaveNet 进行建模,因为它每秒钟需要分析 16000 个样本,速度惊人,但也意味着极其高昂的成本,就连 DeepMind 也承认“这是一个巨大的挑战”。
根据彭博社的分析,考虑到成本问题,WaveNet 在短期内无法实现商用。
题图来自:Bloomberg





