






Google 的人工智能击败了人类围棋冠军,这事为什么如此重要?
北京时间 1 月 28 日,Google DeepMind 宣布在人工智能(Artificial Intelligence,以下简称 AI)方面取得重大突破,他们名为 AlphaGo 的人工智能在没有任何让子的情况下以 5:0 完胜欧洲冠军、职业围棋二段樊麾(完整论文点这里)。
这是 AI 第一次在全尺寸(19X19)的棋盘上击败了人类专业选手,在 AlphaGo 之前,业界普遍认为 AI 战胜人类围棋冠军的时间点至少还要等上十年。当下,AlphaGo 借助深度学习技术实现了,描述 AlphaGo 研究成果的论文也成为了 1 月 28 日《自然》杂志的封面文章。

接下来的 3 月份,Google 还会让 AlphaGo 与世界冠军李世乭对战,赢家将获得 Google 提供的 100 万美金。李世乭是最近 10 年中获得世界第一头衔最多的棋手。
AI 战胜围棋为什么比象棋难?
在欧美传统里,棋类游戏被视为顶级人类智力试金石,人工智能挑战棋类大师的好戏也接连上演。
1997 年,IBM 的深蓝在正常时限的比赛中首次击败了当时排名世界第一的棋手加里 · 卡斯帕罗夫。2006 年,人类最后一次打败顶尖的国际象棋 AI。
然而,围棋却一直被视为 AI 的强敌。国际象棋中,平均每回合有 35 种可能,一盘棋可以有 80 回合;而围棋每回合有 250 种可能,一盘棋可以长达 150 回合。同时,围棋有 3^361 种局面,而可观测到的宇宙,原子数量才 10^80。
据卡耐基梅隆大学机器人系博士、Facebook 人工智能组研究员田渊栋解释,围棋难的地方在于它的估值函数非常不平滑,差一个子盘面就可能天翻地覆,同时状态空间大,也没有全局的结构。这两点加起来,迫使目前计算机只能用穷举法并且因此进展缓慢。
在之前围棋 AI 和人类选手的比赛中,人类选手都会让子,而且 AI 主要和业余段位的棋手比赛。而 AlphaGo 这次的对手樊麾是法国国家围棋队总教练,已经连续三年赢得欧洲围棋冠军的称号。
另外,在与其他围棋 AI 的比赛中,AlphaGo 总计 495 局中只输了一局,胜率是 99.8%。
AlphaGo 是如何做到的?
传统的人工智能方法是将所有可能的走法构建成一棵搜索树 ,但这种方法对于走法如此之多的围棋并不适用。AlphaGo 基于 Google 和 DeepMind 一直专研的深度学习技术,将高级搜索树与深度神经网络结合在一起。
深度学习是机器学习的一个分支。机器学习这个概念认为,对于待解问题,无需编写任何专门的程序代码,只需要输入数据,算法会在数据之上建立起它自己的逻辑。深度学习强调的是使用的模型,最流行的是被用在大规模图像识别任务中的卷积神经网络(Convolutional Neural Nets,CNN),简称 ConvNets。
AlphaGo 运用到的深度神经网络是 Policy Network(策略网络)以及 Value Network(值网络)。
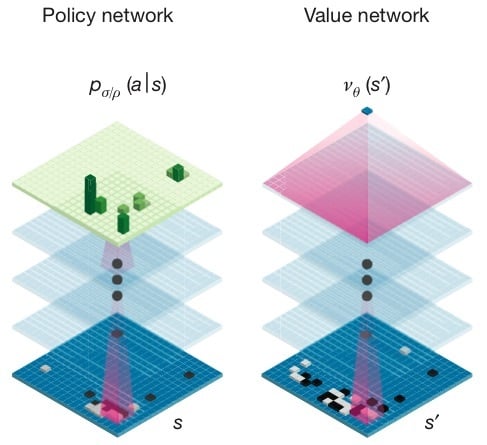
据果壳网作者开明的文章,策略网络和值网络任务在于合作挑选出那些比较有前途的棋步,抛弃明显的差棋,从而将计算量控制在计算机可以完成的范围里,本质上和人类棋手所做的一样。
策略网络负责减少搜索的宽度——面对眼前的一盘棋,有些棋步是明显不该走的,比如不该随便送子给别人吃。这样 AI 就不用给每一步以同样的重视程度,可以重点分析那些有戏的棋着。
值网络负责减少搜索的深度——AI 会一边推算一边判断局面,局面明显劣势的时候,就直接抛弃某些路线,不用一条道算到黑。
更通俗的解释是,策略网络着眼于当下,选择下一步走法。值网络思考得更加长远,预测棋局的走向。
DeepMind 用人类围棋高手的两千万步围棋走法训练 AI,这种方法称为监督学习(supervised learning),然后让 AI 和自己对弈,这个流程称之为强化学习(reinforcement learning)。
征服围棋最重要的意义在于,AlphaGo 不仅是遵循人工规则的 “专家” 系统,它还通过深度学习技术自行掌握了如何赢得围棋比赛。
DeepMind 什么来头?
DeepMind 是一间英国人工智能初创企业,创立之初主要业务是为游戏、电商等服务提供机器学习的智能算法。换句话说,DeepMind 是一家面向商用市场的技术提供商。

创始人 Demis Hassabis(德米斯 · 哈萨比斯)小时候是象棋神童,17 岁就达到了 A-level,比其编程销售过百万的模拟游戏 “主题公园” 的事迹还要早两年。

(Demis Hassabis)
以优异的成绩毕业于剑桥大学计算机系之后,Demis 创立了具有开创性意义的电子游戏公司 Elixir Studios,为全球出版商如 Vivendi Universal 制作了许多获奖游戏。
拥有十年成功的技术创业公司经验后, Demis 重新回到校园,在伦敦大学完成认知神经科学博士学位,并在麻省理工和哈佛大学拿到博士后学位。
2011 年,Demis Hassabis 联合 Shane Legg 以及 Mustafa Suleyman 一同创立了 DeepMind Technologies,专注于机器学习研究。
2014 年 1 月 DeepMind 被 Google 收购,Demis Hassabis 领导 Google 在人工智能方面的全方位工作。
在被 Google 收购后,DeepMind 一直保持低调。2015 年 11 月,DeepMind 发布了几篇关于利用人工智能算法打败 Atari 游戏的论文,获得了不错的反响。
当时,在和伦敦皇家学会的一次视频会议中,与会者问及是否在进行围棋相关研究,Demis Hassabis 透露,我们现在还不能讲太多,但几个月后会有太惊喜。现在看来,这个大惊喜就是 AlphaGo 了。Demis Hassabis 描述道:
围棋是人类发明的最复杂也是最美的游戏。通过战胜樊麾,我们的程序赢得了长期以来一项重大人工智能挑战的胜利。而这项技术在 Google 的首个用途将是开发更好的个人助理软件。这样的个人助理能够从用户在线行为中学习用户偏好,并对产品和事件作出更符合直觉的建议。





